首页
▼ 算法合集
▼ 加密算法
▼ 凯撒密码
凯撒密码
▼ Hill密码算法
Hill密码算法
▼ 多项式哈希算法
多项式哈希算法
▼ Rail Fence Cipher
Rail Fence Cipher
▼ Graph算法
▼ 关节点
关节点
▼ Bellman-Ford算法
Bellman-Ford算法
▼ 广度优先搜索
广度优先搜索
▼ GraphBridges
桥接模式
▼ 深度优先搜索
深度优先搜索
▼ 检测循环
检测循环
▼ Dijkstra算法
Dijkstra算法
▼ Eulerian Path
欧拉路径
▼ Floyd-Warshall算法
Floyd-Warshall算法
▼ HamiltonianCycle
Hamiltonian Cycle
▼ Kruskal算法
Kruskal算法
▼ Prim算法
Prim算法
▼ 强连通分量
强连通分量
▼ 拓扑排序
拓扑排序
▼ Travelling Salesman Problem
Travelling Salesman
▼ 图像处理算法
▼ Seam Carving算法
内容感知缩放算法
▼ 链表
▼ 反向遍历
反向遍历
▼ GraphTraversal
GraphTraversal
▼ 数学算法
▼ 二进制浮点数
BinaryFloatingPoint
▼ 位操作
位操作算法
▼ 复数
复数
▼ 欧几里得算法
Euclidean Algorithm
▼ Euclidean Distance
欧几里得距离
▼ 阶乘算法
阶乘算法
▼ 快速幂算法
快速幂算法
▼ Fibonacci数列
斐波那契数列
▼ 傅里叶变换
Fourier变换
▼ Horner法
霍纳法则
▼ 整数划分
整数划分
▼ 判断是否为2的幂
判断是否为2的幂
▼ 最小公倍数
最小公倍数
▼ Liu Hui
Liu Hui
▼ 矩阵
Matrix
▼ Pascal三角形
Pascal三角形
▼ Primality Test
素数测试
▼ 质因数
质因数
▼ 弧度计算
弧度计算
▼ 埃拉托色尼筛法
埃拉托色尼筛法
▼ SquareRoot
SquareRoot
▼ MachineLearning
▼ K均值算法
K均值算法
▼ K近邻算法
K近邻算法
▼ 搜索算法
▼ 二分查找算法
二分查找
▼ 插值搜索算法
插值搜索算法
▼ 跳跃搜索算法
跳跃搜索算法
▼ 线性搜索
线性搜索算法
▼ 集合
▼ 笛卡尔积
笛卡尔积
▼ 组合总和
组合总和
▼ 组合算法
组合算法
▼ Fisher-Yates洗牌算法
Fisher-Yates洗牌算法
▼ 背包问题
背包问题
▼ 最长公共子序列
最长公共子序列
▼ 最长递增子序列
最长递增子序列
▼ 最大子数组
最大子数组
▼ 排列组合
排列组合
▼ 幂集
幂集算法
▼ 最短公共超序列
最短公共超序列
▼ Sorting Algorithms
▼ 冒泡排序
冒泡排序
▼ 桶排序算法
桶排序算法
▼ 计数排序算法
计数排序
▼ 堆排序算法
堆排序
▼ 插入排序
插入排序
▼ 归并排序
归并排序
▼ 快速排序算法
快速排序算法
▼ 基数排序
基数排序
▼ 选择排序算法
选择排序算法
▼ 希尔排序
希尔排序
▼ 统计学
▼ 加权随机
加权随机算法
▼ 字符串算法
▼ Hamming距离
Hamming距离
▼ KnuthMorrisPratt算法
Knuth-Morris-Pratt算法
▼ LevenshteinDistance
Levenshtein距离
▼ 最长公共子串
最长公共子串
▼ 回文检测算法
回文检测算法
▼ Rabin-Karp算法
Rabin-Karp算法
▼ 正则表达式匹配
正则表达式匹配
▼ Z算法
Z算法
▼ Tree Data Structure
▼ 广度优先搜索
广度优先搜索
▼ 深度优先搜索
深度优先搜索
▼ 未分类
▼ 最佳买卖股票时机
最佳买卖股票时机
▼ 汉诺塔算法
HanoiTower
▼ 跳跃游戏算法
跳跃游戏
▼ KnightTour
骑士巡逻
▼ N皇后问题
N皇后问题
▼ 雨水收集
雨水收集
▼ 递归楼梯问题
递归楼梯问题
▼ 方阵旋转
方阵旋转
▼ 独特路径
UniquePaths
▼ 数据结构
▼ BloomFilter算法
布隆过滤器
▼ 不相交集数据结构
Disjoint Set
▼ 双向链表
双向链表
▼ Graph
Graph算法
▼ 哈希表
哈希表
▼ Heap数据结构
Heap数据结构
▼ 链表
链表
▼ LRU缓存
LRU缓存
▼ 优先队列
优先队列
▼ 队列
队列
▼ 栈结构
栈结构
▼ Tree Data Structure
树结构
▼ AVL树
AVL树
▼ 二叉搜索树
二叉搜索树
▼ Fenwick树
Fenwick树
▼ 红黑树
红黑树
▼ 线段树
SegmentTree
▼ Trie数据结构
Trie数据结构
距离度量
Levenshtein距离是一种用于衡量两个序列之间差异的字符串度量方法。非正式地讲,两个单词之间的Levenshtein距离是改变一个单词为另一个单词所需的最少单个字符编辑次数(插入、删除或替换)。
定义
从数学上讲,两个字符串a和b(分别具有|a|和|b|长度)之间的Levenshtein距离由以下公式给出:

其中

当相应的符号相同时,d[i][j]等于1,否则等于0,a[i]和b[j]之间的距离表示为d[i][j]。
请注意最小值的第一项对应于从a到b的删除(kitten到sitting),第二项对应于插入,第三项对应于匹配或不匹配,这取决于各自的符号是否相同。
示例
例如,kitten和sitting之间的Levenshtein距离是3,因为以下三个编辑可以将一个变为另一个,且没有办法用少于三个编辑来完成:
- kitten → sitten(用“s”替换“k”)
- sitten → sittin(用“i”替换“e”)
- sittin → sitting(在末尾插入“g”)
应用
这个概念有广泛的应用,例如拼写检查器、光学字符识别的校正系统、模糊字符串搜索以及基于翻译记忆的软件来辅助自然语言翻译。
动态规划方法解释
让我们以寻找字符串ME和MY之间最小编辑距离的简单示例为例。直观上你已经知道这里的最小编辑距离是1操作,即用Y替换E。但让我们尝试以算法的形式来形式化它,以便能够处理更复杂的例子,比如将Saturday转换为Sunday。
为了将上述数学公式应用于ME → MY转换,我们需要事先知道ME → M、M → MY和M → M转换的最小编辑距离。然后我们将需要选择最小的一个,并加上一个操作来转换最后一个字母E → Y。因此,ME → MY转换的最小编辑距离是基于这三个先前可能的转换计算的。
为了进一步解释,请画出以下矩阵:
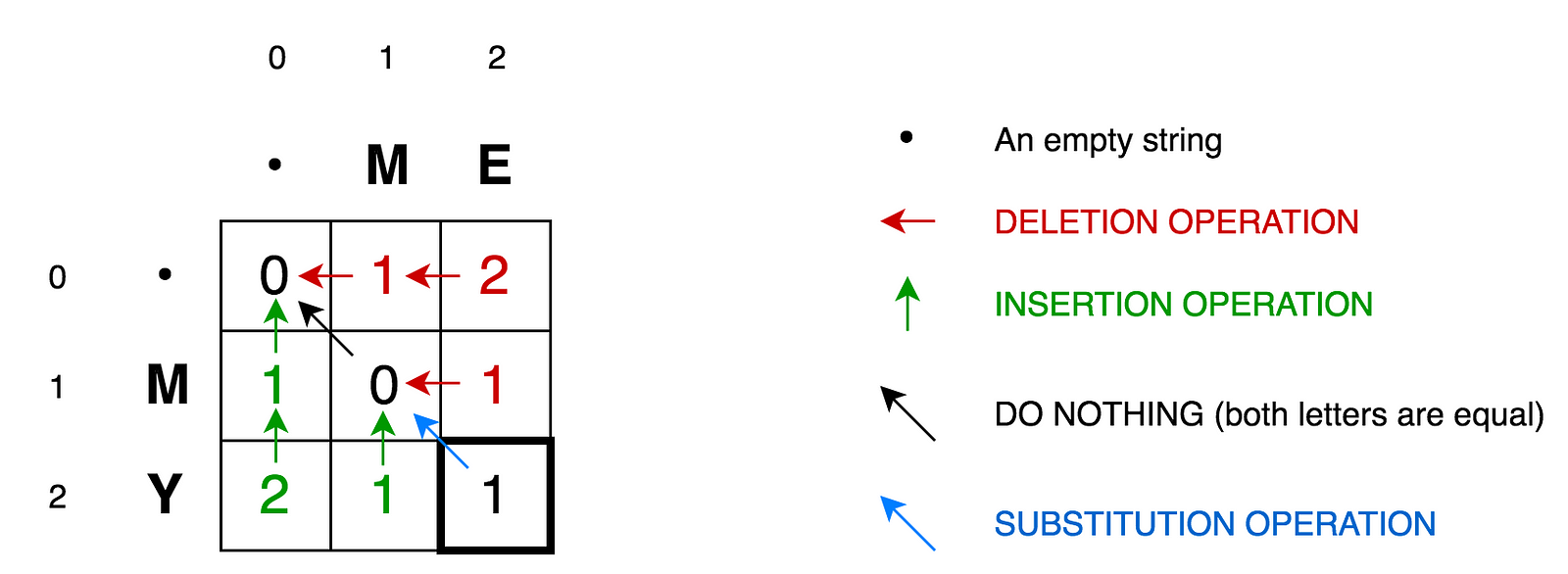
- 单元格
(0:1)包含红色数字1。这意味着我们需要1个操作将M转换为空字符串。这是通过删除M来实现的。这就是为什么这个数字是红色的。
- 单元格
(0:2)包含红色数字2。这意味着我们需要2个操作将ME转换为空字符串。这是通过删除E和M来实现的。
- 单元格
(1:0)包含绿色数字1。这意味着我们需要1个操作将空字符串转换为M。这是通过插入M来实现的。这就是为什么这个数字是绿色的。
- 单元格
(2:0)包含绿色数字2。这意味着我们需要2个操作将空字符串转换为MY。这是通过插入Y和M来实现的。
- 单元格
(1:1)包含数字0。这意味着将M转换为M不需要任何操作。
- 单元格
(1:2)包含红色数字1。这意味着我们需要1个操作将ME转换为M。这是通过删除E来实现的。
- 等等...
对于我们这样的小矩阵(只有3x3),这看起来很容易。但你可能会发现一些基本概念可以应用于计算更大矩阵的所有这些数字(比如说9x7矩阵用于Saturday → Sunday转换)。
根据公式,你只需要三个相邻单元格(i-1:j)、(i-1:j-1)和(i:j-1)来计算当前单元格(i:j)的数字。我们需要做的就是找到这三个单元格中的最小值,然后在i的行和j的列中有不同字母的情况下加1。
你可以清楚地看到问题的递归性质。
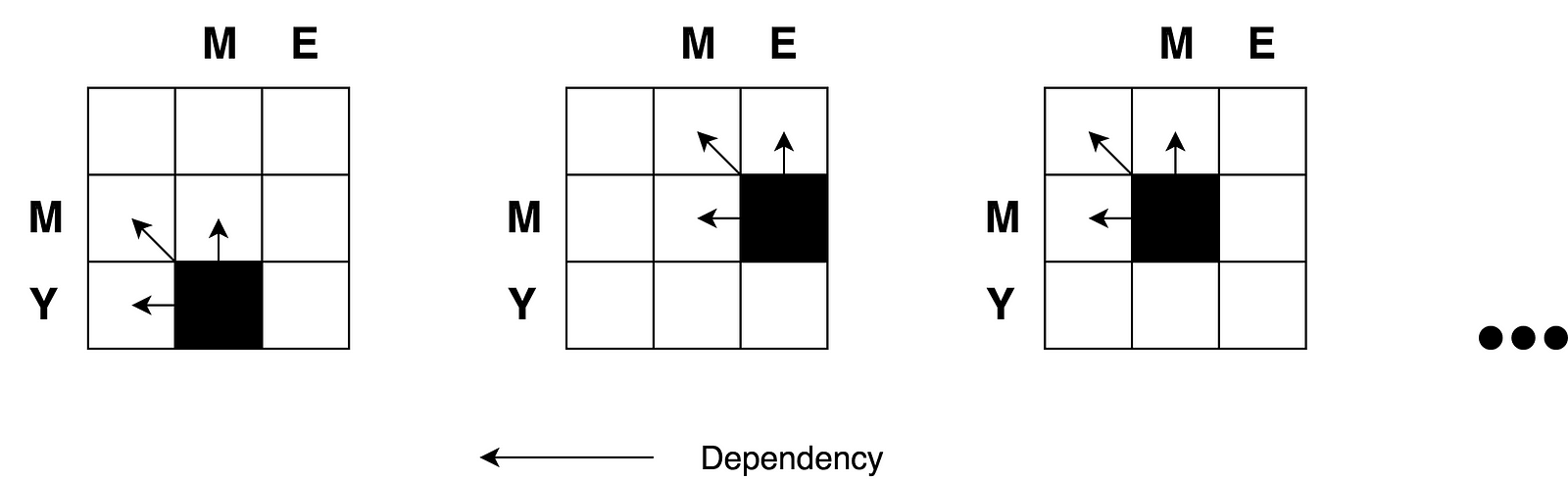
让我们为这个问题绘制一个决策图。
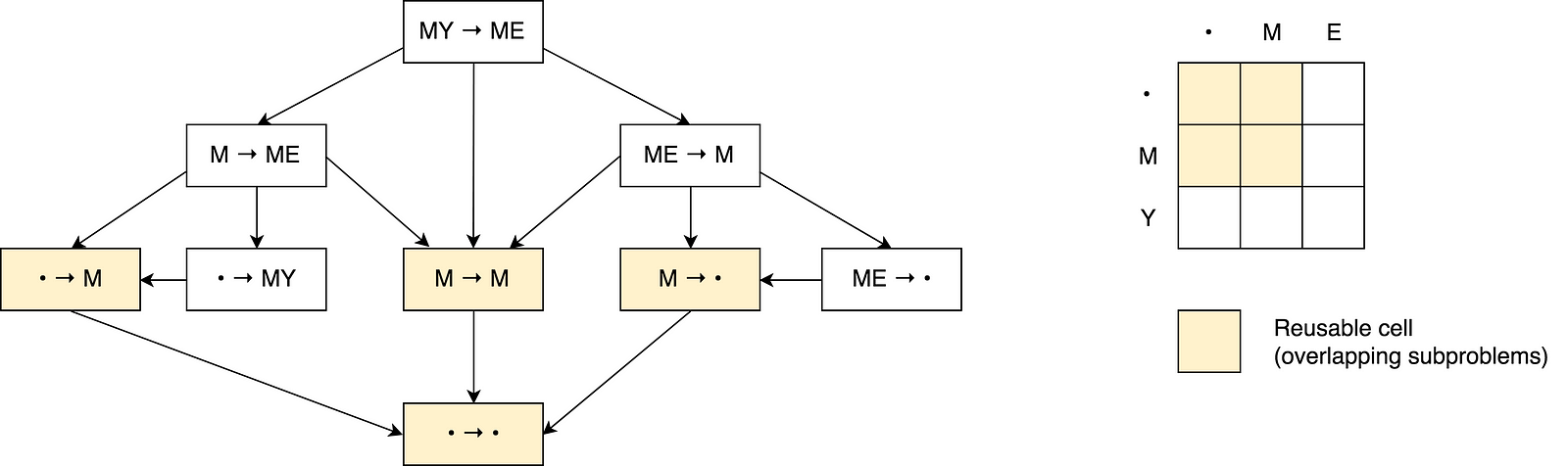
你可以看到图片上有许多重叠子问题,它们被标记为红色。此外,根据公式,无法减少操作数量并使其小于这三个相邻单元格中的最小值。
你可能还会注意到,矩阵中的每个单元格数字都是基于前面的单元格计算的。因此,这里应用了自底向上的填充缓存技术。
进一步应用这个原则,我们可以解决更复杂的情况,比如Saturday → Sunday转换。
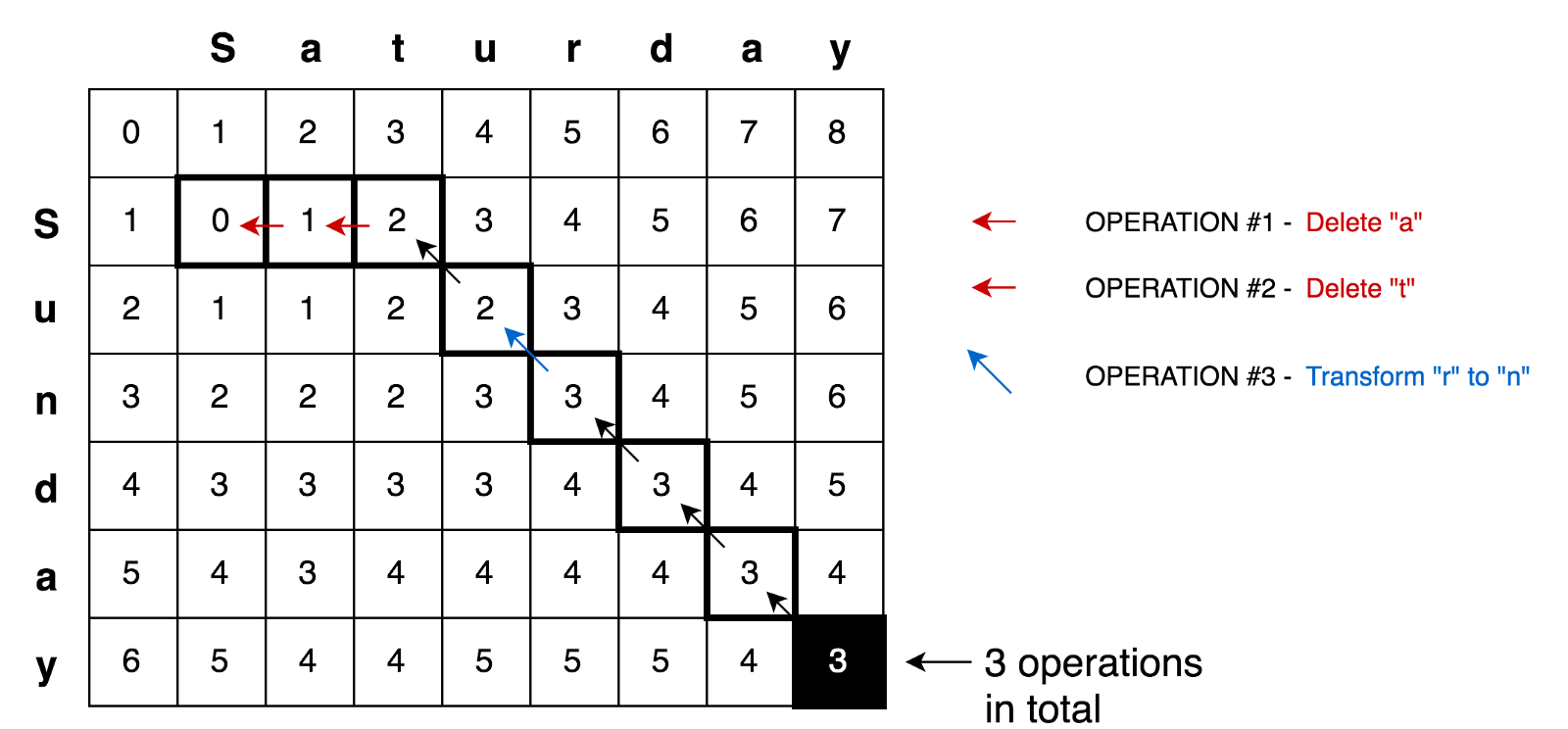
参考文献