Алгоритмы и структуры данных на JavaScript
![]()
![]()
В этом репозитории содержатся базовые JavaScript-примеры многих популярных алгоритмов и структур данных.
Для каждого алгоритма и структуры данных есть свой файл README с соответствующими пояснениями и ссылками на материалы для дальнейшего изучения (в том числе и ссылки на видеоролики в YouTube).
Читать на других языках: English, 简体中文, 繁體中文, 한국어, 日本語, Polski, Français, Español, Português, Türk, Italiana, Bahasa Indonesia, Українська, Arabic, Tiếng Việt, Deutsch, Uzbek
☝ Замечание: этот репозиторий предназначен для учебно-исследовательских целей (не для использования в продакшн-системах).
Структуры данных
Структура данных (англ. data structure) — программная единица, позволяющая хранить и обрабатывать множество однотипных и/или логически связанных данных в вычислительной технике. Для добавления, поиска, изменения и удаления данных структура данных предоставляет некоторый набор функций, составляющих её интерфейс.
B - Базовый уровень, A - Продвинутый уровень
BСвязный списокBДвунаправленный связный списокBОчередьBСтекBХеш-таблицаBКуча — максимальная и минимальная версииBОчередь с приоритетомAПрефиксное деревоAДеревьяAДвоичное дерево поискаAАВЛ-деревоAКрасно-чёрное деревоAДерево отрезков — для минимума, максимума и суммы отрезковAДерево Фенвика (двоичное индексированное дерево)AГраф (ориентированный и неориентированный)AСистема непересекающихся множествAФильтр Блума
Алгоритмы
Алгоритм — конечная совокупность точно заданных правил решения некоторого класса задач или набор инструкций, описывающих порядок действий исполнителя для решения некоторой задачи.
B - Базовый уровень, A - Продвинутый уровень
Алгоритмы по тематике
- Математика
BБитовые манипуляции — получение/запись/сброс/обновление битов, умножение/деление на 2, сделать отрицательным и т.п.BДвоичное число с плавающей запятой - двоичное представление чисел с плавающей запятойBФакториалBЧисла Фибоначчи — классическое решение, решение в замкнутой формеBПростые множители - нахождение простых множителей и их подсчёт с использованием теоремы Харди-РамануджанаBТест простоты (метод пробного деления)BАлгоритм Евклида — нахождение наибольшего общего делителя (НОД)BНаименьшее общее кратное (НОК)BРешето Эратосфена — нахождение всех простых чисел до некоторого целого числа nBСтепень двойки — является ли число степенью двойки (простое и побитовое решения)BТреугольник ПаскаляBКомплексные числа — комплексные числа, базовые операции над нимиBРадианы и градусы — конвертирование радианов в градусы и наоборотBБыстрое возведение в степеньBСхема Горнера - оценка полиномовBМатрицы - матрицы и основные операции с матрицами (умножение, транспонирование и т.д.)BЕвклидово расстояние - расстояние между двумя точками/векторами/матрицамиAРазбиение числаAКвадратный корень — метод НьютонаAАлгоритм Лю Хуэя — расчёт числа π с заданной точностью методом вписанных правильных многоугольниковAДискретное преобразование Фурье — разложение временной функции (сигнала) на частотные составляющие- Множества
BДекартово произведение — результат перемножения множествBТасование Фишера — Йетса — создание случайных перестановок конечного множестваAБулеан — все подмножества заданного множества (побитовый поиск и поиск с возвратом)AПерестановки (с повторениями и без повторений)AСочетания (с повторениями и без повторений)AНаибольшая общая подпоследовательностьAНаибольшая увеличивающаяся подпоследовательностьAНаименьшая общая супер-последовательностьAЗадача о рюкзаке — "0/1" и "неограниченный" рюкзакиAМаксимальный под-массив — метод полного перебора и алгоритм КаданеAКомбинации сумм — нахождение всех комбинаций, сумма каждой из которых равна заданному числу- Алгоритмы работы со строками
BРасстояние Хэмминга — число позиций, в которых соответствующие символы различныAРасстояние Левенштейна — метрика, измеряющая разность между двумя последовательностямиAАлгоритм Кнута — Морриса — Пратта — поиск подстроки (сопоставление с шаблоном)AZ-функция — поиск подстроки (сопоставление с шаблоном)AАлгоритм Рабина — Карпа — поиск подстрокиAНаибольшая общая подстрокаAРазборщик регулярных выражений- Алгоритмы поиска
BЛинейный поискBПоиск с перескоком (поиск блоков) — поиск в упорядоченном массивеBДвоичный поиск — поиск в упорядоченном массивеBИнтерполяционный поиск — поиск в равномерно распределённом упорядоченном массиве.- Алгоритмы сортировки
BСортировка пузырькомBСортировка выборомBСортировка вставкамиBПирамидальная сортировка (сортировка кучей)BСортировка слияниемBБыстрая сортировка — с использованием дополнительной памяти и без её использованияBСортировка ШеллаBСортировка подсчётомBПоразрядная сортировка- Связный список
BПрямой обходBОбратный обход- Деревья
BПоиск в глубинуBПоиск в ширину- Графы
BПоиск в глубинуBПоиск в ширинуBАлгоритм Краскала — нахождение минимального остовного дерева для взвешенного неориентированного графаAАлгоритм Дейкстры — нахождение кратчайших путей от одной из вершин графа до всех остальныхAАлгоритм Беллмана — Форда — нахождение кратчайших путей от одной из вершин графа до всех остальныхAАлгоритм Флойда — Уоршелла — нахождение кратчайших расстояний между всеми вершинами графаAЗадача нахождения цикла — для ориентированных и неориентированных графов (на основе поиска в глубину и системы непересекающихся множеств)AАлгоритм Прима — нахождение минимального остовного дерева для взвешенного неориентированного графаAТопологическая сортировка — на основе поиска в глубинуAШарниры (разделяющие вершины) — алгоритм Тарьяна (на основе поиска в глубину)AМосты — на основе поиска в глубинуAЭйлеров путь и Эйлеров цикл — алгоритм Флёри (однократное посещение каждой вершины)AГамильтонов цикл — проходит через каждую вершину графа ровно один разAКомпоненты сильной связности — алгоритм КосарайюAЗадача коммивояжёра — кратчайший маршрут, проходящий через указанные города с последующим возвратом в исходный город- Криптография
BПолиноминальный хэш — функция кольцевого хэша, основанная на полиномеBШифр ограждения рельсов - алгоритм транспозиционного шифра для кодирования сообщенийBШифр Цезаря - простой подстановочный шифрBШифр Хилла - подстановочный шифр на основе линейной алгебры- Машинное обучение
BНано-нейрон — 7 простых JavaScript функций, отображающих способности машины к обучению (прямое и обратное распространение)Bk-NN - алгоритм классификации k-ближайших соседейBk-Means - алгоритм кластеризации по методу k-средних- Обработка изображений
BРезьба по шву - алгоритм изменения размера изображения с учетом содержания- Статистика
BВзвешенная случайность - выбор случайного элемента из списка на основе веса элементов- Эволюционные алгоритмы
AГенетический алгоритм - пример применения генетического алгоритма для обучения самопаркующихся автомобилей- Прочие алгоритмы
BХанойская башняBПоворот квадратной матрицы — используется дополнительная памятьBПрыжки — на основе бэктрекинга, динамического программирования (сверху-вниз + снизу-вверх) и жадных алгоритмовBПоиск уникальных путей — на основе бэктрекинга, динамического программирования и треугольника ПаскаляBПодсчёт дождевой воды — на основе перебора и динамического программированияBЗадача о рекурсивной лестнице — подсчёт количества путей, по которым можно достичь верха лестницы (4 способа)BЛучшее время для покупки и продажи акций - примеры "разделяй и властвуй" и в один проходAЗадача об N ферзяхAМаршрут коня
Алгоритмы по парадигме программирования
Парадигма программирования — общий метод или подход, лежащий в основе целого класса алгоритмов. Понятие "парадигма программирования" является более абстрактным по отношению к понятию "алгоритм", которое в свою очередь является более абстрактным по отношению к понятию "компьютерная программа".
- Алгоритмы полного перебора — поиск лучшего решения исчерпыванием всевозможных вариантов
BЛинейный поискBПодсчёт дождевой водыBЗадача о рекурсивной лестнице — подсчёт количества путей, по которым можно достичь верха лестницыAМаксимальный подмассивAЗадача коммивояжёра — кратчайший маршрут, проходящий через указанные города с последующим возвратом в исходный городAДискретное преобразование Фурье — разложение временной функции (сигнала) на частотные составляющие- Жадные алгоритмы — принятие локально оптимальных решений с учётом допущения об оптимальности конечного решения
BПрыжкиAЗадача о неограниченном рюкзакеAАлгоритм Дейкстры — нахождение кратчайших путей от одной из вершин графа до всех остальныхAАлгоритм Прима — нахождение минимального остовного дерева для взвешенного неориентированного графаAАлгоритм Краскала — нахождение минимального остовного дерева для взвешенного неориентированного графа- Разделяй и властвуй — рекурсивное разбиение решаемой задачи на более мелкие
BДвоичный поискBХанойская башняBТреугольник ПаскаляBАлгоритм Евклида — нахождение наибольшего общего делителя (НОД)BСортировка слияниемBБыстрая сортировкаBПоиск в глубину (дерево)BПоиск в глубину (граф)BМатрицы - генерирование и обход матриц различной формыBПрыжкиBБыстрое возведение в степеньBЛучшее время для покупки и продажи акций - примеры "разделяй и властвуй" и в один проходAПерестановки (с повторениями и без повторений)AСочетания (с повторениями и без повторений)- Динамическое программирование — решение общей задачи конструируется на основе ранее найденных решений подзадач
BЧисла ФибоначчиBПрыжкиBПоиск уникальных путейBПодсчёт дождевой водыBЗадача о рекурсивной лестнице — подсчёт количества путей, по которым можно достичь верха лестницыBРезьба по шву - алгоритм изменения размера изображения с учетом содержанияAРасстояние Левенштейна — метрика, измеряющая разность между двумя последовательностямиAНаибольшая общая подпоследовательностьAНаибольшая общая подстрокаAНаибольшая увеличивающаяся подпоследовательностьAНаименьшая общая суперпоследовательностьAРюкзак 0-1AРазбиение числаAМаксимальный подмассивAАлгоритм Беллмана — Форда — поиск кратчайшего пути во взвешенном графеAАлгоритм Флойда — Уоршелла — нахождение кратчайших путей от одной из вершин графа до всех остальныхAРазборщик регулярных выражений- Поиск с возвратом (бэктрекинг) — при поиске решения многократно делается попытка расширить текущее частичное решение. Если расширение невозможно, то происходит возврат к предыдущему более короткому частичному решению, и делается попытка его расширить другим возможным способом. Обычно используется обход пространства состояний в глубину.
BПрыжкиBПоиск уникальных путейBБулеан — все подмножества заданного множестваAГамильтонов цикл — проходит через каждую вершину графа ровно один разAЗадача об N ферзяхAМаршрут коняAКомбинации сумм — нахождение всех комбинаций, сумма каждой из которых равна заданному числу- Метод ветвей и границ — основан на упорядоченном переборе решений и рассмотрении только тех из них, которые являются перспективными (по тем или иным признакам) и отбрасывании бесперспективных множеств решений. Обычно используется обход в ширину в совокупности с обходом дерева пространства состояний в глубину.
Как использовать этот репозиторий
Установка всех зависимостей
npm install
Запуск ESLint
Эта команда может потребоваться вам для проверки качества кода.
npm run lint
Запуск всех тестов
npm test
Запуск определённого теста
npm test -- 'LinkedList'
Песочница
Вы можете экспериментировать с алгоритмами и структурами данных в файле ./src/playground/playground.js
(файл ./src/playground/__test__/playground.test.js предназначен для написания тестов).
Для проверки работоспособности вашего кода используйте команду:
npm test -- 'playground'
Полезная информация
Ссылки
▶ О структурах данных и алгоритмах
Нотация «О» большое
Нотация «О» большое используется для классификации алгоритмов в соответствии с ростом времени выполнения и затрачиваемой памяти при увеличении размера входных данных. На диаграмме ниже представлены общие порядки роста алгоритмов в соответствии с нотацией «О» большое.
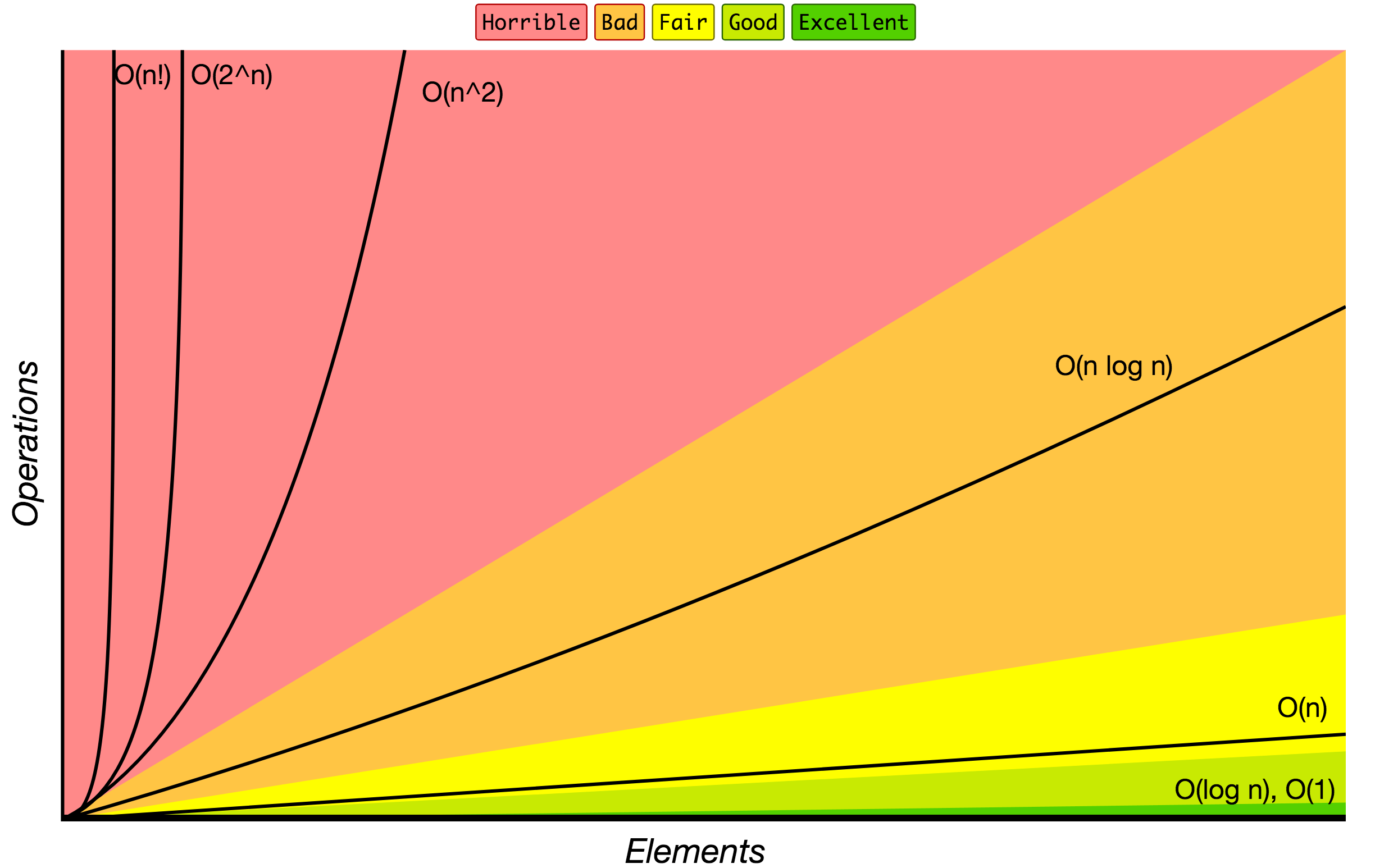
Источник: Big O Cheat Sheet.
Ниже представлены часто используемые обозначения в нотации «О» большое, а также сравнение их производительностей на различных размерах входных данных.
| Нотация «О» большое | 10 элементов | 100 элементов | 1000 элементов |
|---|---|---|---|
| O(1) | 1 | 1 | 1 |
| O(log N) | 3 | 6 | 9 |
| O(N) | 10 | 100 | 1000 |
| O(N log N) | 30 | 600 | 9000 |
| O(N^2) | 100 | 10000 | 1000000 |
| O(2^N) | 1024 | 1.26e+29 | 1.07e+301 |
| O(N!) | 3628800 | 9.3e+157 | 4.02e+2567 |
Сложности операций в структурах данных
| Структура данных | Получение | Поиск | Вставка | Удаление | Комментарии |
|---|---|---|---|---|---|
| Массив | 1 | n | n | n | |
| Стек | n | n | 1 | 1 | |
| Очередь | n | n | 1 | 1 | |
| Связный список | n | n | 1 | n | |
| Хеш-таблица | - | n | n | n | Для идеальной хеш-функции — O(1) |
| Двоичное дерево поиска | n | n | n | n | В сбалансированном дереве — O(log(n)) |
| B-дерево | log(n) | log(n) | log(n) | log(n) | |
| Красно-чёрное дерево | log(n) | log(n) | log(n) | log(n) | |
| АВЛ-дерево | log(n) | log(n) | log(n) | log(n) | |
| Фильтр Блума | - | 1 | 1 | - | Возможно получение ложно-положительного срабатывания |
Сложности алгоритмов сортировки
| Наименование | Лучший случай | Средний случай | Худший случай | Память | Устойчивость | Комментарии |
|---|---|---|---|---|---|---|
| Сортировка пузырьком | n | n2 | n2 | 1 | Да | |
| Сортировка вставками | n | n2 | n2 | 1 | Да | |
| Сортировка выбором | n2 | n2 | n2 | 1 | Нет | |
| Сортировка кучей | n log(n) | n log(n) | n log(n) | 1 | Нет | |
| Сортировка слиянием | n log(n) | n log(n) | n log(n) | n | Да | |
| Быстрая сортировка | n log(n) | n log(n) | n2 | log(n) | Нет | Быстрая сортировка обычно выполняется с использованием O(log(n)) дополнительной памяти |
| Сортировка Шелла | n log(n) | зависит от выбранных шагов | n (log(n))2 | 1 | Нет | |
| Сортировка подсчётом | n + r | n + r | n + r | n + r | Да | r — наибольшее число в массиве |
| Поразрядная сортировка | n * k | n * k | n * k | n + k | Да | k — длина самого длинного ключа |
ℹ️ A few more projects and articles about JavaScript and algorithms on trekhleb.dev