首页
▼ 算法合集
▼ 加密算法
▼ 凯撒密码
凯撒密码
▼ Hill密码算法
Hill密码算法
▼ 多项式哈希算法
多项式哈希算法
▼ Rail Fence Cipher
Rail Fence Cipher
▼ Graph算法
▼ 关节点
关节点
▼ Bellman-Ford算法
Bellman-Ford算法
▼ 广度优先搜索
广度优先搜索
▼ GraphBridges
桥接模式
▼ 深度优先搜索
深度优先搜索
▼ 检测循环
检测循环
▼ Dijkstra算法
Dijkstra算法
▼ Eulerian Path
欧拉路径
▼ Floyd-Warshall算法
Floyd-Warshall算法
▼ HamiltonianCycle
Hamiltonian Cycle
▼ Kruskal算法
Kruskal算法
▼ Prim算法
Prim算法
▼ 强连通分量
强连通分量
▼ 拓扑排序
拓扑排序
▼ Travelling Salesman Problem
Travelling Salesman
▼ 图像处理算法
▼ Seam Carving算法
内容感知缩放算法
▼ 链表
▼ 反向遍历
反向遍历
▼ GraphTraversal
GraphTraversal
▼ 数学算法
▼ 二进制浮点数
BinaryFloatingPoint
▼ 位操作
位操作算法
▼ 复数
复数
▼ 欧几里得算法
Euclidean Algorithm
▼ Euclidean Distance
欧几里得距离
▼ 阶乘算法
阶乘算法
▼ 快速幂算法
快速幂算法
▼ Fibonacci数列
斐波那契数列
▼ 傅里叶变换
Fourier变换
▼ Horner法
霍纳法则
▼ 整数划分
整数划分
▼ 判断是否为2的幂
判断是否为2的幂
▼ 最小公倍数
最小公倍数
▼ Liu Hui
Liu Hui
▼ 矩阵
Matrix
▼ Pascal三角形
Pascal三角形
▼ Primality Test
素数测试
▼ 质因数
质因数
▼ 弧度计算
弧度计算
▼ 埃拉托色尼筛法
埃拉托色尼筛法
▼ SquareRoot
SquareRoot
▼ MachineLearning
▼ K均值算法
K均值算法
▼ K近邻算法
K近邻算法
▼ 搜索算法
▼ 二分查找算法
二分查找
▼ 插值搜索算法
插值搜索算法
▼ 跳跃搜索算法
跳跃搜索算法
▼ 线性搜索
线性搜索算法
▼ 集合
▼ 笛卡尔积
笛卡尔积
▼ 组合总和
组合总和
▼ 组合算法
组合算法
▼ Fisher-Yates洗牌算法
Fisher-Yates洗牌算法
▼ 背包问题
背包问题
▼ 最长公共子序列
最长公共子序列
▼ 最长递增子序列
最长递增子序列
▼ 最大子数组
最大子数组
▼ 排列组合
排列组合
▼ 幂集
幂集算法
▼ 最短公共超序列
最短公共超序列
▼ Sorting Algorithms
▼ 冒泡排序
冒泡排序
▼ 桶排序算法
桶排序算法
▼ 计数排序算法
计数排序
▼ 堆排序算法
堆排序
▼ 插入排序
插入排序
▼ 归并排序
归并排序
▼ 快速排序算法
快速排序算法
▼ 基数排序
基数排序
▼ 选择排序算法
选择排序算法
▼ 希尔排序
希尔排序
▼ 统计学
▼ 加权随机
加权随机算法
▼ 字符串算法
▼ Hamming距离
Hamming距离
▼ KnuthMorrisPratt算法
Knuth-Morris-Pratt算法
▼ LevenshteinDistance
Levenshtein距离
▼ 最长公共子串
最长公共子串
▼ 回文检测算法
回文检测算法
▼ Rabin-Karp算法
Rabin-Karp算法
▼ 正则表达式匹配
正则表达式匹配
▼ Z算法
Z算法
▼ Tree Data Structure
▼ 广度优先搜索
广度优先搜索
▼ 深度优先搜索
深度优先搜索
▼ 未分类
▼ 最佳买卖股票时机
最佳买卖股票时机
▼ 汉诺塔算法
HanoiTower
▼ 跳跃游戏算法
跳跃游戏
▼ KnightTour
骑士巡逻
▼ N皇后问题
N皇后问题
▼ 雨水收集
雨水收集
▼ 递归楼梯问题
递归楼梯问题
▼ 方阵旋转
方阵旋转
▼ 独特路径
UniquePaths
▼ 数据结构
▼ BloomFilter算法
布隆过滤器
▼ 不相交集数据结构
Disjoint Set
▼ 双向链表
双向链表
▼ Graph
Graph算法
▼ 哈希表
哈希表
▼ Heap数据结构
Heap数据结构
▼ 链表
链表
▼ LRU缓存
LRU缓存
▼ 优先队列
优先队列
▼ 队列
队列
▼ 栈结构
栈结构
▼ Tree Data Structure
树结构
▼ AVL树
AVL树
▼ 二叉搜索树
二叉搜索树
▼ Fenwick树
Fenwick树
▼ 红黑树
红黑树
▼ 线段树
SegmentTree
▼ Trie数据结构
Trie数据结构
Árvore de Segmento (Segment Tree)
Na ciência da computação, uma árvore de segmento também conhecida como
árvore estatística é uma árvore de estrutura de dados utilizadas para
armazenar informações sobre intervalores ou segmentos. Ela permite pesquisas
no qual os segmentos armazenados contém um ponto fornecido. Isto é,
em princípio, uma estrutura estática; ou seja, é uma estrutura que não pode
ser modificada depois de inicializada. Uma estrutura de dados similar é a
árvore de intervalos.
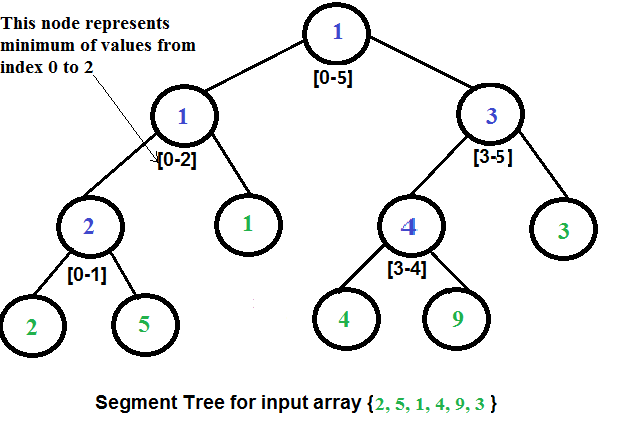
Uma árvore de segmento é uma árvore binária. A raíz da árvore representa a
array inteira. Os dois filhos da raíz representam a primeira e a segunda
metade da array. Similarmente, os filhos de cada nó correspondem ao número
das duas metadas da array correspondente do nó.
Nós construímos a árvore debaixo para cima, com o valor de cada nó sendo o
"mínimo" (ou qualquer outra função) dos valores de seus filhos. Isto consumirá
tempo O(n log n). O número de oprações realizadas é equivalente a altura da
árvore, pela qual consome tempo O(log n). Para fazer consultas de intervalos,
cada nó divide a consulta em duas partes, sendo uma sub consulta para cada filho.
Se uma pesquisa contém todo o subarray de um nó, nós podemos utilizar do valor
pré-calculado do nó. Utilizando esta otimização, nós podemos provar que somente
operações mínimas O(log n) são realizadas.

Aplicação
Uma árvore de segmento é uma estrutura de dados designada a realizar
certas operações de array eficientemente, especialmente aquelas envolvendo
consultas de intervalos.
Aplicações da árvore de segmentos são nas áreas de computação geométrica e
sistemas de informação geográficos.
A implementação atual da Árvore de Segmentos implica que você pode passar
qualquer função binária (com dois parâmetros de entradas) e então, você
será capaz de realizar consultas de intervalos para uma variedade de funções.
Nos testes você poderá encontrar exemplos realizando min, max e consultas de
intervalo sum na árvore segmentada (SegmentTree).
Referências