首页
▼ 算法合集
▼ 加密算法
▼ 凯撒密码
凯撒密码
▼ Hill密码算法
Hill密码算法
▼ 多项式哈希算法
多项式哈希算法
▼ Rail Fence Cipher
Rail Fence Cipher
▼ Graph算法
▼ 关节点
关节点
▼ Bellman-Ford算法
Bellman-Ford算法
▼ 广度优先搜索
广度优先搜索
▼ GraphBridges
桥接模式
▼ 深度优先搜索
深度优先搜索
▼ 检测循环
检测循环
▼ Dijkstra算法
Dijkstra算法
▼ Eulerian Path
欧拉路径
▼ Floyd-Warshall算法
Floyd-Warshall算法
▼ HamiltonianCycle
Hamiltonian Cycle
▼ Kruskal算法
Kruskal算法
▼ Prim算法
Prim算法
▼ 强连通分量
强连通分量
▼ 拓扑排序
拓扑排序
▼ Travelling Salesman Problem
Travelling Salesman
▼ 图像处理算法
▼ Seam Carving算法
内容感知缩放算法
▼ 链表
▼ 反向遍历
反向遍历
▼ GraphTraversal
GraphTraversal
▼ 数学算法
▼ 二进制浮点数
BinaryFloatingPoint
▼ 位操作
位操作算法
▼ 复数
复数
▼ 欧几里得算法
Euclidean Algorithm
▼ Euclidean Distance
欧几里得距离
▼ 阶乘算法
阶乘算法
▼ 快速幂算法
快速幂算法
▼ Fibonacci数列
斐波那契数列
▼ 傅里叶变换
Fourier变换
▼ Horner法
霍纳法则
▼ 整数划分
整数划分
▼ 判断是否为2的幂
判断是否为2的幂
▼ 最小公倍数
最小公倍数
▼ Liu Hui
Liu Hui
▼ 矩阵
Matrix
▼ Pascal三角形
Pascal三角形
▼ Primality Test
素数测试
▼ 质因数
质因数
▼ 弧度计算
弧度计算
▼ 埃拉托色尼筛法
埃拉托色尼筛法
▼ SquareRoot
SquareRoot
▼ MachineLearning
▼ K均值算法
K均值算法
▼ K近邻算法
K近邻算法
▼ 搜索算法
▼ 二分查找算法
二分查找
▼ 插值搜索算法
插值搜索算法
▼ 跳跃搜索算法
跳跃搜索算法
▼ 线性搜索
线性搜索算法
▼ 集合
▼ 笛卡尔积
笛卡尔积
▼ 组合总和
组合总和
▼ 组合算法
组合算法
▼ Fisher-Yates洗牌算法
Fisher-Yates洗牌算法
▼ 背包问题
背包问题
▼ 最长公共子序列
最长公共子序列
▼ 最长递增子序列
最长递增子序列
▼ 最大子数组
最大子数组
▼ 排列组合
排列组合
▼ 幂集
幂集算法
▼ 最短公共超序列
最短公共超序列
▼ Sorting Algorithms
▼ 冒泡排序
冒泡排序
▼ 桶排序算法
桶排序算法
▼ 计数排序算法
计数排序
▼ 堆排序算法
堆排序
▼ 插入排序
插入排序
▼ 归并排序
归并排序
▼ 快速排序算法
快速排序算法
▼ 基数排序
基数排序
▼ 选择排序算法
选择排序算法
▼ 希尔排序
希尔排序
▼ 统计学
▼ 加权随机
加权随机算法
▼ 字符串算法
▼ Hamming距离
Hamming距离
▼ KnuthMorrisPratt算法
Knuth-Morris-Pratt算法
▼ LevenshteinDistance
Levenshtein距离
▼ 最长公共子串
最长公共子串
▼ 回文检测算法
回文检测算法
▼ Rabin-Karp算法
Rabin-Karp算法
▼ 正则表达式匹配
正则表达式匹配
▼ Z算法
Z算法
▼ Tree Data Structure
▼ 广度优先搜索
广度优先搜索
▼ 深度优先搜索
深度优先搜索
▼ 未分类
▼ 最佳买卖股票时机
最佳买卖股票时机
▼ 汉诺塔算法
HanoiTower
▼ 跳跃游戏算法
跳跃游戏
▼ KnightTour
骑士巡逻
▼ N皇后问题
N皇后问题
▼ 雨水收集
雨水收集
▼ 递归楼梯问题
递归楼梯问题
▼ 方阵旋转
方阵旋转
▼ 独特路径
UniquePaths
▼ 数据结构
▼ BloomFilter算法
布隆过滤器
▼ 不相交集数据结构
Disjoint Set
▼ 双向链表
双向链表
▼ Graph
Graph算法
▼ 哈希表
哈希表
▼ Heap数据结构
Heap数据结构
▼ 链表
链表
▼ LRU缓存
LRU缓存
▼ 优先队列
优先队列
▼ 队列
队列
▼ 栈结构
栈结构
▼ Tree Data Structure
树结构
▼ AVL树
AVL树
▼ 二叉搜索树
二叉搜索树
▼ Fenwick树
Fenwick树
▼ 红黑树
红黑树
▼ 线段树
SegmentTree
▼ Trie数据结构
Trie数据结构
LRU 캐시 알고리즘
LRU 캐시 알고리즘 은 사용된 순서대로 아이템을 정리함으로써, 오랜 시간 동안 사용되지 않은 아이템을 빠르게 찾아낼 수 있도록 한다.
한방향으로만 옷을 걸 수 있는 옷걸이 행거를 생각해봅시다. 가장 오랫동안 입지 않은 옷을 찾기 위해서는, 행거의 반대쪽 끝을 보면 됩니다.
문제 정의
LRUCache 클래스를 구현해봅시다:
LRUCache(int capacity) LRU 캐시를 양수 의 capacity 로 초기화합니다.int get(int key) key 가 존재할 경우 key 값을 반환하고, 그렇지 않으면 undefined 를 반환합니다.void set(int key, int value) key 가 존재할 경우 key 값을 업데이트 하고, 그렇지 않으면 key-value 쌍을 캐시에 추가합니다. 만약 이 동작으로 인해 키 개수가 capacity 를 넘는 경우, 가장 오래된 키 값을 제거 합니다.
get() 과 set() 함수는 무조건 평균 O(1) 의 시간 복잡도 내에 실행되어야 합니다.
구현
버전 1: 더블 링크드 리스트 + 해시맵
LRUCache.js 에서 LRUCache 구현체 예시를 확인할 수 있습니다. 예시에서는 (평균적으로) 빠른 O(1) 캐시 아이템 접근을 위해 HashMap 을 사용했고, (평균적으로) 빠른 O(1) 캐시 아이템 수정과 제거를 위해 DoublyLinkedList 를 사용했습니다. (허용된 최대의 캐시 용량을 유지하기 위해)
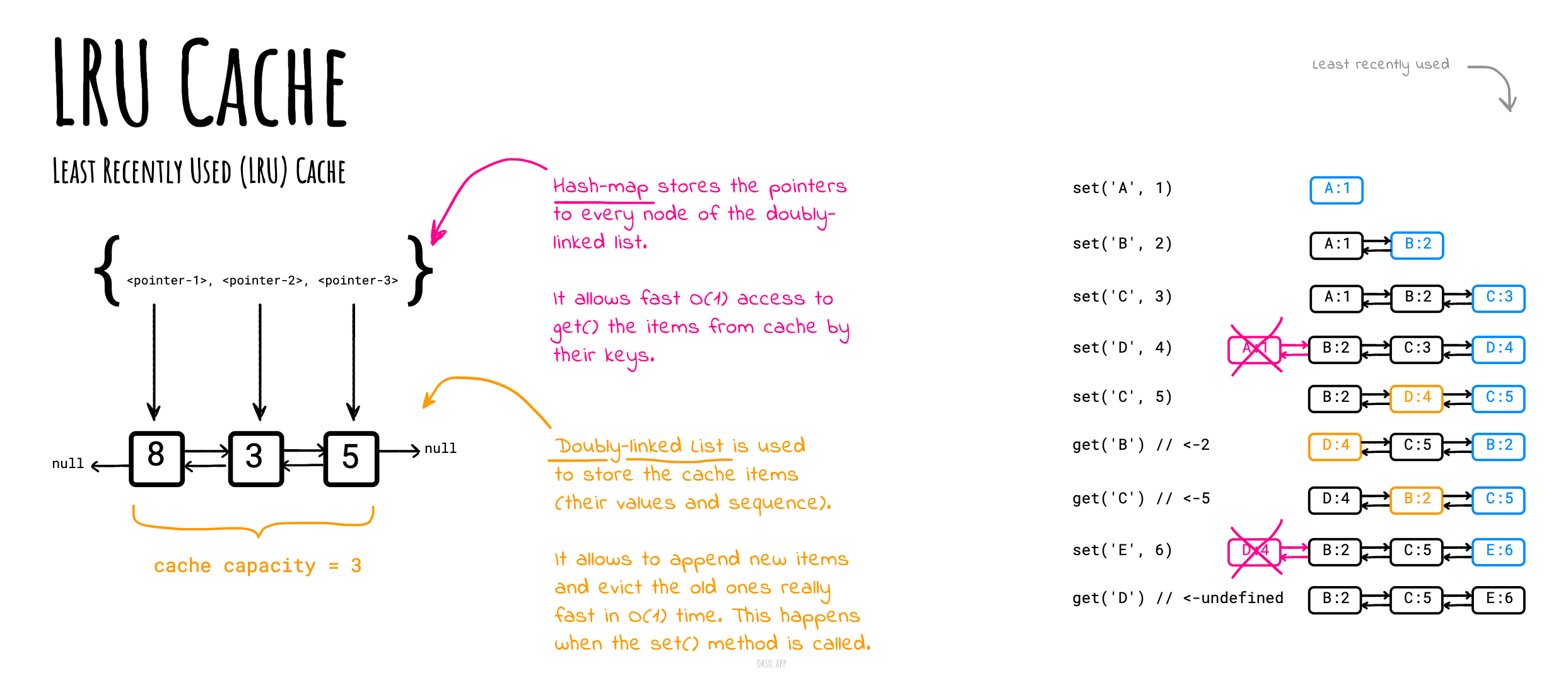
okso.app 으로 만듦
LRU 캐시가 어떻게 작동하는지 더 많은 예시로 확인하고 싶다면 LRUCache.test.js](./test/LRUCache.test.js) 파일을 참고하세요.
버전 2: 정렬된 맵
더블 링크드 리스트로 구현한 첫번째 예시는 어떻게 평균 O(1) 시간 복잡도가 set() 과 get() 으로 나올 수 있는지 학습 목적과 이해를 돕기 위해 좋은 예시입니다.
그러나, 더 쉬운 방법은 자바스크립트의 Map 객체를 사용하는 것입니다. 이 Map 객체는 키-값 쌍과 키를 추가하는 순서 원본 을 지닙니다. 우리는 이걸 아이템을 제거하거나 다시 추가하면서 맵의 "가장 마지막" 동작에서 최근에 사용된 아이템을 유지하기 위해 사용할 수 있습니다. Map 의 시작점에 있는 아이템은 캐시 용량이 넘칠 경우 가장 먼저 제거되는 대상입니다. 아이템의 순서는 map.keys() 와 같은 IterableIterator 을 사용해 확인할 수 있습니다.
해당 구현체는 LRUCacheOnMap.js 의 LRUCacheOnMap 예시에서 확인할 수 있습니다.
이 LRU 캐시 방식이 어떻게 작동하는지 더 많은 테스트 케이스를 확인하고 싶다면 LRUCacheOnMap.test.js 파일을 참고하세요.
복잡도
|
평균 |
| 공간 |
O(n) |
| 아이템 찾기 |
O(1) |
| 아이템 설정하기 |
O(1) |
참조