注意
本文档适用于 Ceph 开发版本。
擦除编码增强
目标
我们的目的是提高擦除编码的性能,特别是对于小随机访问,使其更可行地使用擦除编码池来存储块和文件数据。
我们正在寻求减少每个客户端 I/O 的 OSD 读取和写入访问次数(有时也称为 I/O 放大),减少 OSD 之间的网络流量(网络带宽)并减少 I/O 延迟(完成读取和写入 I/O 操作所需的时间)。我们预计这些更改还将为 CPU 开销提供适度的减少。
虽然这些更改的重点是增强小随机访问,但一些增强功能将为较大的 I/O 访问和对象存储提供适度的益处。
以下部分简要介绍了我们希望进行的改进。更多详细信息请参阅后面的设计部分。
当前读取实现
作为参考,这是擦除编码当前读取的工作方式
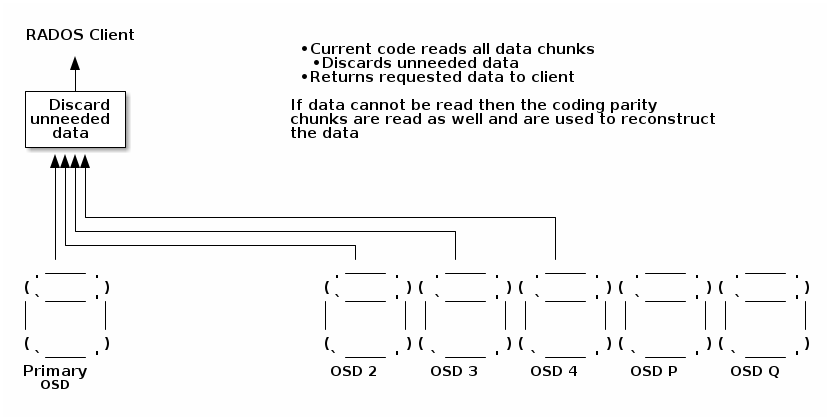
注意:所有图表都说明了 K=4 + M=2 的配置,但是这些概念和技术适用于所有 K+M 配置。
部分读取
如果只读取少量数据,则无需读取整个条带,对于小 I/O,理想情况下只需一个 OSD 就可以参与读取数据。另见下文更大的块大小部分。
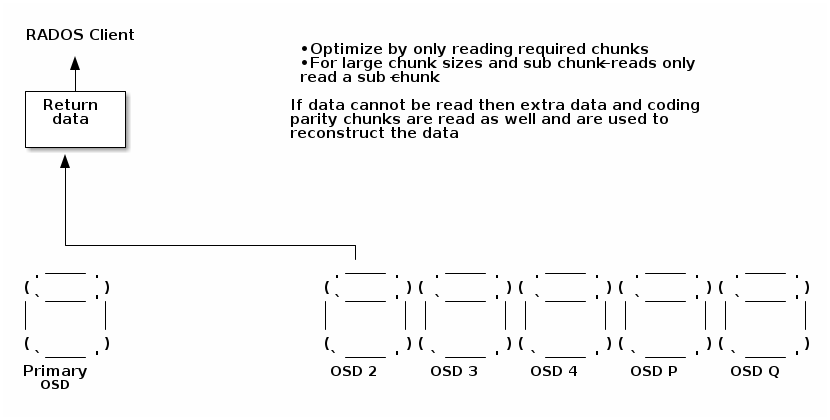
拉取请求https://github.com/ceph/ceph/pull/55196正在实现大部分此优化,但它仍然发出完整的块读取。
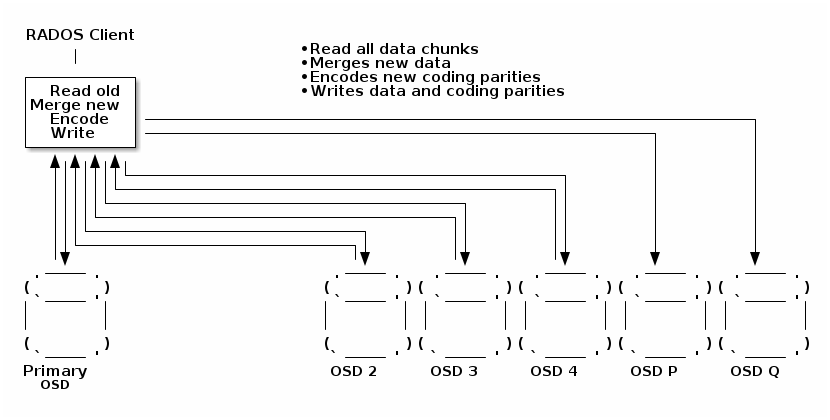
当前覆盖实现
作为参考,这是擦除编码覆盖当前的工作方式
部分覆盖
理想情况下,我们希望能够通过仅更新部分分片(那些包含修改后的数据或编码奇偶校验)来执行擦除编码条带的更新。避免在其他分片中执行不必要的数据更新很容易,但避免在其他分片中执行任何元数据更新要困难得多(见元数据更新设计部分)。
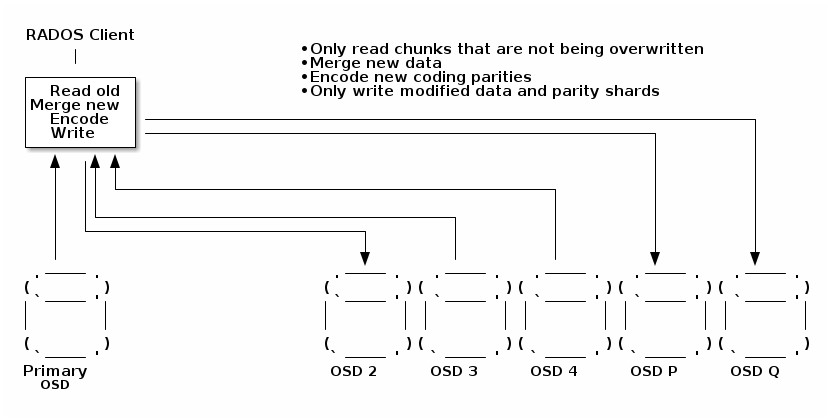
此图表过于简单,仅显示数据流。此优化的最简单实现保留了每个 OSD 的元数据写入。通过更多的努力,可以减少元数据更新的次数,更多详细信息请参见下面的设计部分。
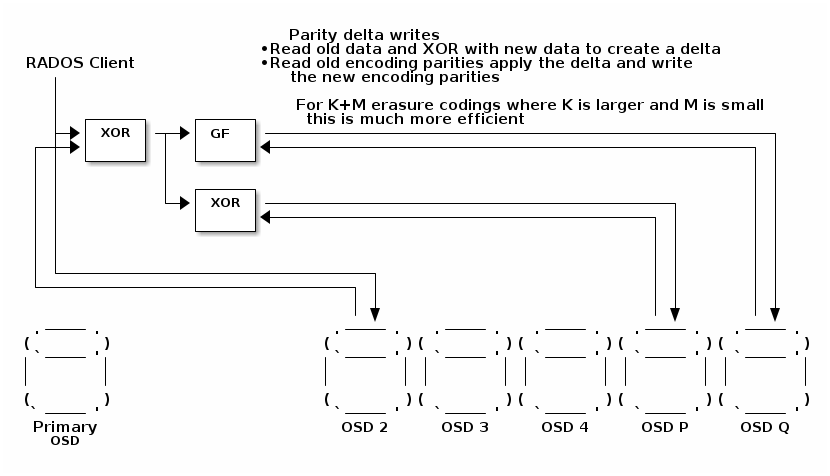
奇偶校验-差分写入
实现 RAID5 和 RAID6 的块存储控制器常用的一种技术是实施有时被称为奇偶校验增量写入的内容。当条带的一部分被覆盖时,可以通过读取旧数据、将旧数据与新数据异或以创建增量,然后读取每个编码奇偶校验、应用增量并写入新的奇偶校验来完成更新。此技术的优点是它可以涉及大量较少的 I/O,特别是对于具有较大 K 值的 K+M 编码。该技术并非特定于 M=1 和 M=2,它可以应用于任何数量的编码奇偶校验。
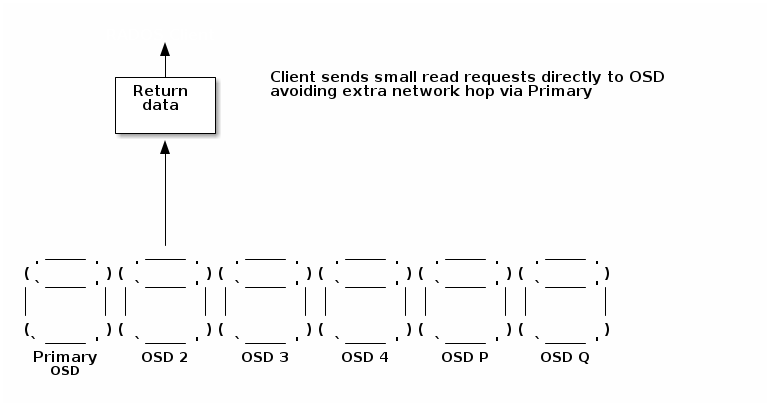
直接读取I/O
我们希望客户端将小 I/O 直接提交到存储数据的 OSD,而不是将所有 I/O 请求都指向主 OSD 并由其发出对次级 OSD 的请求。通过消除中间跳转,这减少了网络带宽并提高了 I/O 延迟。
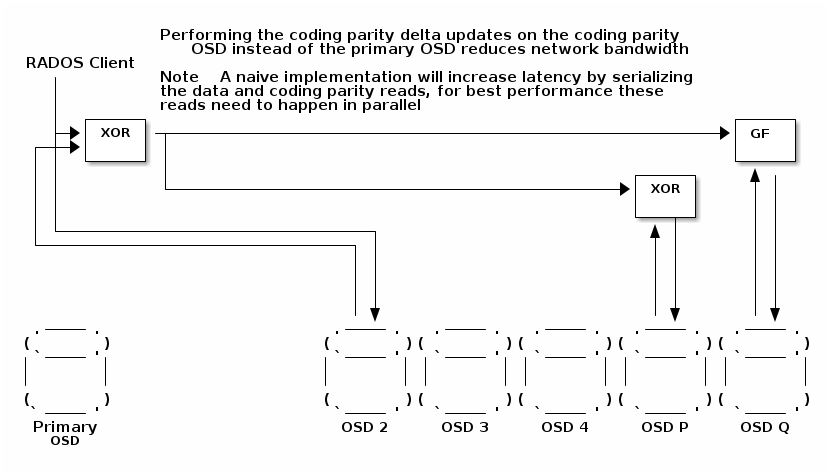
分布式写入处理
现有的擦除编码实现处理主 OSD 上的写入 I/O,向其他 OSD 发出读取和写入请求以获取和更新其他分片的数据。这是最简单的实现,但它使用了大量的网络带宽。使用奇偶校验增量写入,可以将处理分布在 OSD 上以减少网络带宽。
直接写入I/O
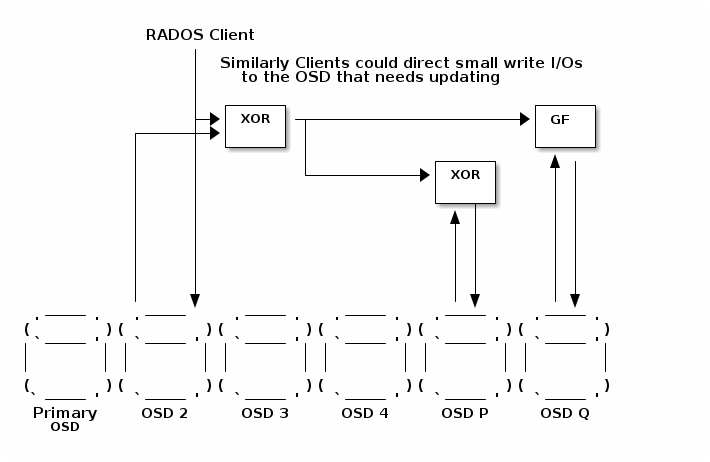
此图表过于简单,仅显示数据流 - 直接写入要复杂得多,需要向主 OSD 发送控制消息以确保写入同一条带的写入顺序正确。
更大的块大小
默认块大小为 4K,这太小了,这意味着小读取必须分成多个部分并由许多 OSD 处理。如果小 I/O 可以由单个 OSD 服务,则效率更高。选择更大的块大小,例如 64K 或 256K,并实现部分读取和写入将解决这个问题,但缺点是小型 RADOS 对象的大小将四舍五入为整个条带容量。
我们希望代码能够自动选择使用什么块大小来优化容量和性能。小对象应该使用小的块大小,例如 4K,大对象应该使用较大的块大小。
当前代码将 I/O 大小四舍五入为块大小的倍数,这在块大小较小时不是问题。对于较大的块大小和部分读取/写入,我们应该四舍五入到页面大小而不是块大小。
设计
我们将在三个部分中描述我们希望进行的更改,第一部分查看现有的擦除编码测试工具并讨论为了获得对这些更改的良好测试覆盖范围所认为必要的改进。
第二部分涵盖了读取和写入 I/O 路径的更改。
第三部分讨论元数据的更改,以避免每次元数据更新都需要更新所有分片的元数据。
测试工具
对现有测试工具的调查表明,擦除编码的覆盖范围不足,无法仅仅通过更改代码并期望现有的 CI 管道获得足够的覆盖范围。因此,第一步将是改进测试工具以获得更好的测试覆盖范围。
Teuthology 是用于获取测试覆盖范围的主要测试工具,它严重依赖于以下用于生成 I/O 的测试:
rados任务 - qa/tasks/rados.py。这使用 ceph_test_rados
radosbench任务 - qa/tasks/radosbench.py。这使用rados bench(src/tools/rados/rados.cc 和 src/common/obj_bencher.cc)。可用于生成顺序和随机 I/O 负载,顺序 I/O 的偏移量从 0 开始。I/O 大小可以设置,但在整个测试中是恒定的。
rbd_fio任务 - qa/tasks/fio.py。这使用fio生成对 rbd 图像卷的读取/写入 I/O
cbt任务 - qa/tasks/cbt.py。这使用 Ceph 基准测试工具cbt运行 fio 或 radosbench 来基准测试集群的性能。
rbd bench. 一些独立的测试使用 rbd benchrbd_pwl_cache_recovery任务。
使用这些工具获取非零(以及非条带对齐)偏移量的 I/O 到非主 OSD 的良好覆盖范围很困难,或者生成各种偏移量和 I/O 长度的 I/O 请求的广泛种类,包括块和条带的边界情况的所有情况。有改进 rados、radosbench 或 rbd bench 以便为测试擦除编码生成更有趣的 I/O 模式的余地。
对于上面描述的优化,我们需要有良好的工具来通过检查数据和编码奇偶校验是否一致来检查擦除编码中选定对象或所有对象在擦除编码池中的数据一致性。有一个测试工具ceph-erasure-code-tool它可以使用插件来对一组文件中的数据编码和解码。但是,似乎 teuthology 中没有任何脚本可以执行一致性检查,使用 objectstore tool 读取数据,然后使用此工具验证一致性。我们将编写一些 teuthology 辅助程序,使用 ceph-objectstore-tool 和 ceph-erasure-code-tool 执行离线验证。
我们还希望有一种在线方式来执行完整的完整性检查,无论是针对特定对象还是针对整个池。不幸的是,EC 池不支持类方法,因此无法将其用作执行完整一致性检查的方式。我们将调查在读取请求、池或实现一个新请求类型来对对象执行完整一致性检查,并研究扩展 rados CLI 以能够执行这些测试。另见下文深度清理的讨论。
当存在多个编码奇偶校验并且数据和编码奇偶校验之间存在不一致时,尝试分析不一致的原因很有用。由于多个编码奇偶校验提供了冗余,因此可以以多种方式重建每个块,这可以用来检测不一致的最可能原因。例如,对于 4+2 擦除编码和第一个数据 OSD 的丢失写入,条带(所有 6 个 OSD)将不一致,任何包含第一个数据 OSD 的 5 个 OSD 的选择也将不一致,但数据 OSD 2、3 和 4 以及两个编码奇偶校验 OSD 将仍然是一致的。虽然条带可能以许多方式进入这种状态,但工具可以得出结论,最可能的原因是错过了对 OSD 1 的更新。Ceph 没有执行此类分析的工具有,但应该很容易扩展 ceph-erasure-code-tool。
Teuthology 似乎具有足够的工具来将 OSD 离线和再次在线。有一些工具用于注入读取 I/O 错误(而无需将 OSD 离线),但改进这些工具的余地很大(例如指定对象中某个特定偏移量将导致读取失败,对设置和删除错误注入站点有更多控制)。
Teuthology 的总体理念似乎是随机注入故障,并通过蛮力获得所有错误路径的足够覆盖范围。这是一种很好的 CI 测试方法,但是当 EC 代码路径变得复杂,并且需要多个错误以精确的时间发生才能导致特定的代码路径执行时,如果没有运行很长时间的测试就很难获得覆盖范围。有一些 EC 独立的测试测试一些多重故障路径,但这些测试执行的 I/O 量非常有限,并且在 I/O 在飞行时没有注入故障,因此错过了一些有趣的场景。
为了处理这些更复杂的错误路径,我们建议开发一种专门针对擦除编码注入错误序列的新类型的 thrasher,并利用调试挂钩在特定点捕获和延迟 I/O 请求,以确保错误注入击中特定的定时窗口。为此,我们将扩展 tell osd 命令以包含额外的接口来注入错误并捕获和停滞特定点的 I/O。
擦除编码的一些部分,例如插件,是独立的代码片段,可以使用单元测试进行测试。已经有了一些擦除编码的单元测试和性能基准测试工具,我们将努力扩展这些工具以获得对可以单独运行的代码的进一步覆盖范围。
I/O路径更改
避免不必要的读取和写入
当前代码对于读取和覆盖 I/O 读取过多的数据。对于覆盖,它还会覆盖未修改的数据。这是因为在读取和覆盖被四舍五入为完整条带操作。当数据主要按顺序访问时这不是问题,但对于随机 I/O 操作非常浪费。可以通过仅读取/写入必要的分片来更改代码。为了使代码能够有效地支持较大的块大小 I/O,I/O 应该四舍五入为页面大小 I/O 而不是块大小 I/O。
第一组简单的优化消除了不必要的读取和不必要的写入数据,但保留了所有分片中元数据的写入。这避免了破坏当前设计,该设计依赖于所有分片接收每个事务的元数据更新。当元数据处理更改完成时(见下文),则可以进一步优化以减少元数据更新次数以获得额外节省。
奇偶校验-差分写入
当前代码通过执行完整条带读取、合并覆盖数据、计算新的编码奇偶校验并执行完整条带写入来实现覆盖。读取和写入每个分片很昂贵,可以应用一些优化来加快速度。对于 M 较小的 K+M 配置,执行奇偶校验增量写入通常更省力。这是通过读取即将被覆盖的旧数据并将其与新数据异或以创建增量来实现的。然后读取编码奇偶校验,更新以应用增量并重新写入。对于 M=2(RAID6),这可以导致仅 3 次读取和 3 次写入即可执行不到一个块的覆盖。
请注意,当条带中的大部分数据正在更新时,此技术可能导致比执行部分覆盖更多的工作,但如果同时支持这两种更新技术,则可以根据给定的 I/O 偏移量和长度很容易地计算出使用哪种技术是最佳的。
提交给主 OSD 的写入 I/O 将执行此计算以决定是使用完整条带更新还是奇偶校验增量写入。请注意,如果在执行奇偶校验增量写入期间遇到读取失败,并且需要重建数据或编码奇偶校验,那么切换到执行完整条带读取、合并和写入将更有效率。
并非所有擦除编码和擦除编码库都支持执行增量更新的功能,但是使用 XOR 和/或 GF 算术实现的那些应该支持。我们已经检查了 jerasure 和 isa-l,并确认它们支持此功能,尽管必要的 API 目前没有通过插件公开。对于某些擦除编码,例如 clay 和 lrc,可能可以应用增量更新,但是增量可能需要在许多地方应用,这使得这种优化变得没有价值。本提案建议最初仅对最常用的擦除编码实现奇偶校验增量写入优化。擦除编码插件将提供一个新标志,指示它们是否支持执行增量更新的新接口。
直接读取
读取 I/O 目前指向主 OSD,然后主 OSD 发出对其他分片的读取以获取和更新其他分片的数据。这是最简单的实现,但它使用了大量的网络带宽。使用奇偶校验增量写入,可以将处理分布在 OSD 上以减少网络带宽。
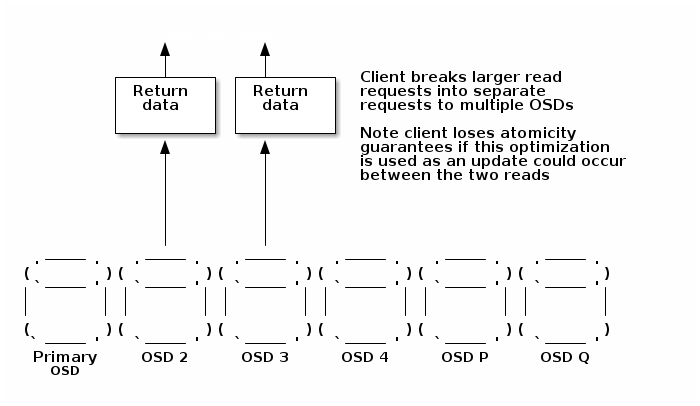
Direct reads will always be for <= one chunk. For reads of more than one chunk the client can issue direct reads to multiple OSDs, however these will no longer guaranteed to be atomic because an update (write) may be applied in between the separate read requests. If a client needs atomicity guarantees they will need to continue to send the read to the primary.
Direct reads will be failed with EAGAIN where a reconstruct and decode operation is required to return the data. This means only reads to primary OSD will need to handle the reconstruct code path. When an OSD is backfilling we don’t want the client to have large quantities of I/O failed with EAGAIN, therefore we will make the client detect this situation and avoid issuing direct I/Os to a backfilling OSD.
For backwards compatibility, for client requests that cannot cope with the reduced guarantees of a direct read, and for scenarios where the direct read would be to an OSD that is absent or backfilling, reads directed to the primary OSD will still be supported.
直接写入
Write I/Os are currently directed to the primary OSD which then updates the other shards. To reduce latency and network bandwidth it would be better if clients could direct small overwrites requests directly to the OSD storing the data, rather than via the primary. For larger write I/Os and for error scenarios and abnormal cases clients will continue to submit write I/Os to the primary OSD.
Direct writes will always be for <= one chunk and will use the parity-delta-write technique to perform the update. For medium sized writes a client may issue direct writes to multiple OSDs, but such updates will no longer be guaranteed to be atomic. If a client requires atomicity for a larger write they will need to continue to send it to the primary.
For backwards compatibility, and for scenarios where the direct write would be to an OSD that is absent, writes directed to the primary OSD will still be supported.
I/O序列化、恢复/填充和其他错误场景
Direct writes look fairly simple until you start considering all the abnormal scenarios. The current implementation of processing all writes on the Primary OSD means that there is one central point of control for the stripe that can manage things like the ordering of multiple inflight I/Os to the same stripe, ensuring that recovery/backfill for an object has been completed before it is accessed and assigning the object version number and modification time.
With direct I/Os these become distributed problems. Our approach is to send a control path message to the Primary OSD and let it continue to be the central point of control. The Primary OSD will issue a reply when the OSD can start the direct write and will be informed with another message when the I/O has completed. See section below on metadata updates for more details.
带宽缓存
Erasure code pools maintain a stripe cache which stores shard data while updates are in progress. This is required to allow writes and reads to the same stripe to be processed in parallel. For small sequential write workloads and for extreme hot spots (e.g. where the same block is repeatedly re-written for some kind of crude checkpointing mechanism) there would be a benefit in keeping the stripe cache slightly longer than the duration of the I/O. In particularly the coding parities are typically read and written for every update to a stripe. There is obviously a balancing act to achieve between keeping the cache long enough that it reduces the overheads for future I/Os versus the memory overheads of storing this data. A small (MiB as opposed to GiB sized cache) should be sufficient for most workloads. The stripe cache can also help reduce latency for direct write I/Os by allowing prefetch I/Os to read old data and coding parities ready for later parts of the write operation without requiring more complex interlocks.
The stripe cache is less important when the default chunk size is small (e.g. 4K), because even with small write I/O requests there will not be many sequential updates to fill a stripe. With a larger chunk size (e.g. 64K) the benefits of a good stripe cache become more significant because the stripe size will be 100’s KiB to small number of MiB’s and hence it becomes much more likely that a sequential workload will issue many I/Os to the same stripe.
自动选择块大小
The default chunk size of 4K is good for small objects because the data and coding parities are rounded up to whole chunks and because if an object has less than one data stripe of data then the capacity overheads for the coding parities are higher (e.g. a 4K object in a 10+2 erasure coded pool has 4K of data and 8K of coding parity, so there is a 200% overhead). However the optimizations above all provide much bigger savings if the typical random access I/O only reads or writes a single shard. This means that so long as objects are big enough that a larger chunk size such as 64K would be better.
Whilst the user can try and predict what their typically object size will be and choose an appropriate chunk size, it would be better if the code could automatically select a small chunk size for small objects and a larger chunk size for larger objects. There will always be scenarios where an object grows (or is truncated) and the chosen chunk size becomes inappropriate, however reading and re-writing the object with a new chunk size when this happens won’t have that much performance impact. This also means that the chunk size can be deduced from the object size in object_info_t which is read before the objects data is read/modified. Clients already provide a hint as to the object size when creating the object so this could be used to select a chunk size to reduce the likelihood of having to re-stripe an object
The thought is to support a new chunk size of auto/variable to enable this feature, it will only be applicable for newly created pools, there will be no way to migrate an existing pool.
深度刷写支持
EC Pools with overwrite do not check CRCs because it is too costly to update the CRC for the object on every overwrite, instead the code relies on Bluestore to maintain and check CRCs. When an EC pool is operating with overwrite disabled a CRC is kept for each shard, because it is possible to update CRCs as the object is appended to just by calculating a CRC for the new data being appended and then doing a simple (quick) calculation to combine the old and new CRC together.
In dev/osd_internals/erasure_coding/proposals.rst it discusses the possibility of keeping CRCs at a finer granularity (for example per chunk), storing these either as an xattr or an omap (omap is more suitable as large objects could end up with a lot of CRC metadata) and updating these CRCs when data is overwritten (the update would need to perform a read-modify-write at the same granularity as the CRC). These finer granularity CRCs can then easily be combined to produce a CRC for the whole shard or even the whole erasure coded object.
This proposal suggests going in the opposite direction - EC overwrite pools have survived without CRCs and relied on Bluestore up until now, so why is this feature needed? The current code doesn’t check CRCs if overwrite is enabled, but sadly still calculates and updates a CRC in the hinfo xattr, even if performing overwrites which mean that the calculated value will be garbage. This means we pay all the overheads of calculating the CRC and get no benefits.
The code can easily be fixed so that CRCs are calculated and maintained when objects are written sequentially, but as soon as the first overwrite to an object occurs the hinfo xattr will be discarded and CRCs will no longer be calculated or checked. This will improve performance when objects are overwritten, and will improve data integrity in cases where they are not.
While the thought is to abandon EC storing CRCs in objects being overwritten, there is an improvement that can be made to deep scrub. Currently deep scrub of an EC with overwrite pool just checks that every shard can read the object, there is no checking to verify that the copies on the shards are consistent. A full consistency check would require large data transfers between the shards so that the coding parities could be recalculated and compared with the stored versions, in most cases this would be unacceptably slow. However for many erasure codes (including the default ones used by Ceph) if the contents of a chunk are XOR’d together to produce a longitudinal summary value, then an encoding of the longitudinal summary values of each data shard should produce the same longitudinal summary values as are stored by the coding parity shards. This comparison is less expensive than the CRC checks performed by replication pools. There is a risk that by XORing the contents of a chunk together that a set of corruptions cancel each other out, but this level of check is better than no check and will be very successful at detecting a dropped write which will be the most common type of corruption.
元数据更改
What metadata do we need to consider?
object_info_t. Every Ceph object has some metadata stored in the object_info_t data structure. Some of these fields (e.g. object length) are not updated frequently and we can simply avoid performing partial writes optimizations when these fields need updating. The more problematic fields are the version numbers and the last modification time which are updated on every write. Version numbers of objects are compared to version numbers in PG log entries for peering/recovery and with version numbers on other shards for backfill. Version numbers and modification times can be read by clients.
PG log entries. The PG log is used to track inflight transactions and to allow incomplete transactions to be rolled forward/backwards after an outage/network glitch. The PG log is also used to detect and resolve duplicate requests (e.g. resent due to network glitch) from clients. Peering currently assumes that every shard has a copy of the log and that this is updated for every transaction.
PG stats entries and other PG metadata. There is other PG metadata (PG stats is the simplest example) that gets updated on every transaction. Currently all OSDs retain a cached and a persistent copy of this metadata.
需要多少份元数据副本?
The current implementation keeps K+M replicated copies of metadata, one copy on each shard. The minimum number of copies that need to be kept to support up to M failures is M+1. In theory metadata could be erasure encoded, however given that it is small it is probably not worth the effort. One advantage of keeping K+M replicated copies of the metadata is that any fully in sync shard can read the local copy of metadata, avoiding the need for inter-OSD messages and asynchronous code paths. Specifically this means that any OSD not performing backfill can become the primary and can access metadata such as object_info_t locally.
M+1任意分布副本
A partial write to one data shard will always involve updates to the data shard and all M coding parity shards, therefore for optimal performance it would be ideal if the same M+1 shards are updated to track the associated metadata update. This means that for small random writes that a different M+1 shards would get updated for each write. The drawback of this approach is that you might need to read K shards to find the most up to date version of the metadata.
In this design no shard will have an up to date copy of the metadata for every object. This means that whatever shard is picked to be the acting primary that it may not have all the metadata available locally and may need to send messages to other OSDs to read it. This would add significant extra complexity to the PG code and cause divergence between Erasure coded pools and Replicated pools. For these reasons we discount this design option.
M+1已知分片副本
The next best performance can be achieved by always applying metadata updates to the same M+1 shards, for example choosing the 1st data shard and all M coding parity shards. Coding parity shards will get updated by every partial write so this will result in zero or one extra shard being updated. With this approach only 1 shard needs to be read to find the most up to date version of the metadata.
We can restrict the acting primary to be one of the M+1 shards, which means that once any incomplete updates in the log have been resolved that the primary will have an up to date local copy of all the metadata, this means that much more of the PG code can be kept unchanged.
部分写入和PG日志
Peering currently assumes that every shard has a copy of the log, however because of inflight updates and small term absences it is possible that some shards are missing some of the log entries. The job of peering is to combine the logs from the set of present shards to form a definitive log of transactions that have been committed by all the shards. Any discrepancies between a shards log and the definitive log are then resolved, typically by rolling backwards transactions (using information held in the log entry) so that all the shards are in a consistent state.
To support partial writes the log entry needs to be modified to include the set of shards that are being updated. Peering needs to be modified to consider a log entry as missing from a shard only if a copy of the log entry on another shard indicates that this shard was meant to be updated.
The logs are not infinite in size, and old log entries where it is known that the update has been successfully committed on all affected shards are trimmed. Log entries are first condensed to a pg_log_dup_t entry which can no longer assist in rollback of a transaction but can still be used to detect duplicated client requests, and then later completely discarded. Log trimming is performed at the same time as adding a new log entry, typically when a future write updates the log. With partial writes log trimming will only occur on shards that receive updates, which means that some shards may have stale log entries that should have been discarded.
TBD: I think the code can already cope with discrepancies in log trimming between the shards. Clearly an in flight trim operation may not have completed on every shard so small discrepancies can be dealt with, but I think an absent OSD can cause larger discrepancies. I believe that this is resolved during Peering, with each OSD keeping a record of what the oldest log entry should be and this gets shared between OSDs so that they can work out stale log entries that were trimmed in absentia. Hopefully this means that only sending log trimming updates to shards that are creating new log entries will work without code changes.
填充
Backfill is used to correct inconsistencies between OSDs that occur when an OSD is absent for a longer period of time and the PG log entries have been trimmed. Backfill works by comparing object versions between shards. If some shards have out of date versions of an object then a reconstruct is performed by the backfill process to update the shard. If the version numbers on objects are not updated on all shards then this will break the backfill process and cause a huge amount of unnecessary reconstruct work. This is unacceptable, in particular for the scenario where an OSD is just absent for maintenance for a relatively short time with noout set. The requirement is to be able to minimize the amount of reconstruct work needed to complete a backfill.
In dev/osd_internals/erasure_coding/proposals.rst it discusses the idea of each shard storing a vector of version numbers that records the most recent update that the pair <this shard, other shard> both should have participated in. By collecting this information from at least M shards it is possible to work out what the expected minimum version number should be for an object on a shard and hence deduce whether a backfill is required to update the object. The drawback of this approach is that backfill will need to scan M shards to collect this information, compared with the current implementation that only scans the primary and shard(s) being backfilled.
With the additional constraint that a known M+1 shards will always be updated and that the (acting) primary will be one of these shards, it will be possible to determine whether a backfill is required just by examining the vector on the primary and the object version on the shard being backfilled. If the backfill target is one of the M+1 shards the existing version number comparison is sufficient, if it is another shard then the version in the vector on the primary needs to be compared with the version on the backfill target. This means that backfill does not have to scan any more shards than it currently does, however the scan of the primary does need to read the vector and if there are multiple backfill targets then it may need to store multiple entries of the vector per object increasing memory usage during the backfill.
There is only a requirement to keep the vector on the M+1 shards, and the vector only needs K-1 entires because we only need to track version number differences between any of the M+1 shards (which should have the same version) and each of the K-1 shards (which can have a stale version number). This will slightly reduce the amount of extra metadata required. The vector of version numbers could be stored in the object_info_t structure or stored as a separate attribute.
Our preference is to store the vector in the object_info_t structure because typically both are accessed together, and because this makes it easier to cache both in the same object cache. We will keep metadata and memory overheads low by only storing the vector when it is needed.
Care is required to ensure that existing clusters can be upgraded. The absence of the vector of version numbers implies that an object has never had a partial update and therefore all shards are expected to have the same version number for the object and the existing backfill algorithm can be used.
代码引用
PrimaryLogPG::scan_range - this function creates a map of objects and their version numbers, on the primary it tries to get this information from the object cache, otherwise it reads to OI attribute. This will need changes to deal with the vectors. To conserve memory it will need to be provided with the set of backfill targets so it can select which part of the vector to keep.
PrimaryLogPG::recover_backfill - this function call scan_range for the local (primary) and sends MOSDPGScan to the backfill targets to get them to perform the same scan. Once it has collected all the version numbers it compares the primary and backfill targets to work out which objects need to be recovered. This will also need changes to deal with the vectors when comparing version numbers.
PGBackend::run_recovery_op - recovers a single object. For an EC pool this involves reconstructing the data for the shards that need backfilling (read other shards and use decode to recover). This code shouldn’t need any changes.
客户端版本号和最后修改时间
Clients can read the object version number and set expectations about what the minimum version number is when making updates. Clients can also read the last modification time. There are use cases where it is important that these values can be read and give consistent results, but there is also a large number of scenarios where this information is not required.
If the object version number is only being updated on a known M+1 shards for partial writes, then where this information is required it will need to involve a metadata access to one of those shards. We have arranged for the primary to be one of the M+1 shards so I/Os submitted to the primary will always have access to the up to date information.
Direct write I/Os need to update the M+1 shards, so it is not difficult to also return this information to the client when completing the I/O.
Direct read I/Os are the problem case, these will only access the local shard and will not necessarily have access to the latest version and modification time. For simplicity we will require clients that require this information to send requests to the primary rather than using the direct I/O optimization. Where a client does not need this information they can use the direct I/O optimizations.
The direct read I/O optimization will still return a (potentially stale) object version number. This may still be of use to clients to help understand the ordering of I/Os to a chunk.
带元数据更新的直接写入
Here’s the full picture of what a direct write performing a parity-delta-write looks like with all the control messages:
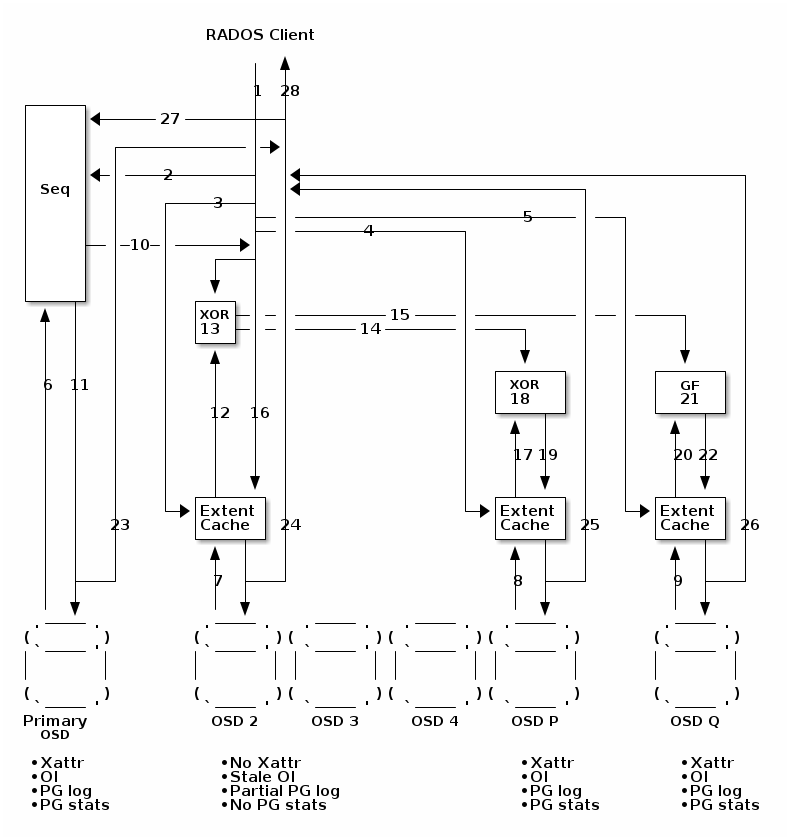
Note: Only the primary OSD and parity coding OSDs (the M+1 shards) have Xattr, up to date object info, PG log and PG stats. Only one of these OSDs is permitted to become the (acting) primary. The other data OSDs 2,3 and 4 (the K-1 shards) do not have Xattrs or PG stats, may have state object info and only have PG log entries for their own updates. OSDs 2,3 and 4 may have stale OI with an old version number. The other OSDs have the latest OI and a vector with the expected version numbers for OSDs 2,3 and 4.
Data message with Write I/O from client (MOSDOp)
Control message to Primary with Xattr (new msg MOSDEcSubOpSequence)
Note: the primary needs to be told about any xattr update so it can update its copy, but the main purpose of this message is to allow the primary to sequence the write I/O. The reply message at step 10 is what allows the write to start and provides the PG stats and new object info including the new version number. If necessary the primary can delay this to ensure that recovery/backfill of the object is completed first and deal with overlapping writes. Data may be read (prefetched) before the reply, but obviously no transactions can start.
Prefetch request to local extent cache
Control message to P to prefetch to extent cache (new msg MOSDEcSubOpPrefetch equivalent of MOSDEcSubOpRead)
Control message to Q to prefetch to extent cache (new msg MOSDEcSubOpPrefetch equivalent of MOSDEcSubOpRead)
Primary reads object info
Prefetch old data
Prefetch old P
Prefetch old Q
Note: The objective of these prefetches is to get the old data, P and Q reads started as quickly as possible to reduce the latency of the whole I/O. There may be error scenarios where the extent cache is not able to retain this and it will need to be re-read. This includes the rare/pathological scenarios where there is a mixture of writes sent to the primary and writes sent directly to the data OSD for the same object.
Control message to data OSD with new object info + PG stats (new msg MOSDEcSubOpSequenceReply)
Transaction to update object info + PG log + PG stats
Fetch old data (hopefully cached)
Note: For best performance we want to pipeline writes to the same stripe. The primary assigns the version number to each write and consequently defines the order in which writes should be processed. It is important that the data shard and the coding parity shards apply overlapping writes in the same order. The primary knows what set of writes are in flight so can detect this situation and indicate in its reply message at step 10 that an update must wait until an earlier update has been applied. This information needs to be forwarded to the coding parities (steps 14 and 15) so they can also ensure updates are applied in the same order.
XOR new and old data to create delta
Data message to P with delta + Xattr + object info + PG log + PG stats (new msg MOSDEcSubOpDelta equivalent of MOSDEcSubOpWrite)
Data message to Q with delta + Xattr + object info + PG log + PG stats (new msg MOSDEcSubOpDelta equivalent of MOSDEcSubOpWrite)
Transaction to update data + object info + PG log
Fetch old P (hopefully cached)
XOR delta and old P to create new P
Transaction to update P + Xattr + object info + PG log + PG stats
Fetch old Q (hopefully cached)
XOR delta and old Q to create new Q
Transaction to update Q + Xattr + object info + PG log + PG stats
Control message to data OSD for commit (new msg MOSDEcSubOpDeltaReply equivalent of MOSDEcSubOpWriteReply)
Local commit notification
Control message to data OSD for commit (new msg MOSDEcSubOpDeltaReply equivalent of MOSDEcSubOpWriteReply)
Control message to data OSD for commit (new msg MOSDEcSubOpDeltaReply equivalent of MOSDEcSubOpWriteReply)
Control message to Primary to signal end of write (variant of new msg MOSDEcSubOpSequence)
Control message reply to client (MOSDOpReply)
升级和向后兼容性
A few of the optimizations can be made just by changing code on the primary OSD with no backwards compatibility concerns regarding clients or the other OSDs. These optimizations will be enabled as soon as the primary OSD upgrades and will replace the existing code paths.
The remainder of the changes will be new I/O code paths that will exist alongside the existing code paths.
Similar to EC Overwrites many of the changes will need to ensure that all OSDs are running new code and that the EC plugins support new interfaces required for parity-delta-writes. A new pool level flag will be required to enforce this. It will be possible to enable this flag (and hence enable the new performance optimizations) after upgrading an existing cluster. Once set it will not be possible to add down level OSDs to the pool. It will not be possible to turn this flag off other than by deleting the pool. Downgrade is not supported because:
It is not trivial to quiesce all I/O to a pool to ensure that none of the new I/O code paths are in use when the flag is cleared.
The PG log format for new I/Os will not be understood by down level OSDs. It would be necessary to ensure the log has been trimmed of all new format entries before clearing the flag to ensure that down level OSDs will be able to interpret the log.
Additional xattr data will be stored by the new I/O code paths and used by backfill. Down level code will not understand how to backfill a pool that has been running the new I/O paths and will get confused by the inconsistent object version numbers. While it is theoretically possible to disable partial updates and then scan and update all the metadata to return the pool to a state where a downgrade is possible, we have no intention of writing this code.
The direct I/O changes will additionally require clients to be running new code. These will require that the pool has the new flag set and that a new client is used. Old clients can use pools with the new flag set, just without the direct I/O optimization.
不在考虑范围内
There is a list of enhancements discussed in doc/dev/osd_internals/erasure_coding/proposals.rst, the following are not under consideration:
RADOS Client Acknowledgement Generation optimization
When updating K+M shards in an erasure coded pool, in theory you don’t have to wait for all the updates to complete before completing the update to the client, because so long as K updates have completed any viable subset of shards should be able to roll forward the update.
For partial writes where only M+1 shards are updated this optimization does not apply as all M+1 updates need to complete before the update is completed to the client.
This optimization would require changes to the peering code to work out whether partially completed updates need to be rolled forwards or backwards. To roll an update forwards it would be simplest to mark the object as missing and use the recovery path to reconstruct and push the update to OSDs that are behind.
Avoid sending read request to local OSD via Messenger
The EC backend code has an optimization for writes to the local OSD which avoids sending a message and reply via messenger. The equivalent optimization could be made for reads as well, although a bit more care is required because the read is synchronous and will block the thread waiting for the I/O to complete.
Pull request https://github.com/ceph/ceph/pull/57237 is making this optimization
故事
This is our high level breakdown of the work. Our intention is to deliver this work as a series of PRs. The stories are roughly in the order we plan to develop. Each story is at least one PR, where possible they will be broken up further. The earlier stories can be implemented as stand alone pieces of work and will not introduce upgrade/backwards compatibility issues. The later stories will start breaking backwards compatibility, here we plan to add a new flag to the pool to enable these new features. Initially this will be an experimental flag while the later stories are developed.
测试工具 - 用于测试嵌入码的增强I/O生成器
Extend rados bench to be able to generate more interesting patterns of I/O for erasure coding, in particular reading and writing at different offsets and for different lengths and making sure we get good coverage of boundary conditions such as the sub-chunk size, chunk size and stripe size
Improve data integrity checking by using a seed to generate data patterns and remembering which seed is used for each block that is written so that data can later be validated
测试工具 - 离线一致性检查工具
Test tools for performing offline consistency checks combining use of objectstore_tool with ceph-erasure-code-tool
Enhance some of the teuthology standalone erasure code checks to use this tool
测试工具 - 在线一致性检查工具
New CLI to be able to perform online consistency checking for an object or a range of objects that reads all the data and coding parity shards and re-encodes the data to validate the coding parities
JErasure切换到ISA-L
The JErasure library has not been updated since 2014, the ISA-L library is maintained and exploits newer instructions sets (e.g. AVX512, AVX2) which provides faster encoding/decoding
Change defaults to ISA-L in upstream ceph
Benchmark Jerasure and ISA-L
Refactor Ceph isa_encode region_xor() to use AVX when M=1
Documentation updates
Present results at performance weekly
子带读取
Ceph currently reads an integer number of stripes and discards unneeded data. In particular for small random reads it will be more efficient to just read the required data
Help finish Pull Request https://github.com/ceph/ceph/pull/55196 if not already complete
Further changes to issue sub-chunk reads rather than full-chunk reads
简单优化覆盖
Ceph overwrites currently read an integer number of stripes, merge the new data and write an integer number of stripes. This story makes simple improvements by making the same optimizations as for sub stripe reads and for small (sub-chunk) updates reducing the amount of data being read/written to each shard.
Only read chunks that are not being fully overwritten (code currently reads whole stripe and then merges new data)
Perform sub-chunk reads for sub-chunk updates
Perform sub-chunk writes for sub-chunk updates
消除不必要的块写入但保留元数据事务
This story avoids re-writing data that has not been modified. A transaction is still applied to every OSD to update object metadata, the PG log and PG stats.
Continue to create transactions for all chunks but without the new write data
Add sub-chunk writes to transactions where data is being modified
避免将对象填充到完整带
Objects are rounded up to an integer number of stripes by adding zero padding. These buffers of zeros are then sent in messages to other OSDs and written to the OS consuming storage. This story make optimizations to remove the need for this padding
Modifications to reconstruct reads to avoid reading zero-padding at the end of an object - just fill the read buffer with zeros instead
Avoid transfers/writes of buffers of zero padding. Still send transactions to all shards and create the object, just don’t populate it with zeros
Modifications to encode/decode functions to avoid having to pass in buffers of zeros when objects are padded
嵌入码插件更改以支持分布式部分写入
这是为未来的故事做准备的工作,它为擦除编码插件添加了新的 API。
添加一个新的接口,通过 XOR 旧数据和新数据来创建增量,并为此实现 ISA-L 和 JErasure 插件
添加一个新的接口,通过使用 XOR/GF 将增量应用于一个编码奇偶校验,并为此实现 ISA-L 和 JErasure 插件
添加一个新的接口,报告哪些擦除编码支持此功能(ISA-L 和 JErasure 将支持它,其他不会)
嵌入码接口允许RADOS客户端将I/Os直接写入存储数据的OSD
这是为未来的故事做准备的工作,它为客户端添加了一个新的 API。
新接口将(pg, 偏移量)对转换为 {OSD, 剩余块长度}
我们不希望客户端必须动态链接到擦除编码插件,因此此代码需要是 librados 的一部分。但是,此接口需要了解擦除编码如何将数据块和编码块分配给 OSD 以执行此转换。
我们将仅支持 ISA-L 和 JErasure 插件,其中数据块到 OSD 的分布非常简单,以便能够执行此转换。
对object_info_t的更改
这是为未来的故事做准备的工作。
这添加了 object_info_t 中的版本号向量,它将用于部分更新。对于复制池和未覆盖的擦除编码对象,我们将避免在 object_info_t 中存储额外数据。
对PGLog和Peering的更改以支持更新部分OSD
这是为未来的故事做准备的工作。
修改 PG 日志条目以存储正在更新的 OSD 的记录
修改对等以使用此额外数据来确定缺少更新的 OSD
对(行动)主选择更改
这是为未来的故事做准备的工作。
将主选择限制为第一个数据 OSD 或擦除编码奇偶校验之一。如果这些 OSD 都不可用并且是最新的,则池必须离线。
在主上执行所有计算以实现奇偶校验-差分写入
计算更新执行完整条带覆盖或奇偶校验增量写入是否更有效率
实现新的代码路径来执行奇偶校验增量写入
测试工具增强。我们希望确保奇偶校验增量写入和完整条带写入都经过测试。我们将添加一个新的配置文件选项,提供“奇偶校验增量”、“完整条带”、“测试用例的混合”或“自动”的选择,并更新 teuthology 测试用例,主要使用混合。
升级和向后兼容性
添加一个新的功能标志用于擦除编码池
所有 OSD 必须运行新代码才能在池上启用该标志
客户端可能仅发出直接 I/O 如果设置了标志
运行旧代码的 OSD 可能无法加入设置了标志的池
不可能关闭功能标志(除了通过删除池)
更改Backfill以使用object_info_t中的向量
这是为未来的故事做准备的工作。
修改回填过程以使用 object_info_t 中的版本号向量,以便在发生部分更新时我们不会回填未参与部分更新的 OSD。
当只有一个回填目标时,从向量中提取适当的版本号(不需要额外的存储)
当有多个回填目标时,提取回填目标所需的向量子集,并在比较 PrimaryLogPG::recover_backfill 中的版本号时选择适当的条目
测试工具 - 离线元数据验证工具
执行离线完整性检查的测试工具,特别是检查 object_info_t 中的版本号向量是否与每个 OSD 上的版本号匹配,但对于验证 PG 日志条目也适用。
消除未更新数据块的OSD上的事务
对等、日志恢复和回填现在都可以使用 object_info_t 中的版本号向量来处理部分更新。
修改覆盖 I/O 路径以避免仅处理元数据(除了主 OSD)
修改 object_info_t 中版本号的生成方式以使用向量和仅更新接收事务的条目。
修改 PG 日志条目的生成
直接读取到OSD(仅单个块)
修改 OSDClient 以将单个块读取 I/O 路由到存储数据的 OSD。
修改 OSD 以接受来自非主 OSD 的读取(扩展现有更改以与 EC 池一起工作)
如果 OSD 无法直接处理读取,则必要时用 EAGAIN 失败读取。
修改 OSDClient 以在读取失败时通过提交给主 OSD 来重试读取。
测试工具增强。我们希望确保直接读取和读取主 OSD 都经过测试。我们将添加一个新的配置文件选项,提供“优先直接”、“仅主”或“测试用例的混合”的选择,并更新 teuthology 测试用例,主要使用混合。
这些更改将修改 RADOS 客户端的一部分,因此也适用于 rbd、rgw 和 cephfs。
我们不会更改具有自己版本 RADOS 客户端代码的其他代码,例如 krbd,尽管将来可以这样做。
直接读取到OSD(多个块)
添加一个新的 OSDC 标志 NONATOMIC,允许 OSDC 将读取分成多个请求。
修改 OSDC 以在设置 NONATOMIC 标志时将跨越多个块的读取分成对每个 OSD 的单独请求。
对 OSDC 进行修改以合并结果(如果任何子读取失败,则整个读取需要失败)
对 librbd 客户端进行更改以设置读取的 NONATOMIC 标志
对 cephfs 客户端进行更改以设置读取的 NONATOMIC 标志
我们只更改了一组非常有限的客户端,重点关注那些发出较小读取并对延迟敏感的客户端。未来的工作可以考虑扩展客户端集(包括 krbd)。
实现分布式奇偶校验-差分写入
实现一种新的消息类型 MOSDEcSubOpDelta 和 MOSDEcSubOpDeltaReply
修改主 OSD 以计算增量并发送 MOSDEcSubOpDelta 消息到编码奇偶校验 OSD。
修改编码奇偶校验 OSD 以应用增量并发送 MOSDEcSubOpDeltaReply 消息。
注意:此更改将增加延迟,因为编码奇偶校验读取在旧数据读取之后开始。未来的工作将修复此问题。
测试工具 - EC错误注入thrasher
实现一种专门针对擦除编码注入错误的新类型的 thrasher。
将一个或多个(最多 M 个)OSD 降级,更多关注于将不同的 OSD 子集降级,以驱动所有不同的 EC 恢复路径,而不是压力对等/恢复/回填(现有的 OSD thrasher 在这方面很出色)。
注入读取 I/O 错误以强制使用解码进行单个和多个失败的重构。
使用 osd tell 类型接口注入延迟以更容易地测试 OSD 在 EC I/O 的所有有趣阶段的降级。
使用 osd tell 类型接口注入延迟以减慢 OSD 事务或消息,以暴露并行工作的不太常见的完成顺序。
实现预取消息MOSDEcSubOpPrefetch并修改范围缓存
实现新的消息 MOSDEcSubOpPrefetch
修改主 OSD 以在开始读取旧数据之前向编码奇偶校验 OSD 发送此消息。
修改范围缓存,以便每个 OSD 都缓存自己的数据,而不是在主 OSD 上缓存所有内容。
修改编码奇偶校验 OSD 以处理此消息并读取旧编码奇偶校验到范围缓存中。
对范围缓存进行更改,以便在收到 MOSDEcSubOpDelta 消息之前保留预取的旧奇偶校验,并在错误路径上丢弃此内容(例如新的 OSDMap)。
实现排序消息MOSDEcSubOpSequence
实现对编码/解码函数的修改,以避免在对象填充时需要传递包含零的缓冲区。
Modify primary code to create these messages and route them locally to itself in preparation for direct writes
直接写入到OSD(仅单个块)
Modify OSDC to route single chunk write I/Os to the OSD storing the data
Changes to issue MOSDEcSubOpSequence and MOSDEcSubOpSequenceReply between data OSD and primary OSD
直接写入到OSD(多个块)
Modifications to OSDC to split multiple chunk writes into separate requests if NONATOMIC flag is set
Further changes to coalescing completions (in particular reporting version number correctly)
对 librbd 客户端进行更改以设置读取的 NONATOMIC 标志
对 cephfs 客户端进行更改以设置读取的 NONATOMIC 标志
We are only changing a very limited set of clients, focusing on those that issue smaller writes and are latency sensitive. Future work could look at extending the set of clients.
深度刷写/CRC
Disable CRC generation in the EC code for overwrites, delete hinfo Xattr when first overwrite occurs
For objects in pool with new feature flag set that have not been overwritten check CRC, even if pool overwrite flag is set. The presence/absence of hinfo can be used to determine if the object has been overwritten
For deep scrub requests XOR the contents of the shard to create a longitudinal check (8 bytes wide?)
Return the longitudinal check in the scrub reply message, have the primary encode the set of longitudinal replies to check for inconsistencies
可变块大小嵌入码
Implement new pool option for automatic/variable chunk size
When object size is small use a small chunk size (4K) when the pool is using the new option
When object size is large use a large chunk size (64K or 256K?)
Convert the chunk size by reading and re-writing the whole object when a small object grows (append)
Convert the chunk size by reading and re-writing the whole object when a large object shrinks (truncate)
Use the object size hint to avoid creating small objects and then almost immediately converting them to a larger chunk size
CLAY嵌入码
In theory CLAY erasure codes should be good for K+M erasure codes with larger values of M, in particular when these erasure codes are used with multiple OSDs in the same failure domain (e.g. an 8+6 erasure code with 5 servers each with 4 OSDs). We would like to improve the test coverage for CLAY and perform some more benchmarking to collect data to help substantiate when people should consider using CLAY.
Benchmark CLAY erasure codes - in particular the number of I/O required for backfills when multiple OSDs fail
Enhance test cases to validate the implementation
由 Ceph 基金会带给您
Ceph 文档是一个社区资源,由非盈利的 Ceph 基金会资助和托管Ceph Foundation. 如果您想支持这一点和我们的其他工作,请考虑加入现在加入.