注意
本文档适用于 Ceph 的开发版本。
架构
Cephuniquely deliversobject, block, and file storagein oneCeph Nodeleverages commodity hardware andCeph 存储集群accommodates large
Ceph 存储集群
Ceph provides an infinitely scalableCeph 存储集群based uponRADOS, a reliable,clients. SeeThe RADOS Object Store” blogRADOS - A Scalable, Reliablefor an exhaustiveRADOS.
A Ceph Storage Cluster consists of multiple types of daemons:
Ceph Monitors maintain the master copy of the cluster map, which they provide
A Ceph OSD Daemon checks its own state and the state of other OSDs and reports
A Ceph Manager serves as an endpoint for monitoring, orchestration, and plug-in
A Ceph Metadata Server (MDS) manages file metadata when CephFS is used to
Storage cluster clients andCeph OSD Daemons use the CRUSH algorithmlibradosand a number of service interfaces built on top oflibrados.
存储数据
The Ceph Storage Cluster receives data fromCeph Clients--whether itCeph 块设备, Ceph 对象存储, theCeph 文件系统, or a custom implementation that you create by usinglibrados. The data received by the Ceph Storage Cluster is stored as RADOSObject Storage Device(this is
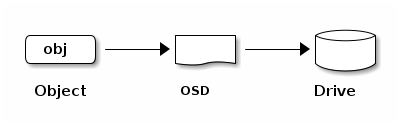
Ceph OSD Daemons store data as objects in a flat namespace. This means thatCeph Clients determine the semantics of the object data. For example,

注意
An object ID is unique across the entire cluster, not just the local
可扩展性和高可用性
In traditional architectures, clients talk to a centralized component. This
Ceph eliminates this centralized component. This enables clients to interactCRUSH.
CRUSH 简介
Ceph Clients and Ceph OSD Daemons both use theCRUSHalgorithm to compute information aboutCRUSH - Controlled,.
集群映射
In order for a Ceph cluster to function properly, Ceph Clients and Ceph OSDs
The Monitor Map:Contains the cluster
fsid, the position, the name,ceph mon dump.The OSD Map:Contains the cluster
fsid, the time of the OSD map’sup,in). To view an OSD map, runceph osd dump.The PG Map:Contains the PG version, its time stamp, the last OSD map上集, the行动集, the state of the PG (for
active + clean), and data usage statistics for each pool.The CRUSH Map:Contains a list of storage devices, the failure domain
device,host,rack,row,room),ceph osd getcrushmap -o {filename}and then decompile it bycrushtool -d {comp-crushmap-filename} -o {decomp-crushmap-filename}. Use a text editor orcatto view theThe MDS Map:Contains the current MDS map epoch, when the map was
up和in. To view MDS map, executeceph fs dump.
Each map maintains a history of changes to its operating state. Ceph Monitors
高可用性监视器
A Ceph Client must contact a Ceph Monitor and obtain a current copy of the
It is possible for a Ceph cluster to function properly with only a single
Ceph leverages a cluster of monitors in order to increase reliability and faultPaxosalgorithm and a
See theMonitor Config Referencefor more detail on configuring monitors.
高可用性认证
9b591a: Ceph 对象存储 9dbb5f: (又名 RGW)服务提供与 Amazon S3 和 OpenStack Swift 兼容的 RESTful API 接口。cephxauthentication system is used by Ceph to authenticate users and
注意
9b591a: Ceph 对象存储 9dbb5f: (又名 RGW)服务提供与 Amazon S3 和 OpenStack Swift 兼容的 RESTful API 接口。cephxprotocol does not address data encryption in transport
cephxuses shared secret keys for authentication. This means that both the
9b591a: Ceph 对象存储 9dbb5f: (又名 RGW)服务提供与 Amazon S3 和 OpenStack Swift 兼容的 RESTful API 接口。cephxprotocol makes it possible for each party to prove to the other
As stated in可扩展性和高可用性, Ceph does not have any centralizedcephxauthentication system establishes and sustains these
9b591a: Ceph 对象存储 9dbb5f: (又名 RGW)服务提供与 Amazon S3 和 OpenStack Swift 兼容的 RESTful API 接口。cephxprotocol operates in a manner similar toKerberos.
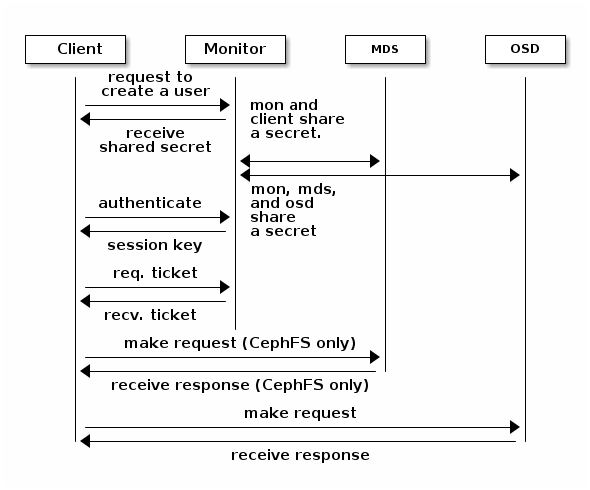
A user invokes a Ceph client to contact a monitor. Unlike Kerberos, eachcephx. The monitor
Like Kerberos tickets,cephxtickets expire. An attacker cannot use an
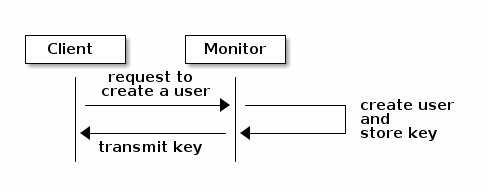
An administrator must set up users before using cephx. In the following
diagram, the client.admin user invokes ceph auth get-or-create-key from
the command line to generate a username and secret key. Ceph’s auth
subsystem generates the username and key, stores a copy on the monitor(s), and
transmits the user’s secret back to the client.admin user. This means that
the client and the monitor share a secret key.
注意
9b591a: Ceph 对象存储 9dbb5f: (又名 RGW)服务提供与 Amazon S3 和 OpenStack Swift 兼容的 RESTful API 接口。client.admin user must provide the user ID and
secret key to the user in a secure manner.
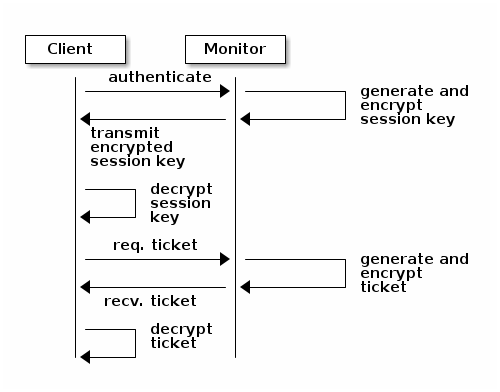
Here is how a client authenticates with a monitor. The client passes the user
name to the monitor. The monitor generates a session key that is encrypted with
the secret key associated with the username. The monitor transmits the
encrypted ticket to the client. The client uses the shared secret key to
decrypt the payload. The session key identifies the user, and this act of
identification will last for the duration of the session. The client requests
a ticket for the user, and the ticket is signed with the session key. The
monitor generates a ticket and uses the user’s secret key to encrypt it. The
encrypted ticket is transmitted to the client. The client decrypts the ticket
and uses it to sign requests to OSDs and to metadata servers in the cluster.
9b591a: Ceph 对象存储 9dbb5f: (又名 RGW)服务提供与 Amazon S3 和 OpenStack Swift 兼容的 RESTful API 接口。cephx protocol authenticates ongoing communications between the clients
and Ceph daemons. After initial authentication, each message sent between a
client and a daemon is signed using a ticket that can be verified by monitors,
OSDs, and metadata daemons. This ticket is verified by using the secret shared
between the client and the daemon.
This authentication protects only the connections between Ceph clients and Ceph daemons. The authentication is not extended beyond the Ceph client. If a user accesses the Ceph client from a remote host, cephx authentication will not be applied to the connection between the user’s host and the client host.
查看详细信息。CephX Config Reference for more on configuration details.
查看详细信息。User Management for more on user management.
查看详细信息。A Detailed Description of the Cephx Authentication Protocol for more on the distinction between authorization and
authentication and for a step-by-step explanation of the setup of cephx
tickets and session keys.
智能守护进程实现超大规模
A feature of many storage clusters is a centralized interface that keeps track of the nodes that clients are permitted to access. Such centralized architectures provide services to clients by means of a double dispatch. At the petabyte-to-exabyte scale, such double dispatches are a significant bottleneck.
Ceph obviates this bottleneck: Ceph’s OSD Daemons AND Ceph clients are cluster-aware. Like Ceph clients, each Ceph OSD Daemon is aware of other Ceph OSD Daemons in the cluster. This enables Ceph OSD Daemons to interact directly with other Ceph OSD Daemons and to interact directly with Ceph Monitors. Being cluster-aware makes it possible for Ceph clients to interact directly with Ceph OSD Daemons.
Because Ceph clients, Ceph monitors, and Ceph OSD daemons interact with one another directly, Ceph OSD daemons can make use of the aggregate CPU and RAM resources of the nodes in the Ceph cluster. This means that a Ceph cluster can easily perform tasks that a cluster with a centralized interface would struggle to perform. The ability of Ceph nodes to make use of the computing power of the greater cluster provides several benefits:
OSDs Service Clients Directly: Network devices can support only a limited number of concurrent connections. Because Ceph clients contact Ceph OSD daemons directly without first connecting to a central interface, Ceph enjoys improved perfomance and increased system capacity relative to storage redundancy strategies that include a central interface. Ceph clients maintain sessions only when needed, and maintain those sessions with only particular Ceph OSD daemons, not with a centralized interface.
OSD Membership and Status: When Ceph OSD Daemons join a cluster, they report their status. At the lowest level, the Ceph OSD Daemon status is
upordown: this reflects whether the Ceph OSD daemon is running and able to service Ceph Client requests. If a Ceph OSD Daemon isdown和inthe Ceph Storage Cluster, this status may indicate the failure of the Ceph OSD Daemon. If a Ceph OSD Daemon is not running because it has crashed, the Ceph OSD Daemon cannot notify the Ceph Monitor that it isdown. The OSDs periodically send messages to the Ceph Monitor (in releases prior to Luminous, this was done by means ofMPGStats, and beginning with the Luminous release, this has been done withMOSDBeacon如果 Ceph 监控器在可配置的时间内没有收到此类消息,则它们会标记 OSD。down这种机制是一种安全机制。downand report it to the Ceph Monitors. This contributes to making Ceph Monitors lightweight processes. See 监控 OSDs和心跳以获取更多详细信息。数据清理:为了保持数据一致性,Ceph OSD 守护进程清理 RADOS 对象。Ceph OSD 守护进程将自己的本地对象的元数据与存储在其他 OSD 上的这些对象的副本的元数据进行比较。清理基于每个放置组进行,查找对象大小不匹配和元数据不匹配,并且通常每天执行。Ceph OSD 守护进程通过将对象中的数据逐位与它们的校验和进行比较来进行更深入的清理。深度清理发现驱动器上的坏扇区,这些扇区无法通过轻量级清理检测到。参见数据清理了解如何配置清理。
复制:数据复制涉及 Ceph 客户端和 Ceph OSD 守护进程之间的协作。Ceph OSD 守护进程使用 CRUSH 算法来确定对象副本的存储位置。Ceph 客户端使用 CRUSH 算法来确定对象的存储位置,然后对象被映射到池并映射到放置组,然后客户端咨询 CRUSH 映射以识别放置组的主 OSD。
确定目标放置组后,客户端将对象写入已识别放置组的主 OSD。主 OSD 然后咨询其自己的 CRUSH 映射副本以识别二级 OSD,将对象复制到这些二级 OSD 中的放置组,确认对象已成功存储在二级 OSD 中,并报告给客户端对象已成功存储。我们称这些复制操作
subops.
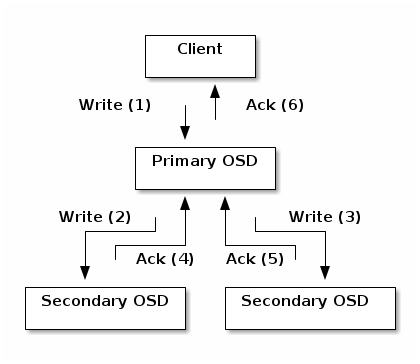
通过执行此数据复制,Ceph OSD 守护进程减轻了 Ceph 客户端及其网络接口复制数据的负担。
动态集群管理
在可扩展性和高可用性部分,我们解释了 Ceph 如何使用 CRUSH、集群拓扑和智能守护进程来扩展和维护高可用性。Ceph 设计的关键是自主、自我修复和智能的 Ceph OSD 守护进程。让我们更深入地了解 CRUSH 的工作原理,以使现代云存储基础设施能够放置数据、重新平衡集群、自适应地放置和平衡数据以及从故障中恢复。
关于池
Ceph 存储系统支持“池”的概念,这些是存储对象的逻辑分区。
Ceph 客户端从 Ceph 监控器检索集群映射,并将 RADOS 对象写入池。Ceph 将数据放置在池中的方式由池的size或副本数量、CRUSH 规则以及池中的放置组数量决定。
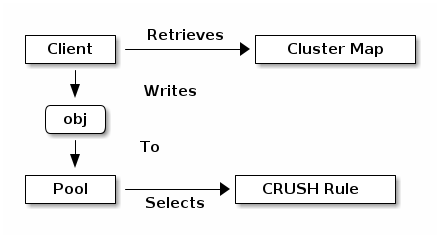
池至少设置以下参数:
对象的所有权/访问权限
放置组数量,以及
要使用的 CRUSH 规则。
查看详细信息。设置池值详细信息。
将 PG 映射到 OSD
每个池中有一定数量的放置组(PG)。CRUSH 动态地将 PG 映射到 OSD。当 Ceph 客户端存储对象时,CRUSH 将每个 RADOS 对象映射到 PG。
此 RADOS 对象到 PG 的映射在 Ceph OSD 守护进程和 Ceph 客户端之间实现了抽象和间接层。Ceph 存储集群必须在内部拓扑发生变化时能够增长(或缩小)并自适应地重新分配数据。
如果 Ceph 客户端“知道”哪些 Ceph OSD 守护进程正在存储哪些对象,则 Ceph 客户端和 Ceph OSD 守护进程之间存在紧密耦合。但 Ceph 避免了任何此类紧密耦合。相反,CRUSH 算法将每个 RADOS 对象映射到放置组,然后将每个放置组映射到一个或多个 Ceph OSD 守护进程。这“间接层”允许 Ceph 在新的 Ceph OSD 守护进程及其底层 OSD 设备上线时动态重新平衡。下面的图表显示了 CRUSH 算法如何将对象映射到放置组,以及如何将放置组映射到 OSD。
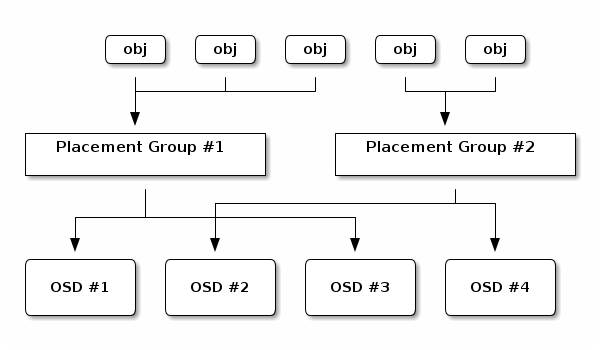
客户端使用其集群映射副本和 CRUSH 算法来计算在读取或写入特定对象时将使用哪个 OSD。
计算 PG ID
当 Ceph 客户端绑定到 Ceph 监控器时,它会检索集群映射的最新版本。当客户端配备了集群映射副本时,它了解集群中的所有监控器、OSD 和元数据服务器。然而,即使配备了最新版本的集群映射副本,客户端也不知道任何关于对象位置的信息。
对象位置必须被计算。
客户端只需要对象 ID 和池的名称即可计算对象位置。
Ceph 将数据存储在命名池中(例如,“liverpool”)。当客户端存储命名对象(例如,“john”、“paul”、“george”或“ringo”)时,它使用对象名称、哈希码、池中的 PG 数量和池名称来计算放置组。Ceph 客户端使用以下步骤计算 PG ID。
客户端输入池名称和对象 ID。(例如:pool = “liverpool” 和 object-id = “john”)
Ceph 哈希对象 ID。
Ceph 计算哈希,模 PG 数量(例如:
58),以获得 PG ID。Ceph 使用池名称检索池 ID:(例如:“liverpool” = adb56d: Ceph 将池 ID 前缀添加到 PG ID(例如:
4)Ceph 在 PG ID 前面添加池 ID(例如:ce96ce)。
4.58).
计算对象位置比通过多路会话执行对象位置查询要快得多。The CRUSH 算法允许客户端计算对象预期存储的位置,并使客户端能够联系主 OSD 以存储或检索对象。CRUSH算法允许客户端计算对象预期存储的位置,并使客户端能够联系主 OSD 以存储或检索对象。
对等和集合
在前面的部分中,我们提到 Ceph OSD 守护进程检查彼此的心跳并向 Ceph 监控器报告。Ceph OSD 守护进程还会“对等”,这是将存储放置组(PG)的所有 OSD 都带入关于该 PG 中所有 RADOS 对象(及其元数据)状态的协议的过程。Ceph OSD 守护进程向 Ceph 监控器报告对等失败。。对等问题通常自行解决;但是,如果问题仍然存在,您可能需要参考 8a162d 解决对等失败 部分。。对等问题通常自行解决;但是,如果问题仍然存在,您可能需要参考 8a162d 解决对等失败 部分。解决对等失败部分。
注意
PGs 对集群状态达成一致,但并不一定拥有最新数据。
Ceph 存储集群被设计为存储对象至少两个副本(即,5bc1d3),这是数据安全性的最低要求。为了高可用性,Ceph 存储集群应存储对象超过两个副本(即,9f48ac),以便它可以在保持数据安全的状态下继续运行。size = 2),这是数据安全性的最低要求。为了高可用性,Ceph 存储集群应存储对象超过两个副本(即,size = 3和min size = 2),以便它可以在保持数据安全的状态下继续运行。degradedstate while maintaining data safety.
警告
虽然我们在这里说 R2(两个副本的复制)是数据安全性的最低要求,但建议使用 R3(三个副本的复制)。在足够长的时间线内,使用 R2 策略存储的数据将会丢失。
如智能守护进程实现超大规模中的图表所述,我们没有具体命名 Ceph OSD 守护进程(例如,8476ac,等等。按照惯例,ec2973 行动集 中的第一个 OSD,负责协调它作为 120d22 的每个放置组的对等过程。The 唯一的 OSD,它接受客户端发起的对象写入。osd.0, osd.1、主, 次,等等。按照惯例,主是行动集中的第一个 OSD,负责协调它作为主的每个放置组的对等过程。The主是唯一的OSD,它接受客户端发起的对象写入。
负责某个放置组的 OSD 集合称为 ec2973 行动集 23619e 。术语“ ec2973 行动集 ”可以指当前负责放置组的 Ceph OSD 守护进程,也可以指在某个时代负责特定放置组的 Ceph OSD 守护进程。行动集。术语“行动集”可以指当前负责放置组的 Ceph OSD 守护进程,也可以指在某个时代负责特定放置组的 Ceph OSD 守护进程。
作为 ec2973 行动集 的一部分的 Ceph OSD 守护进程可能并不总是 eb115b 。当 ec2973 行动集 b67cc2 中的 OSD b4bc74 时,它属于 03ac50 上集 855a2b 。The 03ac50 上集 6aebe9 是一个重要的区别,因为当 OSD 出现故障时,Ceph 可以将 PG 重新映射到其他 Ceph OSD 守护进程。行动集的一部分的 Ceph OSD 守护进程可能并不总是up。当行动集中的 OSDup时,它属于上集。The上集是一个重要的区别,因为当 OSD 出现故障时,Ceph 可以将 PG 重新映射到其他 Ceph OSD 守护进程。
注意
考虑一个假设的 ec2973 行动集 e2bf4b ,它包含 543cac 。第一个 OSD (6ac021) 是 The 98a547 。如果该 OSD 出现故障,The 191076 ) 成为 The 8a0e2b , and dd7539 is removed from the 03ac50 上集 b38889 再平衡 1de41e 当您向 Ceph 存储集群添加 Ceph OSD 守护进程时,集群映射会更新新的 OSD。回到 c3f10d 计算 PG ID ,这改变了集群映射。因此,它改变了对象放置,因为它改变了计算的输入。下面的图表描绘了再平衡过程(尽管相当粗糙,因为在大集群中影响要小得多),其中一些但不是所有 PG 从现有的 OSD(OSD 1 和 OSD 2)迁移到新的 OSD(OSD 3)。即使再平衡时,CRUSH 也是稳定的。许多放置组仍然保持其原始配置,每个 OSD 都获得了一些额外的容量,因此再平衡完成后,新的 OSD 上没有负载尖峰。行动集,它包含osd.25, osd.32和osd.61。第一个 OSD (osd.25) 是 The主。如果该 OSD 出现故障,Theosd.32) 成为 The主, andosd.25is removed from the上集.
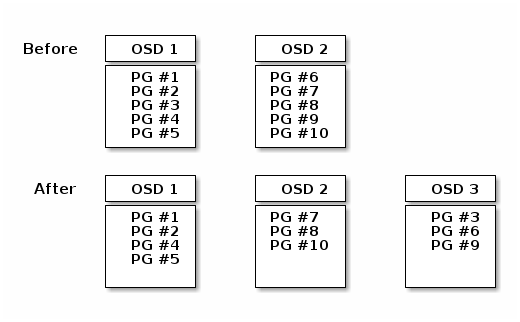
再平衡
当您向 Ceph 存储集群添加 Ceph OSD 守护进程时,集群映射会更新新的 OSD。回到计算 PG ID,这改变了集群映射。因此,它改变了对象放置,因为它改变了计算的输入。下面的图表描绘了再平衡过程(尽管相当粗糙,因为在大集群中影响要小得多),其中一些但不是所有 PG 从现有的 OSD(OSD 1 和 OSD 2)迁移到新的 OSD(OSD 3)。即使再平衡时,CRUSH 也是稳定的。许多放置组仍然保持其原始配置,每个 OSD 都获得了一些额外的容量,因此再平衡完成后,新的 OSD 上没有负载尖峰。
数据一致性
作为维护数据一致性和清洁的一部分,Ceph OSD 还清理放置组内的对象。也就是说,Ceph OSD 将一个放置组中的对象元数据与其在存储在其他 OSD 中的副本进行比较。清理(通常每天执行)捕获 OSD 错误或文件系统错误,通常是由于硬件问题引起的。OSD 还通过逐位比较对象中的数据执行更深入的清理。深度清理(默认每周执行)发现驱动器上的坏块,这些坏块在轻量级清理中不明显。
查看详细信息。Data Scrubbing了解如何配置清理。
去重编码
一个去重编码池将每个对象存储为 e88272 块。它分为 fb01cb 数据块和 3a3c60 编码块。池配置为具有 efcd64 大小,以便每个块都存储在行动集中的 OSD 中。块的级别作为对象的属性存储。K+M块。它分为K数据块和M编码块。池配置为具有K+M大小,以便每个块都存储在行动集中的 OSD 中。块的级别作为对象的属性存储。
例如,可以创建一个去重编码池来使用五个 OSD (0b04c5) 并承受其中两个的丢失 (ecad9f)。数据可能无法恢复,直到 (9dfb8b) 读取和写入编码块 1358a8 当对象 105423 NYAN 包含 64c9bf 被写入池时,去重编码函数通过简单地分割内容为三个数据块来分割内容:第一个包含 3092b6 ,第二个 7c5eba ,最后一个 a46052 。如果内容长度不是 551f9a 的倍数,则内容将被填充。该函数还创建两个编码块:第四个包含 3f93e5 ,第五个包含 f28f2d 。每个块都存储在行动集中的 OSD 中。块存储在具有相同名称 (105423 NYAN ab1061 ) 但驻留在不同 OSD 上的对象中。块的创建顺序必须保持不变,并作为对象的属性(2df683 )存储,除了其名称。块 1 包含 cabbf4 并存储在 d5922d OSD5 上,而块 4 包含 cabbf4 并存储在 42e6da OSD3 上 1358a8 当对象 105423 NYAN 411720 从去重编码池读取时,解码函数读取三个块:块 1 包含 1e0337 ,块 3 包含 057e78 ,块 4 包含 8d6820 。然后,它重建对象的原始内容 2a4d27 。解码函数被告知块 2 和 5 缺失(它们被称为“擦除”)。块 5 无法读取,因为 eef04c OSD4 7a28ee 已停用。解码函数可以在读取三个块后立即调用:b51b31 OSD2 b6b4b4 是最慢的,其块没有被考虑在内。K+M = 5) 并承受其中两个的丢失 (M = 2)。数据可能无法恢复,直到 (K+1)
读取和写入编码块
当对象NYAN包含ABCDEFGHI被写入池时,去重编码函数通过简单地分割内容为三个数据块来分割内容:第一个包含ABC,第二个DEF,最后一个GHI。如果内容长度不是K的倍数,则内容将被填充。该函数还创建两个编码块:第四个包含YXY,第五个包含QGC。每个块都存储在行动集中的 OSD 中。块存储在具有相同名称 (NYAN) 但驻留在不同 OSD 上的对象中。块的创建顺序必须保持不变,并作为对象的属性(shard_t)存储,除了其名称。块 1 包含ABC并存储在OSD5上,而块 4 包含YXY并存储在OSD3.
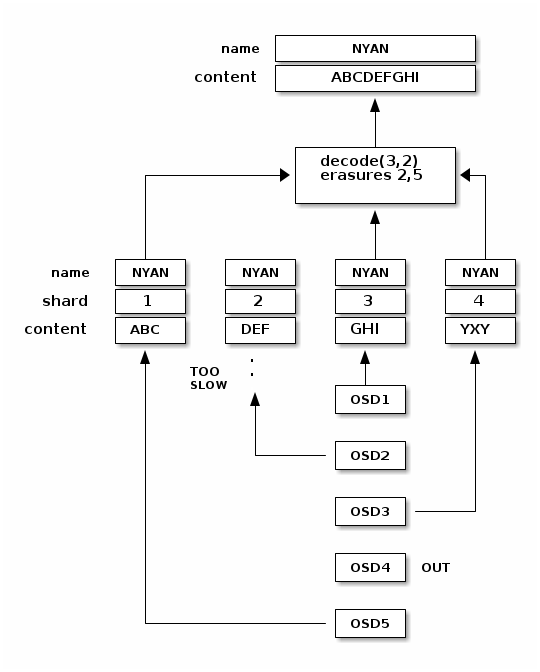
当对象NYAN从去重编码池读取时,解码函数读取三个块:块 1 包含ABC,块 3 包含GHI,块 4 包含YXY。然后,它重建对象的原始内容ABCDEFGHI。解码函数被告知块 2 和 5 缺失(它们被称为“擦除”)。块 5 无法读取,因为OSD4已停用。解码函数可以在读取三个块后立即调用:OSD2是最慢的,其块没有被考虑在内。
中断完整写入
在去重编码池中,上集中的主 OSD 接收所有写入操作。它负责将有效负载编码为 48a6ea 块,并将它们发送到其他 OSD。它还负责维护放置组日志的权威版本。K+M块,并将它们发送到其他 OSD。它还负责维护放置组日志的权威版本。
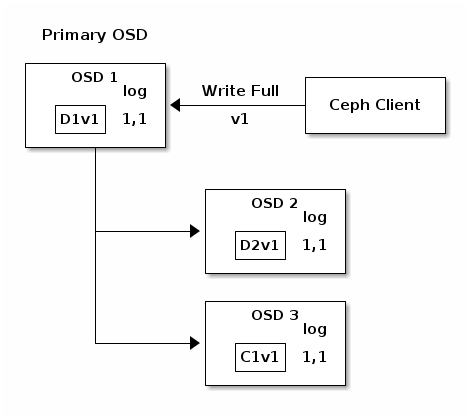
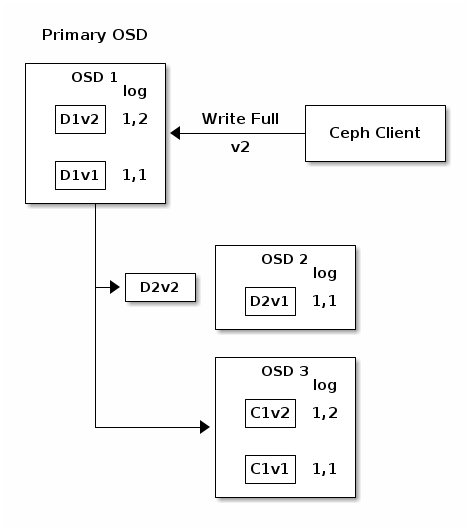
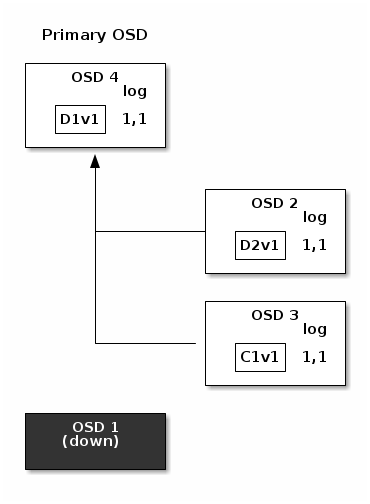
在以下图表中,已创建一个去重编码放置组,使用 1b8b74 并由三个 OSD 支持,两个用于 8b80a0 和一个用于 c0782e 。放置组的行动集由 7c1a4b OSD 1 6a08be OSD 2 667682 OSD 3 4abc8e 组成。一个对象已被编码并存储在 OSD 中:块 0d54b4(即数据块编号 1,版本 1)在 7c1a4b OSD 1 6a08be OSD 2 35a254 (即编码块编号 1,版本 1)在 667682 OSD 3 cea90a 。每个 OSD 上的放置组日志是相同的(即 a8f457 对于 epoch 1,版本 1)。K = 2, M = 1并由三个 OSD 支持,两个用于K和一个用于M。放置组的行动集由OSD 1, OSD 2和OSD 3组成。一个对象已被编码并存储在 OSD 中:块 0d54b4(即数据块编号 1,版本 1)在D1v1 (i.e. Data chunk number 1, version 1) is on OSD 1, D2v1在OSD 2和C1v1(即编码块编号 1,版本 1)在OSD 3。每个 OSD 上的放置组日志是相同的(即1,1对于 epoch 1,版本 1)。
OSD 1是主 OSD 并接收来自客户端的 2351f0 WRITE FULL 5f11a1 ,这意味着有效负载是要替换整个对象而不是覆盖其一部分。创建对象版本 2(v2)以覆盖版本 1(v1)。WRITE FULL,这意味着有效负载是要替换整个对象而不是覆盖其一部分。创建对象版本 2(v2)以覆盖版本 1(v1)。OSD 1将有效负载编码为三个块:558abb (即数据块编号 1 版本 2)将位于 7c1a4b OSD 1 6a08be OSD 2 7b030d (即编码块编号 1 版本 2)在 667682 OSD 3 3c5b1d 。每个块都被发送到目标 OSD,包括负责存储块的主 OSD,它除了处理写入操作和维护放置组日志的权威版本外,还负责存储块。当 OSD 接收到指示它写入块的消息时,它还会在放置组日志中创建一个新条目以反映此更改。例如,一旦 667682 OSD 3 a39cf1 存储 1be32a ,它就会将其条目 f0d33f (即 epoch 1,版本 2 )添加到其日志中。由于 OSD 以异步方式工作,因此一些块可能仍在传输中(例如 2893f7 ,而其他块已被确认并持久化到存储驱动器中(例如 ce96ce ) .D1v2(即数据块编号 1 版本 2)将位于OSD 1, D2v2在OSD 2和C1v2(即编码块编号 1 版本 2)在OSD 3。每个块都被发送到目标 OSD,包括负责存储块的主 OSD,它除了处理写入操作和维护放置组日志的权威版本外,还负责存储块。当 OSD 接收到指示它写入块的消息时,它还会在放置组日志中创建一个新条目以反映此更改。例如,一旦OSD 3存储C1v2,它就会将其条目1,2(即 epoch 1,版本 2 )添加到其日志中。由于 OSD 以异步方式工作,因此一些块可能仍在传输中(例如D2v2,而其他块已被确认并持久化到存储驱动器中(例如C1v1和D1v1).
如果一切顺利,每个行动集中的 OSD 都会确认块,并且日志的 fc9b40 指针可以从 4b4423 最后,用于存储先前版本对象块的文件可以被删除:7c1a4b OSD 1 6a08be OSD 2 667682 OSD 3 454986 但事故会发生。如果 7c1a4b OSD 1 351298 仍在传输中时出现故障,对象的版本 2 部分写入:667682 OSD 3 371350 只有一个块,但那不足以恢复。它丢失了两个块:b0e14f 和擦除编码参数 4735a5 要求至少有两个块可用才能重建第三个。last_complete指针可以从1,1到1,2.
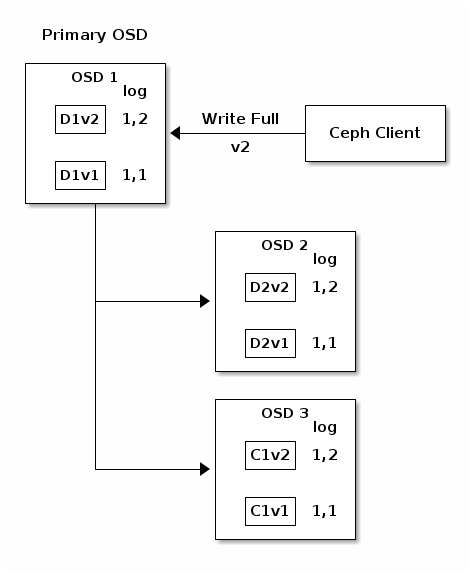
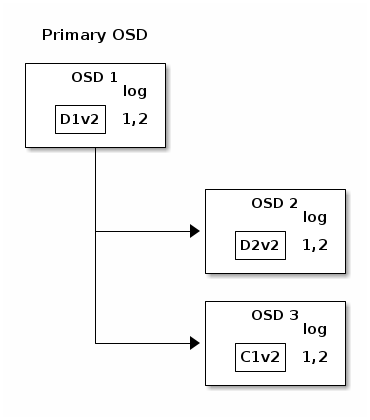
最后,用于存储先前版本对象块的文件可以被删除:D1v1在OSD 1, D2v1在OSD 2和C1v1在OSD 3.
但事故会发生。如果OSD 1在D2v2仍在传输中时出现故障,对象的版本 2 部分写入:OSD 3只有一个块,但那不足以恢复。它丢失了两个块:D1v2和D2v2和擦除编码参数K = 2, M = 1要求至少有两个块可用才能重建第三个。OSD 4成为新的主 OSD 并发现 a64eec 日志条目(即,此条目之前的所有对象都知道在以前的行动集中所有 OSD 上都可用)是 0889a7 ,并且 667682 OSD 3 54fe9b 上找到的日志条目 1,2 与 61094a OSD 4 8c3369 提供的新权威日志不一致:它被丢弃,并且包含 4e35a0 块的文件被删除。The 6a7b2e 块使用擦除编码库的 f3a0b9 功能在清理期间重建,并存储在新的主 61094a OSD 4 fe562c 查看详细信息。last_complete日志条目(即,此条目之前的所有对象都知道在以前的行动集中所有 OSD 上都可用)是1,1,并且
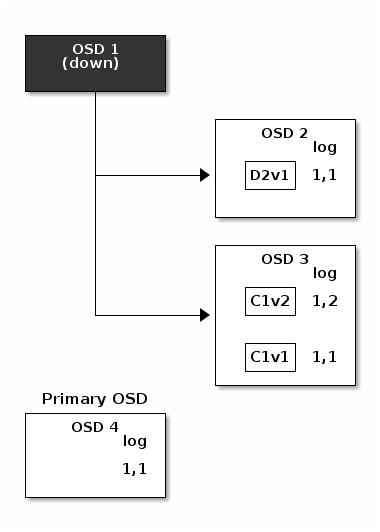
在OSD 3上找到的日志条目 1,2 与OSD 4提供的新权威日志不一致:它被丢弃,并且包含C1v2块的文件被删除。TheD1v1块使用擦除编码库的decode功能在清理期间重建,并存储在新的主OSD 4.
查看详细信息。擦除编码说明获取更多详细信息。
缓存分层
注意
在 Reef 中,缓存分层已弃用。
缓存分层为 Ceph 客户端提供更好的 I/O 性能,用于存储在后备存储层中的一部分数据。缓存分层涉及创建一个相对快速/昂贵的存储设备池(例如,固态硬盘)作为缓存层,以及一个后备池,由擦除编码或相对较慢/较便宜的设备配置为经济存储层。Ceph 对象器处理对象放置的位置,分层代理确定何时将对象从缓存刷新到后备存储层。因此,缓存层和后备存储层对 Ceph 客户端完全透明。
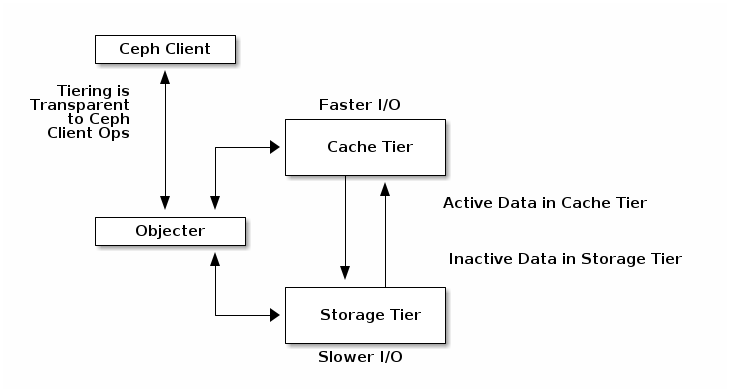
查看详细信息。缓存分层了解更多详细信息。注意,缓存层可能很棘手,现在不建议使用。
扩展 Ceph
您可以通过创建称为“Ceph 类”的共享对象类来扩展 Ceph。Ceph 动态地加载存储在 831379 classes stored in the 2dcada 目录中的类(即,bb5905 默认情况下)。当您实现类时,可以创建新的对象方法,这些方法能够调用 Ceph 对象存储中的原生方法,或通过库或您自己创建的其他类方法。.so classes stored in the osd class dir目录中的类(即,$libdir/rados-classes默认情况下)。当您实现类时,可以创建新的对象方法,这些方法能够调用 Ceph 对象存储中的原生方法,或通过库或您自己创建的其他类方法。
在写入时,Ceph 类可以调用原生或类方法,对传入数据进行任何一系列操作,并生成 Ceph 将原子地应用的结果写入事务。
在读取时,Ceph 类可以调用原生或类方法,对传出数据进行任何一系列操作,并将数据返回给客户端。
查看详细信息。src/objclass/objclass.h, src/fooclass.cc和src/barclass总结
总结
Ceph存储集群是动态的——就像一个生物体。虽然许多存储设备没有充分利用典型商用服务器的 CPU 和 RAM,但 Ceph 做到了。从心跳到对等,再到平衡集群或从故障中恢复,Ceph 将工作从客户端(以及 Ceph 架构中不存在的中央网关)卸载,并使用 OSD 的计算能力来执行工作。当提到 63632f 硬件推荐 b798bf 网络配置参考 f143b8 时,请了解上述概念,以了解 Ceph 如何利用计算资源。硬件推荐和网络配置参考时,请了解上述概念,以了解Ceph如何利用计算资源。
Ceph协议
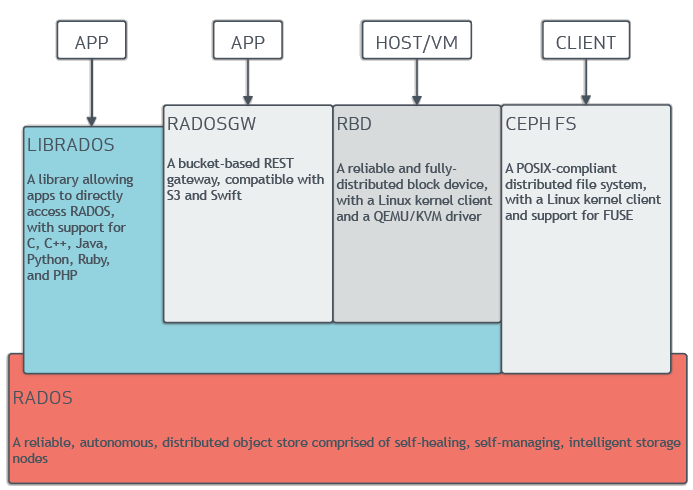
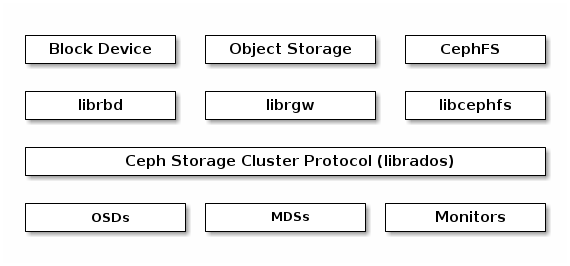
Ceph 客户端使用原生协议与 Ceph 存储集群交互。Ceph 将此功能打包到 7b5178 库中,以便您可以创建自己的自定义 Ceph 客户端。下图显示了基本架构。librados库中,以便您可以创建自己的自定义Ceph客户端。下图显示了基本架构。
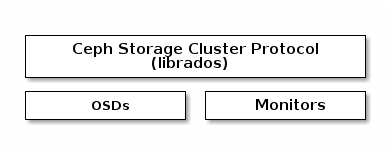
本地协议和 f3c403 现代应用程序需要一个具有异步通信能力的简单对象存储接口。Ceph 存储集群提供了一个具有异步通信能力的简单对象存储接口。该接口提供对集群中对象的直接、并行访问。librados
现代应用程序需要一个具有异步通信能力的简单对象存储接口。Ceph存储集群提供了一个具有异步通信能力的简单对象存储接口。该接口提供对集群中对象的直接、并行访问。
池操作
快照和写时复制克隆
读取/写入对象
创建/设置/获取/删除 XATTR
创建/设置/获取/删除键/值对
复合操作和双重确认语义
对象类
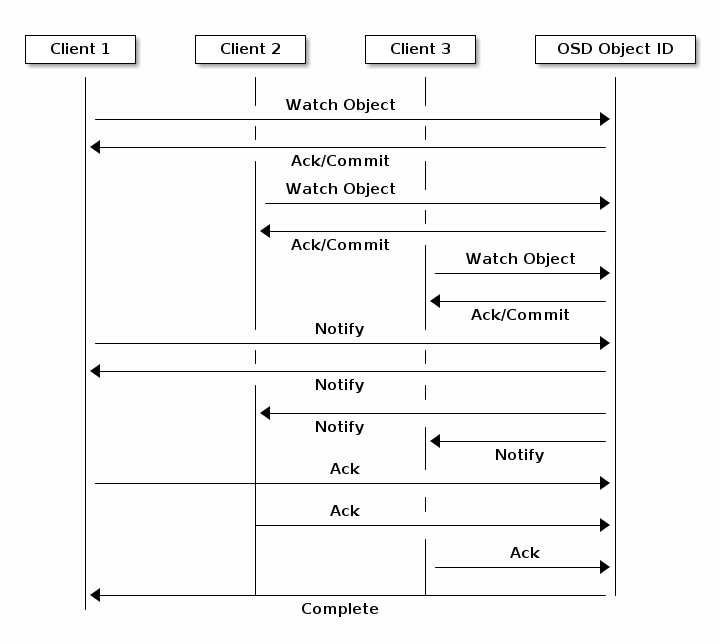
对象监控/通知
客户端可以注册对对象的持久兴趣并保持与主 OSD 的会话打开。客户端可以向所有监控器发送通知消息和有效负载,并在监控器收到通知时接收通知。这使客户端能够使用任何对象作为同步/通信通道。
数据条带化
存储设备具有吞吐量限制,这会影响性能和可扩展性。因此,存储系统通常支持条带化——将顺序信息存储在多个存储设备上——以提高吞吐量和性能。最常见的条带化形式来自 cf9151: RAID 32fe8b: 。striping--存储顺序信息到多个存储设备上--以提高吞吐量和性能。最常见的条带化形式来自 cf9151: RAID 8ff095: 。与 Ceph 的条带化最相似的 RAID 类型是 b8688e: RAID 0 248b3d ,或一个“条带化卷”。Ceph 的条带化提供 RAID 0 条带化的吞吐量、n-way RAID 镜像的可靠性以及更快的恢复。RAID。与Ceph的条带化最相似的RAID类型是RAID 0,或一个“条带化卷”。Ceph的条带化提供RAID 0条带化的吞吐量、n-way RAID镜像的可靠性以及更快的恢复。
Ceph 提供三种类型的客户端:Ceph 块设备、Ceph 文件系统和 Ceph 对象存储。Ceph 客户端将其数据从它提供给用户的表示格式(块设备镜像、RESTful 对象、CephFS 文件系统目录)转换为对象,以便存储在 Ceph 存储集群中。
提示
Ceph 存储在 Ceph 存储集群中的对象不是条带化的。Ceph 对象存储、Ceph 块设备和 Ceph 文件系统将它们的数据条带化到多个 Ceph 存储集群对象上。通过 e36824 直接写入 Ceph 存储集群的 Ceph 客户端必须自行执行条带化(以及并行 I/O)以获得这些好处。librados直接写入Ceph存储集群的Ceph客户端必须自行执行条带化(以及并行I/O)以获得这些好处。
最简单的 Ceph 条带化格式涉及条带计数为 1 个对象。Ceph 客户端将它们将要写入对象的写入数据分成大小相等的条带单元,除了最后一个条带单元。条带宽度应该是对象大小的几分之一,以便一个对象可以包含多个条带单元。
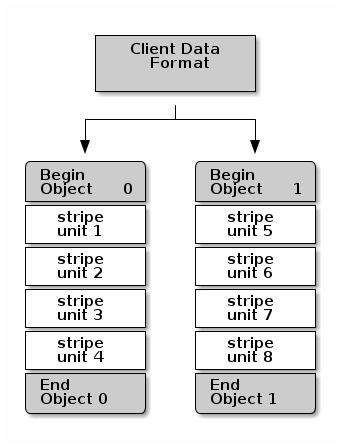
如果您预计会有大图像大小、大 S3 或 Swift 对象(例如视频)或大 CephFS 目录,您可以通过将客户端数据条带化到对象集中的多个对象上来显著提高读写性能。当客户端并行地将条带单元写入它们对应的对象时,会发生显著的写入性能。由于对象映射到不同的放置组,并且进一步映射到不同的 OSD,因此每个写入都在最大写入速度下并行发生。对单个驱动器的写入将受限于寻道时间(例如,每次寻道 6 毫秒)和该设备的带宽(例如,100MB/s)。通过将写入分散到多个对象(这些对象映射到不同的放置组和 OSD),Ceph 可以减少每个驱动器的寻道次数,并将多个驱动器的吞吐量结合起来,以实现更快的写入(或读取)速度。
注意
条带化与对象副本独立。由于CRUSH将对象复制到OSD,条带会自动复制。
在下图(object set 1在下图)中,客户端数据被条带化到一个由4个对象组成的对象集上,其中第一个条带单元在stripe unit 0,第四个条带单元在object 0, and the fourth stripe
unit is stripe unit 3,第四个条带单元在object 3。写入第四个条带后,客户端确定对象集是否已满。如果对象集未满,客户端开始再次写入第一个对象(object 0在下图)。如果对象集已满,客户端创建一个新的对象集(object set 2在下图),并开始写入新对象集中的第一个条带(stripe unit 16)在第一个对象中(object
4在下图)。
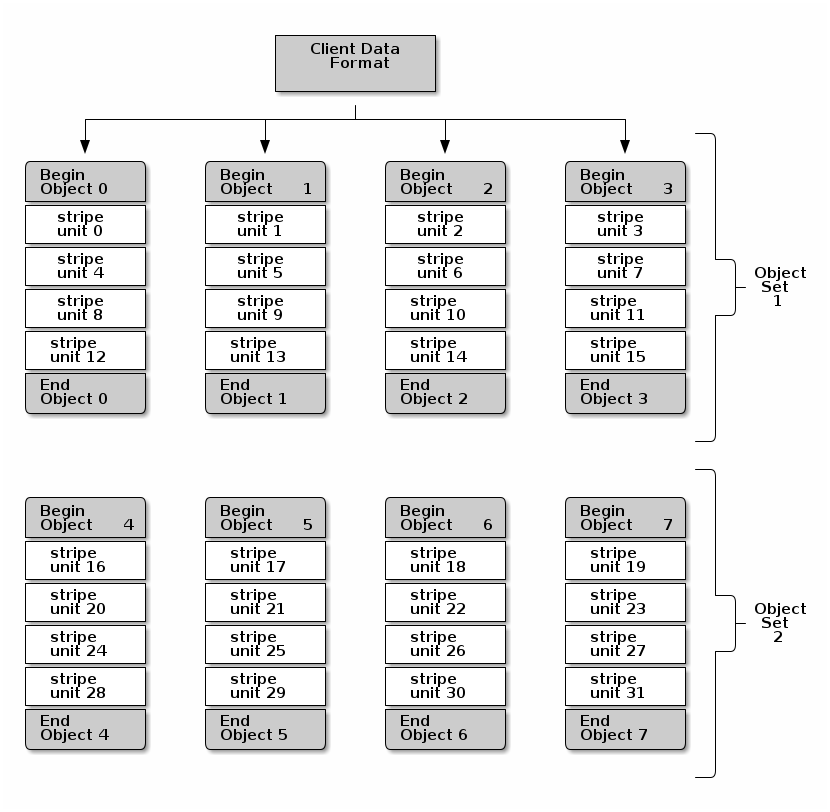
三个重要变量决定了Ceph如何条带化数据:
对象大小:Ceph存储集群中的对象有一个最大可配置大小(例如,2MB、4MB等)。对象大小应该足够大,以容纳许多条带单元,并且应该是条带单元的倍数。
条带宽度:条带有一个可配置的单位大小(例如,64KB)。Ceph客户端将其将要写入对象的数据分成大小相等的条带单元,除了最后一个条带单元。条带宽度应该是对象大小的几分之一,以便一个对象可以包含多个条带单元。
条带计数:Ceph客户端在一系列由条带计数确定的对象上写入一系列条带单元。该系列对象称为对象集。Ceph客户端写入对象集中的最后一个对象后,它返回对象集中的第一个对象。
重要
在将集群投入生产之前测试您的条带化配置的性能。您在条带化数据并将其写入对象后,不能更改这些条带化参数。
一旦Ceph客户端将数据条带化到条带单元并将条带单元映射到对象,Ceph的CRUSH算法将对象映射到池,然后将池映射到Ceph OSD守护进程,然后对象才存储在存储驱动器上的文件中。
注意
由于客户端写入单个池,所有条带化到对象的数据都映射到同一池中的池组。因此,它们使用相同的 CRUSH 映射和相同的访问控制。
Ceph 客户端
Ceph 客户端包括一些服务接口。这些包括:
块设备:9b591a: Ceph 对象存储 9dbb5f: (又名 RGW)服务提供与 Amazon S3 和 OpenStack Swift 兼容的 RESTful API 接口。Ceph 块设备(a.k.a., RBD)服务提供可调整大小、精简配置的块设备,可以进行快照和克隆。Ceph将块设备条带化到集群中以提高性能。Ceph支持内核对象(KO)和QEMU虚拟机监视器,后者使用
librbd直接--避免虚拟化系统的内核对象开销。对象存储:9b591a: Ceph 对象存储 9dbb5f: (又名 RGW)服务提供与 Amazon S3 和 OpenStack Swift 兼容的 RESTful API 接口。Ceph 对象存储(又名 RGW)服务提供 RESTful API,接口与 Amazon S3 和 OpenStack Swift 兼容。
文件系统3262c9: (CephFS) 服务提供符合 POSIX 标准的文件系统,可与 d30d83 Ceph 文件系统 (CephFS) 服务提供一个 POSIX 兼容的文件系统,可用于 48983e 或作为用户空间中的文件系统(FUSE)。Ceph 文件系统(CephFS)服务提供一个POSIX兼容的文件系统,可用于
mount或作为用户空间中的文件系统(FUSE)。
Ceph 可以运行 OSD、MDS 和监控器的额外实例以实现可扩展性和高可用性。以下图表显示了高级架构。
Ceph 对象存储
Ceph 对象存储守护进程radosgw,是一个 FastCGI 服务,它提供了一个 109018 RESTful HTTP API 来存储对象和元数据。它构建在 Ceph 存储集群之上,具有自己的数据格式,并维护自己的用户数据库、认证和访问控制。RADOS 网关使用统一的命名空间,这意味着您可以使用 OpenStack Swift 兼容的 API 或 Amazon S3 兼容的 API。例如,您可以使用 S3 兼容的 API 使用一个应用程序写入数据,然后使用 Swift 兼容的 API 使用另一个应用程序读取数据。RESTfulHTTP API来存储对象和元数据。它构建在Ceph存储集群之上,具有自己的数据格式,并维护自己的用户数据库、认证和访问控制。RADOS网关使用统一的命名空间,这意味着您可以使用OpenStack Swift兼容的API或Amazon S3兼容的API。例如,您可以使用S3兼容的API使用一个应用程序写入数据,然后使用Swift兼容的API使用另一个应用程序读取数据。
查看详细信息。Ceph 对象网关详细信息。
Ceph 块设备
Ceph 块设备条带化块设备镜像到 Ceph 存储集群中的多个对象,其中每个对象映射到池并分布,池分布在集群中不同的 d3778b daemons throughout the cluster.ceph-osddaemons throughout the cluster.
重要
条带化允许 RBD 块设备比单个服务器表现得更好!
精简配置的快照 Ceph 块设备是虚拟化和云计算的有吸引力的选择。在虚拟机场景中,人们通常部署具有 8bb924 network storage driver in 61f36e to provide a block device service to the guest. Many cloud computing stacks use d4568a to integrate 4493cf to support OpenStack, OpenNebula and CloudStackrbdnetwork storage driver inlibrbdto provide a block device service to the guest. Many cloud computing stacks uselibvirtto integratelibvirtto support OpenStack, OpenNebula and CloudStack
虽然我们目前不提供 632b5e support with other hypervisors at this time, you may also use Ceph Block Device kernel objects to provide a block device to a client. Other virtualization technologies such as Xen can access the Ceph Block Device kernel object(s). This is done with the d30d83 Ceph 文件系统 7c549e 命令行工具。Ceph 文件系统 (CephFS) 提供一个符合 POSIX 标准的文件系统,作为基于对象的 Ceph 存储集群之上的服务。CephFS 文件映射到 Ceph 存储集群中存储的对象。Ceph 客户端将 CephFS 文件系统挂载为内核对象或作为用户空间文件系统 (FUSE)。librbdsupport with other hypervisors at this time, you may also use Ceph Block Device kernel objects to provide a block device to a client. Other virtualization technologies such as Xen can access the Ceph Block Device kernel object(s). This is done with therbd.
Ceph 文件系统
命令行工具。Ceph文件系统 (CephFS) 提供一个符合POSIX标准的文件系统,作为基于对象的Ceph存储集群之上的服务。CephFS文件映射到Ceph存储集群中存储的对象。Ceph客户端将CephFS文件系统挂载为内核对象或作为用户空间文件系统 (FUSE)。
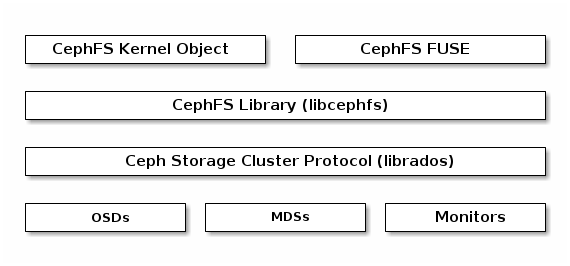
Ceph 文件系统服务包括与 Ceph 存储集群一起部署的 Ceph 元数据服务器 (MDS)。MDS 的目的是将所有文件系统元数据(目录、文件所有权、访问模式等)存储在高可用性 Ceph 元数据服务器中,元数据驻留在内存中。MDS(一个名为 6c9370 ) 是因为简单的文件系统操作,如列出目录或更改目录 (6db213 ) 会不必要地消耗 Ceph OSD 守护进程。因此,将元数据与数据分开意味着 Ceph 文件系统可以在不消耗 Ceph 存储集群的情况下提供高性能服务。ceph-mds) 是因为简单的文件系统操作,如列出目录或更改目录 (ls, cd) 会不必要地消耗 Ceph OSD 守护进程。因此,将元数据与数据分开意味着 Ceph 文件系统可以在不消耗 Ceph 存储集群的情况下提供高性能服务。
CephFS 将元数据与数据分开,将元数据存储在 MDS 中,将文件数据存储在 Ceph 存储集群的一个或多个对象中。Ceph 文件系统旨在实现 POSIX 兼容性。ceph-mds可以作为一个进程运行,或者可以分布到多个物理机器,无论是为了高可用性还是可扩展性。
高可用性: 额外的 71a0bf 实例可以是 3b8d4f 热备 699eee ,随时准备接管任何失败的 16aebf 的职责。这很容易,因为所有数据,包括日志,都存储在 RADOS 中。过渡是由 2d215e 自动触发的。603ba3: : 多个 b3ef96 实例可以是 c76a5e 活跃 387990 活动的 。这很容易,因为所有数据,包括日志,都存储在 RADOS 中。过渡是由 369703 触发的。
ceph-mds实例可以是热备,随时准备接管任何失败的ceph-mds的职责。这很容易,因为所有数据,包括日志,都存储在 RADOS 中。过渡是由 2d215e: 自动触发的。603ba3: : 多个 b3ef96: 实例可以是 c76a5e: 活跃活动的。这很容易,因为所有数据,包括日志,都存储在RADOS中。过渡是由ceph-mon.触发的。: 多个 71a0bf 实例可以是 387990 活动的 ,它们将目录树分成子树(以及单个繁忙目录的碎片),有效地在所有 387990 活动的 服务器之间平衡负载。
ceph-mds实例可以是活动的,它们将目录树分成子树(以及单个繁忙目录的碎片),有效地在所有活动的服务器之间平衡负载。
a7b13e: 热备热备和活动的等组合是可能的,例如运行 387990 活动的 5a87e7 实例进行扩展,和一个 3b8d4f 热备 048d19 实例进行高可用性。活动的 ceph-mds实例进行扩展,和一个热备实例进行高可用性。