JavaScript-Algorithmen und Datenstrukturen
![]()
![]()
Dieses Repository enthält JavaScript Beispiele für viele gängige Algorithmen und Datenstrukturen.
Jeder Algorithmus und jede Datenstruktur hat eine eigene README mit zugehörigen Erklärungen und weiterführenden Links (einschließlich zu YouTube-Videos).
Lies dies in anderen Sprachen: English 简体中文, 繁體中文, 한국어, 日本語, Polski, Français, Español, Português, Русский, Türk, Italiana, Bahasa Indonesia, Українська, Arabic, Uzbek
☝ Beachte, dass dieses Projekt nur für Lern- und Forschungszwecke gedacht ist und nicht für den produktiven Einsatz verwendet werden soll
Datenstrukturen
Eine Datenstruktur ist eine bestimmte Art und Weise, Daten in einem Computer so zu organisieren und zu speichern, dass sie effizient erreicht und verändert werden können. Genauer gesagt, ist eine Datenstruktur eine Sammlung von Werten, den Beziehungen zwischen ihnen und den Funktionen oder Operationen, die auf die Daten angewendet werden können.
B - Anfänger:innen, A - Fortgeschrittene
BVerkettete Liste (Linked List)BDoppelt verkettete Liste (Doubly Linked List)BWarteschlange (Queue)BStapelspeicher (Stack)BHashtabelle (Hash Table)BHeap-Algorithmus (Heap) - max und min Heap-VersionenBVorrangwarteschlange (Priority Queue)ATrie (Trie)ABaum (Tree)ABinärer Suchbaum (Binary Search Tree)AAVL-Baum (AVL Tree)ARot-Schwarz-Baum (Red-Black Tree)ASegment-Baum (Segment Tree) - mit Min/Max/Summenbereich-Abfrage BeispielAFenwick Baum (Fenwick Tree) (Binär indizierter Baum / Binary Indexed Tree)AGraph (Graph) (sowohl gerichtet als auch ungerichtet)AUnion-Find-Struktur (Disjoint Set)ABloomfilter (Bloom Filter)
Algorithmen
Ein Algorithmus ist eine eindeutige Spezifikation, wie eine Klasse von Problemen zu lösen ist. Er besteht aus einem Satz von Regeln, die eine Abfolge von Operationen genau definieren.
B - Anfänger:innen, A - Fortgeschrittene
Algorithmen nach Thema
- Mathe
BBitmanipulation (Bit Manipulation) - Bits setzen/lesen/aktualisieren/löschen, Multiplikation/Division durch zwei negieren usw..BFaktoriell (Factorial)BFibonacci-Zahl (Fibonacci Number) - Klassische und geschlossene VersionBPrimfaktoren (Prime Factors) - Auffinden von Primfaktoren und deren Zählung mit Hilfe des Satz von Hardy-Ramanujan (Hardy-Ramanujan's theorem)BPrimzahl-Test (Primality Test) (Probedivision / trial division method)BEuklidischer Algorithmus (Euclidean Algorithm) - Berechnen des größten gemeinsamen Teilers (ggT)BKleinstes gemeinsames Vielfaches (Least Common Multiple) (kgV)BSieb des Eratosthenes (Sieve of Eratosthenes) - Finden aller Primzahlen bis zu einer bestimmten GrenzeBPower of two (Is Power of Two) - Prüft, ob die Zahl eine Zweierpotenz ist (naive und bitweise Algorithmen)BPascalsches Dreieck (Pascal's Triangle)BKomplexe Zahlen (Complex Number) - Komplexe Zahlen und Grundoperationen mit ihnenBBogenmaß & Grad (Radian & Degree) - Umrechnung von Bogenmaß in Grad und zurückBFast Powering Algorithmus (Fast Powering)BHorner-Schema (Horner's method) - PolynomauswertungBMatrizen (Matrices) - Matrizen und grundlegende Matrixoperationen (Multiplikation, Transposition usw.)BEuklidischer Abstand (Euclidean Distance) - Abstand zwischen zwei Punkten/Vektoren/MatrizenAGanzzahlige Partitionierung (Integer Partition)AQuadratwurzel (Square Root) - Newtonverfahren (Newton's method)ALiu Hui π Algorithmus (Liu Hui π Algorithm) - Näherungsweise π-Berechnungen auf Basis von N-gonsADiskrete Fourier-Transformation (Discrete Fourier Transform) - Eine Funktion der Zeit (ein Signal) in die Frequenzen zerlegen, aus denen sie sich zusammensetzt- Sets
BKartesisches Produkt (Cartesian Product) - Produkt aus mehreren MengenBFisher-Yates-Verfahren (Fisher–Yates Shuffle) - Zufällige Permutation einer endlichen FolgeAPotenzmenge (Power Set) - Alle Teilmengen einer Menge (Bitweise und Rücksetzverfahren Lösungen(backtracking solutions))APermutation (Permutations) (mit und ohne Wiederholungen)AKombination (Combinations) (mit und ohne Wiederholungen)AProblem der längsten gemeinsamen Teilsequenz (Longest Common Subsequence) (LCS)ALängste gemeinsame Teilsequenz (Longest Increasing Subsequence)ADer kürzeste gemeinsame String (Shortest Common Supersequence) (SCS)ARucksackproblem (Knapsack Problem) - "0/1" und "Ungebunden"ADas Maximum-Subarray Problem (Maximum Subarray) - "Brute-Force-Methode" und "Dynamische Programmierung" (Kadane' Algorithmus)AKombinationssumme (Combination Sum) - Alle Kombinationen finden, die eine bestimmte Summe bilden- Zeichenketten (Strings)
BHamming-Abstand (Hamming Distance) - Anzahl der Positionen, an denen die Symbole unterschiedlich sindALevenshtein-Distanz (Levenshtein Distance) - Minimaler Editierabstand zwischen zwei SequenzenAKnuth-Morris-Pratt-Algorithmus (Knuth–Morris–Pratt Algorithm) (KMP Algorithmus) - Teilstringsuche (Mustervergleich / Pattern Matching)AZ-Algorithmus (Z Algorithm) - Teilstringsuche (Mustervergleich / Pattern Matching)ARabin-Karp-Algorithmus (Rabin Karp Algorithm) - TeilstringsucheALängstes häufiges Teilzeichenfolgenproblem (Longest Common Substring)ARegulärer Ausdruck (Regular Expression Matching)- Suchen
BLineare Suche (Linear Search)BSprungsuche (Jump Search) (oder Blocksuche) - Suche im sortierten ArrayBBinäre Suche (Binary Search) - Suche in einem sortierten ArrayBInterpolationssuche (Interpolation Search) - Suche in gleichmäßig verteilt sortiertem Array- Sortieren
BBubblesort (Bubble Sort)BSelectionsort (Selection Sort)BEinfügesortierenmethode (Insertion Sort)BHaldensortierung (Heap Sort)BMergesort (Merge Sort)BQuicksort (Quicksort) - in-place und non-in-place ImplementierungenBShellsort (Shellsort)BCountingsort (Counting Sort)BFachverteilen (Radix Sort)- Verkettete Liste (Linked List)
BGerade Traversierung (Straight Traversal)BUmgekehrte Traversierung (Reverse Traversal)- Bäume
BTiefensuche (Depth-First Search) (DFS)BBreitensuche (Breadth-First Search) (BFS)- Graphen
BTiefensuche (Depth-First Search) (DFS)BBreitensuche (Breadth-First Search) (BFS)BAlgorithmus von Kruskal (Kruskal’s Algorithm) - Finden des Spannbaum (Minimum Spanning Tree / MST) für einen gewichteten ungerichteten GraphenADijkstra-Algorithmus (Dijkstra Algorithm) - Finden der kürzesten Wege zu allen Knoten des Graphen von einem einzelnen Knotenpunkt ausABellman-Ford-Algorithmus (Bellman-Ford Algorithm) - Finden der kürzesten Wege zu allen Knoten des Graphen von einem einzelnen Knotenpunkt ausAAlgorithmus von Floyd und Warshall (Floyd-Warshall Algorithm) - Die kürzesten Wege zwischen allen Knotenpaaren findenAZykluserkennung (Detect Cycle) - Sowohl für gerichtete als auch für ungerichtete Graphen (DFS- und Disjoint-Set-basierte Versionen)AAlgorithmus von Prim (Prim’s Algorithm) - Finden des Spannbaums (Minimum Spanning Tree / MST) für einen gewichteten ungerichteten GraphenATopologische Sortierung (Topological Sorting) - DFS-VerfahrenAArtikulationspunkte (Articulation Points) - Algorithmus von Tarjan (Tarjan's algorithm) (DFS basiert)ABrücke (Bridges) - DFS-basierter AlgorithmusAEulerkreisproblem (Eulerian Path and Eulerian Circuit) - Algorithmus von Fleury (Fleury's algorithm) - Jede Kante genau einmal durchlaufen.AHamiltonkreisproblem (Hamiltonian Cycle) - Jeden Eckpunkt genau einmal durchlaufen.AStarke Zusammenhangskomponente (Strongly Connected Components) - Kosarajus AlgorithmusAProblem des Handlungsreisenden (Travelling Salesman Problem) - Kürzestmögliche Route, die jede Stadt besucht und zur Ausgangsstadt zurückkehrt- Kryptographie
BPolynomiale Streuwertfunktion(Polynomial Hash) - Rollierende Streuwert-Funktion basierend auf PolynomBSchienenzaun Chiffre (Rail Fence Cipher) - Ein Transpositionsalgorithmus zur Verschlüsselung von NachrichtenBCaesar-Verschlüsselung (Caesar Cipher) - Einfache Substitutions-ChiffreBHill-Chiffre (Hill Cipher) - Substitutionschiffre basierend auf linearer Algebra- Maschinelles Lernen
BKünstliches Neuron (NanoNeuron) - 7 einfache JS-Funktionen, die veranschaulichen, wie Maschinen tatsächlich lernen können (Vorwärts-/Rückwärtspropagation)BNächste-Nachbarn-Klassifikation (k-NN) - k-nächste-Nachbarn-AlgorithmusBk-Means (k-Means) - k-Means-Algorithmus- Image Processing
BInhaltsabhängige Bildverzerrung (Seam Carving) - Algorithmus zur inhaltsabhängigen Bildgrößenänderung- Unkategorisiert
BTürme von Hanoi (Tower of Hanoi)BRotationsmatrix (Square Matrix Rotation) - In-Place-AlgorithmusBJump Game (Jump Game) - Backtracking, dynamische Programmierung (Top-down + Bottom-up) und gierige BeispieleBEindeutige Pfade (Unique Paths) - Backtracking, dynamische Programmierung und Pascalsches Dreieck basierte BeispieleBRegenterrassen (Rain Terraces) - Auffangproblem für Regenwasser (trapping rain water problem) (dynamische Programmierung und Brute-Force-Versionen)BRekursive Treppe (Recursive Staircase) - Zählen der Anzahl der Wege, die nach oben führen (4 Lösungen)BBeste Zeit zum Kaufen/Verkaufen von Aktien (Best Time To Buy Sell Stocks) - Beispiele für "Teile und Herrsche" und Beispiele für den One-Pass-AlgorithmusADamenproblem (N-Queens Problem)ASpringerproblem (Knight's Tour)
Algorithmen nach Paradigma
Ein algorithmisches Paradigma ist eine generische Methode oder ein Ansatz, der dem Entwurf einer Klasse von Algorithmen zugrunde liegt. Es ist eine Abstraktion, die höher ist als der Begriff des Algorithmus. Genauso wie ein Algorithmus eine Abstraktion ist, die höher ist als ein Computerprogramm.
- Brachiale Gewalt (Brute Force) - schaut sich alle Möglichkeiten an und wählt die beste Lösung aus
BLineare Suche (Linear Search)BRegenterrassen (Rain Terraces) - Auffangproblem für Regenwasser (trapping rain water problem) (dynamische Programmierung und Brute-Force-Versionen)BRekursive Treppe (Recursive Staircase) - Zählen der Anzahl der Wege, die nach oben führen (4 Lösungen)ADas Maximum-Subarray Problem (Maximum Subarray)AProblem des Handlungsreisenden (Travelling Salesman Problem) - Kürzestmögliche Route, die jede Stadt besucht und zur Ausgangsstadt zurückkehrtADiskrete Fourier-Transformation (Discrete Fourier Transform) - Eine Funktion der Zeit (ein Signal) in die Frequenzen zerlegen, aus denen sie sich zusammensetzt- Gierig (Greedy) - Wählt die beste Option zum aktuellen Zeitpunkt, ohne Rücksicht auf die Zukunft
BJump Game (Jump Game)ARucksackproblem (Unbound Knapsack Problem)ADijkstra-Algorithmus (Dijkstra Algorithm) - Finden der kürzesten Wege zu allen Knoten des Graphen von einem einzelnen Knotenpunkt ausAAlgorithmus von Prim (Prim’s Algorithm) - Finden des Spannbaums (Minimum Spanning Tree / MST) für einen gewichteten ungerichteten GraphenBAlgorithmus von Kruskal (Kruskal’s Algorithm) - Finden des Spannbaum (Minimum Spanning Tree / MST) für einen gewichteten ungerichteten Graphen- Teile und herrsche - Das Problem in kleinere Teile aufteilen und diese Teile dann lösen
BBinäre Suche (Binary Search)BTürme von Hanoi (Tower of Hanoi)BPascalsches Dreieck (Pascal's Triangle)BEuklidischer Algorithmus (Euclidean Algorithm) - calculate the Greatest Common Divisor (GCD)BMergesort (Merge Sort)BQuicksort (Quicksort)BTiefensuche (Depth-First Search) (DFS)BBreitensuche (Breadth-First Search) (DFS)BMatrizen (Matrices) - Matrizen und grundlegende Matrixoperationen (Multiplikation, Transposition usw.)BJump Game (Jump Game)BFast Powering Algorithmus (Fast Powering)BBeste Zeit zum Kaufen/Verkaufen von Aktien (Best Time To Buy Sell Stocks) - Beispiele für "Teile und Herrsche" und Beispiele für den One-Pass-AlgorithmusAPermutation (Permutations) (mit und ohne Wiederholungen)AKombination (Combinations) (mit und ohne Wiederholungen)- Dynamische Programmierung - Eine Lösung aus zuvor gefundenen Teillösungen aufbauen
BFibonacci-Zahl (Fibonacci Number)BJump Game (Jump Game)BEindeutige Pfade (Unique Paths)BRegenterrassen (Rain Terraces) - Auffangproblem für Regenwasser (trapping rain water problem) (dynamische Programmierung und Brute-Force-Versionen)BRekursive Treppe (Recursive Staircase) - Zählen der Anzahl der Wege, die nach oben führen (4 Lösungen)BInhaltsabhängige Bildverzerrung (Seam Carving) - Algorithmus zur inhaltsabhängigen BildgrößenänderungALevenshtein-Distanz (Levenshtein Distance) - Minimaler Editierabstand zwischen zwei SequenzenAProblem der längsten gemeinsamen Teilsequenz (Longest Common Subsequence) (LCS)ALängstes häufiges Teilzeichenfolgenproblem (Longest Common Substring)ALängste gemeinsame Teilsequenz (Longest Increasing Subsequence)ADer kürzeste gemeinsame String (Shortest Common Supersequence)ARucksackproblem (0/1 Knapsack Problem)AGanzzahlige Partitionierung (Integer Partition)ADas Maximum-Subarray Problem (Maximum Subarray)ABellman-Ford-Algorithmus (Bellman-Ford Algorithm) - Finden der kürzesten Wege zu allen Knoten des Graphen von einem einzelnen Knotenpunkt ausAAlgorithmus von Floyd und Warshall (Floyd-Warshall Algorithm) - Die kürzesten Wege zwischen allen Knotenpaaren findenARegulärer Ausdruck (Regular Expression Matching)- Zurückverfolgung - Ähnlich wie bei Brute-Force versuchen Sie, alle möglichen Lösungen zu generieren, aber jedes Mal, wenn Sie die nächste Lösung generieren, testen Sie, ob sie alle Bedingungen erfüllt, und fahren erst dann mit der Generierung weiterer Lösungen fort. Andernfalls gehen Sie zurück und nehmen einen anderen Weg, um eine Lösung zu finden. Normalerweise wird das DFS-Traversal des Zustandsraums verwendet.
BJump Game (Jump Game)BEindeutige Pfade (Unique Paths)APotenzmenge (Power Set) - Alle Teilmengen einer MengeAHamiltonkreisproblem (Hamiltonian Cycle) - Jeden Eckpunkt genau einmal durchlaufen.ADamenproblem (N-Queens Problem)ASpringerproblem (Knight's Tour)AKombinationssumme (Combination Sum) - Alle Kombinationen finden, die eine bestimmte Summe bilden- Verzweigung & Bindung - Merkt sich die Lösung mit den niedrigsten Kosten, die in jeder Phase der Backtracking-Suche gefunden wurde, und verwendet die Kosten der bisher gefundenen Lösung mit den niedrigsten Kosten als untere Schranke für die Kosten einer Lösung des Problems mit den geringsten Kosten, um Teillösungen zu verwerfen, deren Kosten größer sind als die der bisher gefundenen Lösung mit den niedrigsten Kosten. Normalerweise wird das BFS-Traversal in Kombination mit dem DFS-Traversal des Zustandsraumbaums verwendet.
So verwendest du dieses Repository
Alle Abhängigkeiten installieren
npm install
ESLint ausführen
You may want to run it to check code quality.
npm run lint
Alle Tests ausführen
npm test
Tests nach Namen ausführen
npm test -- 'LinkedList'
Fehlerbehebung
Falls das Linting oder Testen fehlschlägt, versuche, den Ordner "node_modules" zu löschen und die npm-Pakete neu zu installieren:
rm -rf ./node_modules
npm i
Spielwiese
Du kannst mit Datenstrukturen und Algorithmen in der Datei ./src/playground/playground.js herumspielen und
dir in dieser Datei Tests schreiben ./src/playground/__test__/playground.test.js.
Dann führe einfach folgenden Befehl aus, um zu testen, ob dein Spielwiesencode wie erwartet funktioniert:
npm test -- 'playground'
Nützliche Informationen
Referenzen
▶ Datenstrukturen und Algorithmen auf YouTube(Englisch)
O-Notation (Big O Notation)
Die O-Notation wird verwendet, um Algorithmen danach zu klassifizieren, wie ihre Laufzeit oder ihr Platzbedarf mit zunehmender Eingabegröße wächst. In der folgenden Tabelle finden Sie die häufigsten Wachstumsordnungen von Algorithmen, die in Big-O-Notation angegeben sind.
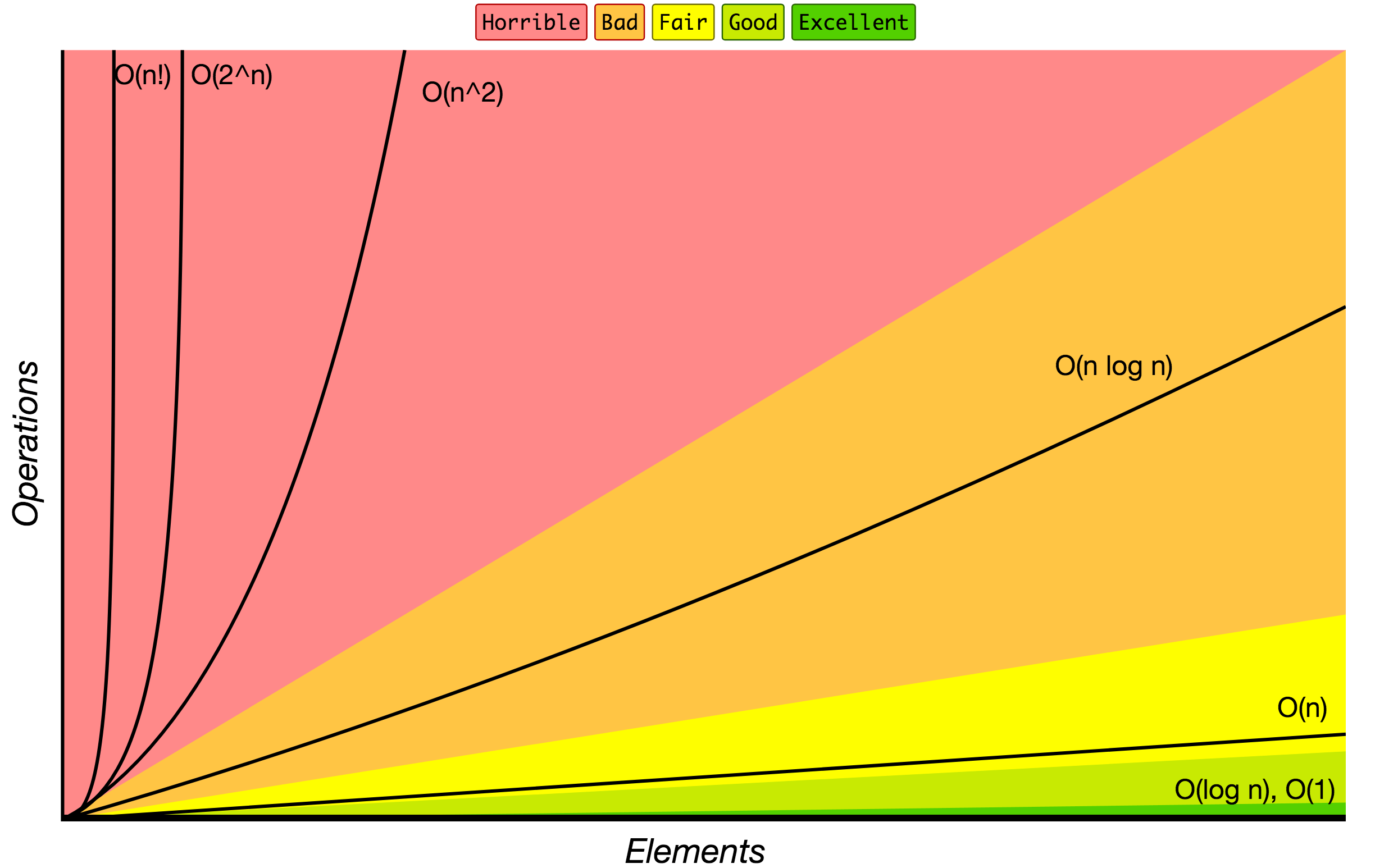
Quelle: Big O Cheat Sheet.
Nachfolgend finden Sie eine Liste einiger der am häufigsten verwendeten Big O-Notationen und deren Leistungsvergleiche für unterschiedliche Größen der Eingabedaten.
| Big O Notation | Berechnungen für 10 Elemente | Berechnungen für 100 Elemente | Berechnungen für 1000 Elemente |
|---|---|---|---|
| O(1) | 1 | 1 | 1 |
| O(log N) | 3 | 6 | 9 |
| O(N) | 10 | 100 | 1000 |
| O(N log N) | 30 | 600 | 9000 |
| O(N^2) | 100 | 10000 | 1000000 |
| O(2^N) | 1024 | 1.26e+29 | 1.07e+301 |
| O(N!) | 3628800 | 9.3e+157 | 4.02e+2567 |
Komplexität von Datenstrukturoperationen
| Datenstruktur | Zugriff auf | Suche | Einfügen | Löschung | Kommentare |
|---|---|---|---|---|---|
| Array | 1 | n | n | n | |
| Stack | n | n | 1 | 1 | |
| Queue | n | n | 1 | 1 | |
| Linked List | n | n | 1 | n | |
| Hash Table | - | n | n | n | Im Falle einer perfekten Hash-Funktion wären die Kosten O(1) |
| Binary Search Tree | n | n | n | n | Im Falle eines ausgeglichenen Baumes wären die Kosten O(log(n)) |
| B-Tree | log(n) | log(n) | log(n) | log(n) | |
| Red-Black Tree | log(n) | log(n) | log(n) | log(n) | |
| AVL Tree | log(n) | log(n) | log(n) | log(n) | |
| Bloom Filter | - | 1 | 1 | - | Falschpostive sind bei der Suche möglichen |
Komplexität von Array-Sortieralgorithmen
| Name | Bester | Durchschnitt | Schlechtester | Speicher | Stabil | Kommentar |
|---|---|---|---|---|---|---|
| Bubble sort | n | n2 | n2 | 1 | JA | |
| Insertion sort | n | n2 | n2 | 1 | Ja | |
| Selection sort | n2 | n2 | n2 | 1 | Nein | |
| Heap sort | n log(n) | n log(n) | n log(n) | 1 | Nein | |
| Merge sort | n log(n) | n log(n) | n log(n) | n | Ja | |
| Quick sort | n log(n) | n log(n) | n2 | log(n) | Nein | Quicksort wird normalerweise in-place mit O(log(n)) Stapelplatz ausgeführt |
| Shell sort | n log(n) | abhängig von Spaltfolge | n (log(n))2 | 1 | Nein | |
| Counting sort | n + r | n + r | n + r | n + r | Ja | r - größte Zahl im Array |
| Radix sort | n * k | n * k | n * k | n + k | Ja | k - Länge des längsten Schlüssels |
Projekt-Unterstützer
Du kannst dieses Projekt unterstützen über ❤️️ GitHub or ❤️️ Patreon.
Leute, die dieses Projekt unterstützen ∑ = 0
ℹ️ A few more projects and articles about JavaScript and algorithms on trekhleb.dev