JavaScriptアルゴリズムとデータ構造
![]()
![]()
このリポジトリには、JavaScriptベースの一般的なアルゴリズムとデータ構造に関する多数のサンプルが含まれています。
各アルゴリズムとデータ構造には独自のREADMEがあります。 関連する説明、そして参考資料 (YouTube動画)も含まれています。
Read this in other languages: English, 简体中文, 繁體中文, 한국어, Polski, Français, Español, Português, Русский, Türk, Italiana, Bahasa Indonesia, Українська, Arabic, Tiếng Việt, Deutsch, Uzbek
データ構造
データ構造は、データ値、データ値との間の関係、 そして、データを扱うことができる関数と演算の集合で、 データを特定の方法で構成して保存することで、より効率的に アクセスして変更することができます。
B - 初心者, A - 上級
BリンクされたリストB二重リンクリストBキューBスタックBハッシュ表Bヒープ - max and min heap versionsB優先度キューAトライAツリーAバイナリ検索ツリーAAVLツリーA赤黒のツリーAセグメントツリー - with min/max/sum range queries examplesAフェンウィック・ツリー (Binary Indexed Tree)Aグラフ (both directed and undirected)A分離集合Aブルームフィルタ
アルゴリズム
アルゴリズムとは、問題のクラスをどのように解決するかの明確な仕様です。 一連の操作を正確に定義する一連のルールです。
B - 初心者, A - 上級
トピック別アルゴリズム
- 数学
Bビット操作 - set/get/update/clear bits, 2つの乗算/除算, 否定的にする. 等B因果関係Bフィボナッチ数 - クラシックとクローズドフォームのバージョンB素数性テスト (trial division 方法)Bユークリッドアルゴリズム - 最大公約数を計算する (GCD)B最小公倍数 (LCM)Bエラトステネスのふるい - 与えられた限度まですべての素数を見つけるBIs Power of Two - 数値が2の累乗であるかどうかを調べる(単純なアルゴリズムとビットごとのアルゴリズム)Bパスカルの三角形B複素数 - 複素数とその基本演算Bラジアン&度 - 度数と逆方向の変換に対するラジアンB高速電力供給A整数パーティションALiu Hui π アルゴリズム - N-gonsに基づく近似π計算A離散フーリエ変換 - 時間(信号)の関数をそれを構成する周波数に分解する- セット
Bデカルト積 - 複数の積の積BFisher–Yates Shuffle - 有限シーケンスのランダム置換Aパワーセット - セットのすべてのサブセット(ビットごとのソリューションとバックトラッキングソリューション)A順列 (繰り返しの有無にかかわらず)A組み合わせ (繰返しあり、繰返しなし)A最長共通部分列 (LCS)A最長増加サブシーケンスA最短共通スーパーシーケンス (SCS)Aナップザック問題 - 「0/1」と「非結合」問題A最大サブアレイ - 「ブルートフォース」と「ダイナミックプログラミング」(Kadane's版)A組み合わせ合計 - 特定の合計を構成するすべての組み合わせを見つける- 文字列
Bハミング距離 - シンボルが異なる位置の数Aレーベンシュタイン距離 - 2つのシーケンス間の最小編集距離AKnuth-Morris-Prattアルゴリズム (KMP Algorithm) - 部分文字列検索 (pattern matching)AZ アルゴリズム - 部分文字列検索 (pattern matching)ARabin Karpアルゴリズム - 部分文字列検索A最長共通部分文字列A正規表現マッチング- 検索
BリニアサーチBジャンプ検索 (Jump Search) - ソートされた配列で検索Bバイナリ検索 - ソートされた配列で検索B補間探索 - 一様分布のソート配列で検索する- 並べ替え
BバブルソートB選択ソートB挿入ソートBヒープソートBマージソートBクイックソート -インプレースおよび非インプレース・インプリメンテーションBシェルソートB並べ替えを数えるB基数ソート- リンクされたリスト
BストレートトラバーサルB逆方向のトラバーサル- ツリー
B深度優先検索 (DFS)B幅優先検索 (BFS)- グラフ
B深度優先検索 (DFS)B幅優先検索 (BFS)BKruskalのアルゴリズム - 重み付き無向グラフの最小スパニングツリー(MST)の発見ADijkstraアルゴリズム - 単一の頂点からすべてのグラフ頂点への最短経路を見つけるABellman-Fordアルゴリズム - 単一の頂点からすべてのグラフ頂点への最短経路を見つけるAFloyd-Warshallアルゴリズム - すべての頂点ペア間の最短経路を見つけるADetect Cycle - 有向グラフと無向グラフの両方(DFSおよびディスジョイントセットベースのバージョン)Aプリムのアルゴリズム - 重み付き無向グラフの最小スパニングツリー(MST)の発見Aトポロジカルソート - DFSメソッドAアーティキュレーションポイント - Tarjanのアルゴリズム(DFSベース)Aブリッジ - DFSベースのアルゴリズムAオイラーパスとオイラー回路 - フルリーアルゴリズム - すべてのエッジを正確に1回訪問するAハミルトニアンサイクル - すべての頂点を正確に1回訪問するA強連結成分 - コサラジュのアルゴリズムAトラベリングセールスマン問題 - 各都市を訪問し、起点都市に戻る最短経路- 暗号
B多項式ハッシュ - 関数多項式に基づくハッシュ関数- 未分類
Bハノイの塔B正方行列回転 - インプレイスアルゴリズムBジャンプゲーム - バックトラック、ダイナミックプログラミング(トップダウン+ボトムアップ)、欲張りの例Bユニークなパス - バックトラック、動的プログラミング、PascalのTriangleベースの例Bレインテラス - トラップ雨水問題(ダイナミックプログラミングとブルートフォースバージョン)B再帰的階段 - 上に到達する方法の数を数える(4つのソリューション)AN-クイーンズ問題Aナイトツアー
Paradigmによるアルゴリズム
アルゴリズムパラダイムは、あるクラスのアルゴリズムの設計の基礎をなす一般的な方法またはアプローチである。それは、アルゴリズムがコンピュータプログラムよりも高い抽象であるのと同様に、アルゴリズムの概念よりも高い抽象である。
* ブルートフォース - すべての可能性を見て最適なソリューションを選択する
* B 線形探索
* B レインテラス - 雨水問題
* B Recursive Staircase - 先頭に到達する方法の数を数えます
* A 最大サブアレイ
* A 旅行セールスマン問題 - 各都市を訪れ、起点都市に戻る最短ルート
* A 離散フーリエ変換 - 時間(信号)の関数をそれを構成する周波数に分解する
* 欲張り - 未来を考慮することなく、現時点で最適なオプションを選択する
* B ジャンプゲーム
* A 結合されていないナップザック問題
* A Dijkstra Algorithm - すべてのグラフ頂点への最短経路を見つける
* A Prim’s Algorithm - 重み付き無向グラフの最小スパニングツリー(MST)を見つける
* A Kruskalのアルゴリズム - 重み付き無向グラフの最小スパニングツリー(MST)を見つける
* 分割と征服 - 問題をより小さな部分に分割し、それらの部分を解決する
* B バイナリ検索
* B ハノイの塔
* B パスカルの三角形
* B ユークリッドアルゴリズム - GCD(Greatest Common Divisor)を計算する
* B マージソート
* B クイックソート
* B ツリーの深さ優先検索 (DFS)
* B グラフの深さ優先検索 (DFS)
* B ジャンプゲーム
* B 高速電力供給
* A 順列 (繰り返しの有無にかかわらず)
* A 組み合わせ(繰返しあり、繰返しなし)
* 動的プログラミング - 以前に発見されたサブソリューションを使用してソリューションを構築する
* B フィボナッチ数
* B ジャンプゲーム
* B ユニークなパス
* B 雨テラス - トラップ雨水問題
* B 再帰的階段 - 上に到達する方法の数を数える
* A Levenshtein Distance - 2つのシーケンス間の最小編集距離
* A 最長共通部分列 (LCS)
* A 最長共通部分文字列
* A 最長増加サブシーケンス
* A 最短共通共通配列
* A 0/1ナップザック問題
* A 整数パーティション
* A 最大サブアレイ
* A Bellman-Fordアルゴリズム - すべてのグラフ頂点への最短経路を見つける
* A Floyd-Warshallアルゴリズム - すべての頂点ペア間の最短経路を見つける
* A 正規表現マッチング
* バックトラッキング - ブルートフォースと同様に、可能なすべてのソリューションを生成しようとしますが、
次のソリューションを生成するたびにすべての条件を満たすかどうかをテストし、それ以降は引き続きソリューションを生成します。
それ以外の場合は、バックトラックして、解決策を見つける別の経路に進みます。
通常、状態空間のDFSトラバーサルが使用されています。
* B ジャンプゲーム
* B ユニークなパス
* B パワーセット - セットのすべてのサブセット
* A ハミルトニアンサイクル - すべての頂点を正確に1回訪問する
* A N-クイーンズ問題
* A ナイトツアー
* A 組み合わせ合計 - 特定の合計を構成するすべての組み合わせを見つける
* ブランチ&バウンド - バックトラック検索の各段階で見つかった最もコストの低いソリューションを覚えておいて、最もコストの低いソリューションのコストを使用します。これまでに発見された最もコストの低いソリューションよりも大きなコストで部分ソリューションを破棄するように指示します。通常、状態空間ツリーのDFSトラバーサルと組み合わせたBFSトラバーサルが使用されています。
このリポジトリの使い方
すべての依存関係をインストールする
npm install
ESLintを実行する
これを実行してコードの品質をチェックすることができます。
npm run lint
すべてのテストを実行する
npm test
名前でテストを実行する
npm test -- 'LinkedList'
playground
データ構造とアルゴリズムを ./src/playground/playground.js ファイルで再生し、
それに対するテストを書くことができ ./src/playground/__test__/playground.test.js.
次に、次のコマンドを実行して、遊び場コードが正常に動作するかどうかをテストします。
npm test -- 'playground'
有用な情報
参考文献
ビッグO表記
Big O表記法は 入力サイズが大きくなるにつれて実行時間やスペース要件がどのように増加するかに応じてアルゴリズムを分類するために使用されます。下のチャートでは、Big O表記で指定されたアルゴリズムの成長の最も一般的な順序を見つけることができます。
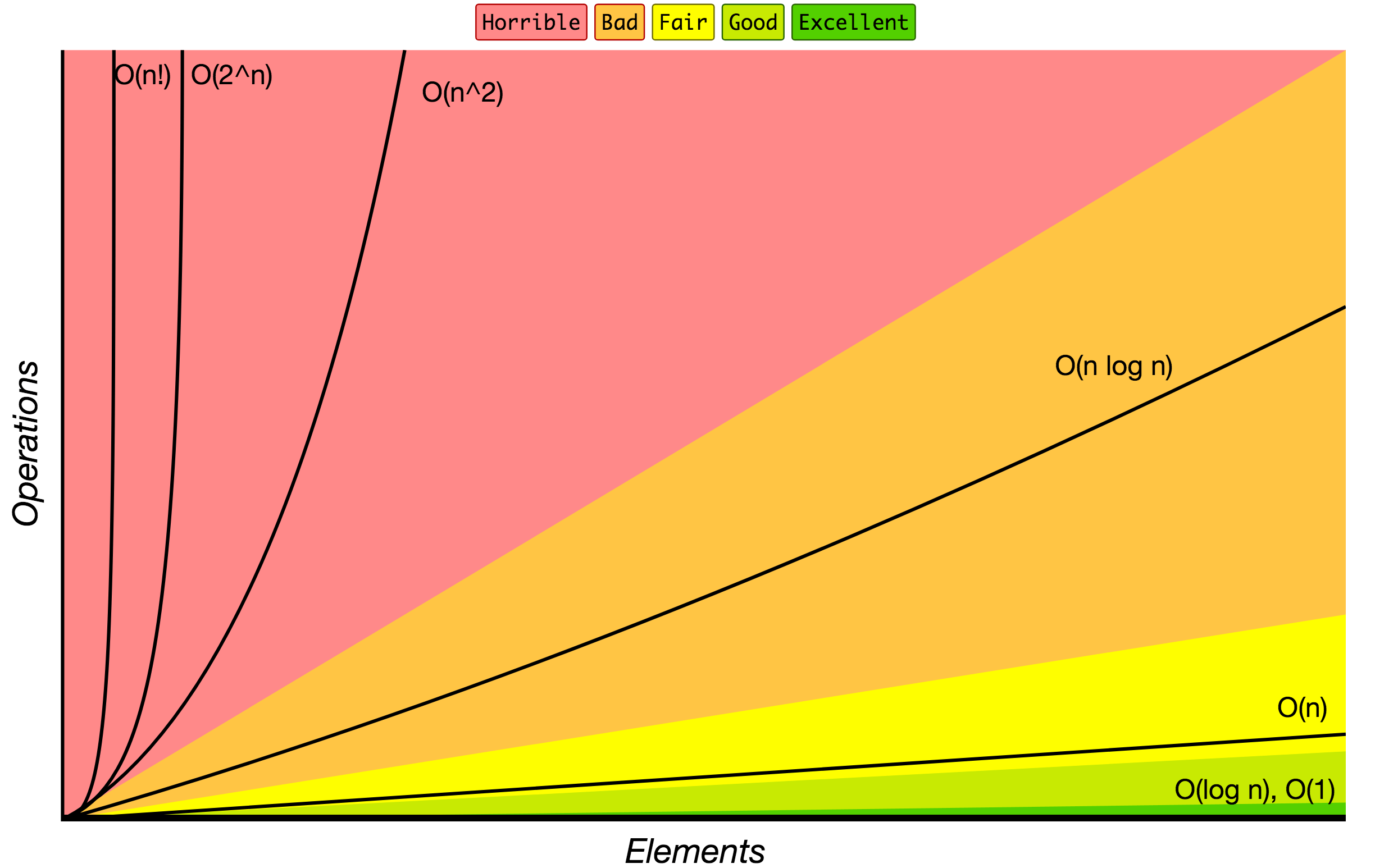
出典: Big Oチートシート.
以下は、最も使用されているBig O表記のリストと、入力データのさまざまなサイズに対するパフォーマンス比較です。
| Big O Notation | Computations for 10 elements | Computations for 100 elements | Computations for 1000 elements |
|---|---|---|---|
| O(1) | 1 | 1 | 1 |
| O(log N) | 3 | 6 | 9 |
| O(N) | 10 | 100 | 1000 |
| O(N log N) | 30 | 600 | 9000 |
| O(N^2) | 100 | 10000 | 1000000 |
| O(2^N) | 1024 | 1.26e+29 | 1.07e+301 |
| O(N!) | 3628800 | 9.3e+157 | 4.02e+2567 |
データ構造操作の複雑さ
| Data Structure | Access | Search | Insertion | Deletion | Comments |
|---|---|---|---|---|---|
| Array | 1 | n | n | n | |
| Stack | n | n | 1 | 1 | |
| Queue | n | n | 1 | 1 | |
| Linked List | n | n | 1 | 1 | |
| Hash Table | - | n | n | n | In case of perfect hash function costs would be O(1) |
| Binary Search Tree | n | n | n | n | In case of balanced tree costs would be O(log(n)) |
| B-Tree | log(n) | log(n) | log(n) | log(n) | |
| Red-Black Tree | log(n) | log(n) | log(n) | log(n) | |
| AVL Tree | log(n) | log(n) | log(n) | log(n) | |
| Bloom Filter | - | 1 | 1 | - | False positives are possible while searching |
配列の並べ替えアルゴリズムの複雑さ
| Name | Best | Average | Worst | Memory | Stable | Comments |
|---|---|---|---|---|---|---|
| Bubble sort | n | n2 | n2 | 1 | Yes | |
| Insertion sort | n | n2 | n2 | 1 | Yes | |
| Selection sort | n2 | n2 | n2 | 1 | No | |
| Heap sort | n log(n) | n log(n) | n log(n) | 1 | No | |
| Merge sort | n log(n) | n log(n) | n log(n) | n | Yes | |
| Quick sort | n log(n) | n log(n) | n2 | log(n) | No | Quicksort is usually done in-place with O(log(n)) stack space |
| Shell sort | n log(n) | depends on gap sequence | n (log(n))2 | 1 | No | |
| Counting sort | n + r | n + r | n + r | n + r | Yes | r - biggest number in array |
| Radix sort | n * k | n * k | n * k | n + k | Yes | k - length of longest key |
ℹ️ A few more projects and articles about JavaScript and algorithms on trekhleb.dev