注意
本文档适用于 Ceph 开发版本。
压缩冗余
简介
应用于现有软件堆栈的数据去重并不容易,由于需要额外的元数据管理和原始数据处理。
在典型的去重系统中,作为数据对象的输入源被分片算法分割成多个片段。然后,去重系统将每个片段与先前存储在存储中的现有数据片段进行比较。为此,去重系统采用一个存储每个片段哈希值的指纹索引,以便通过比较哈希值而不是搜索底层存储中驻留的所有内容来轻松找到现有片段。
在 Ceph 上实现去重有很多挑战。其中,两个问题对于去重至关重要。首先是管理指纹索引的可扩展性;其次,确保新应用的去重元数据与现有元数据之间的兼容性很复杂。
核心思想
1. 内容哈希(双重哈希):每个客户端可以使用 CRUSH 找到对象 ID 的对象数据。使用 CRUSH,客户端知道对象在基础层中的位置。通过在基础层对对象内容进行哈希,生成一个新的 OID(片段 ID)。片段层存储具有原始对象部分内容的新的 OID。客户端 1 -> OID=1 -> HASH(1 的内容)=K -> OID=K -> CRUSH(K) -> 片段的位置
2. 自包含对象:外部元数据设计使得与存储功能支持集成变得困难,因为现有的存储功能无法识别额外的外部数据结构。如果我们能够设计一个没有任何外部组件的数据去重系统,则可以重用原始的存储功能。
更多详情请参见
More details in https://ieeexplore.ieee.org/document/8416369
设计
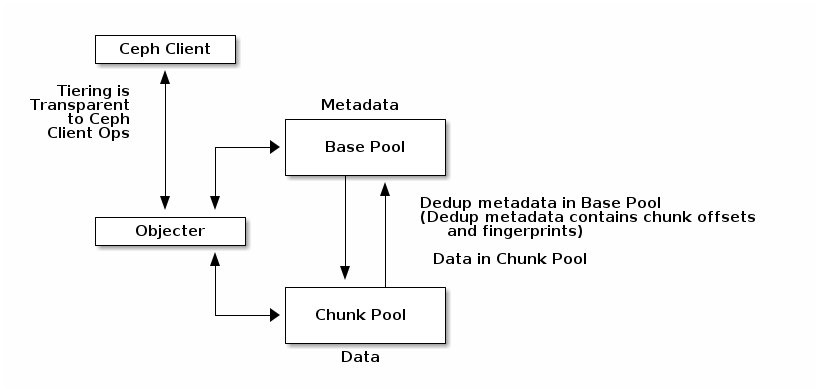
基于池的对象管理:我们定义了两个池。元数据池存储元数据对象,片段池存储片段对象。由于这两个池是根据目的和使用进行划分的,因此每个池都可以根据其不同的特性更有效地进行管理。基础池和片段池可以根据其使用情况分别选择复制和纠删编码之间的冗余方案,并且每个池可以根据所需的性能放置在不同的存储位置。
关于如何使用,请参见osd_internals/manifest.rst
使用模式
每个 Ceph 接口层为去重和分层提供了独特的机会和成本。
RadosGW
S3 大数据工作负载似乎是一个很好的去重机会。这些对象通常是“写入一次,主要读取”的对象,不会出现部分覆盖。因此,提前进行指纹识别和去重是有意义的。
与 cephfs 和 rbd 不同,radosgw 在逻辑 S3 对象的头部对象中有一个系统来存储显式元数据以定位剩余部分。因此,radosgw 可以直接使用 refcounting 机制(7adb60: )而无需 rados 的直接支持来处理清单。osd_internals/refcount.rst) directly without
needing direct support from rados for manifests.
RBD/Cephfs
RBD 和 CephFS 都使用确定性命名方案来将块设备/文件数据分区到 rados 对象上。因此,重定向元数据需要作为 rados 的一部分包含在内,预计是透明的。
此外,与 radosgw 不同,rbd/cephfs rados 对象可能会出现覆盖。对于这些对象,我们确实不希望执行去重,而且我们也不希望在热路径上为此付出写入延迟惩罚。因此,在后台对冷对象执行分层和去重可能是更可取的。
然而,有一个重要的问题是,rbd 和 cephfs 工作负载通常都使用快照。这意味着 rados 清单支持需要强大的快照支持。
RADOS 机制
关于 rados 重定向/片段/去重支持的更多信息,请参见osd_internals/manifest.rst。关于 rados refcount 支持的更多信息,请参见osd_internals/refcount.rst.
状态和未来工作
目前,在 OSD 中已经存在一些初步支持用于清单对象以及去重工具。
RadosGW 数据仓库工作负载可能代表了这个功能最大的机会,因此,首先可能是要为 radosgw 添加对指纹识别和重定向的直接支持到 refcount 池中。
除了 radosgw 之外,完成 OSD 中清单对象支持的 работы,特别是与其与快照的关系相关的部分,将是 rbd 和 cephfs 工作负载的下一步。
如何使用去重
此功能高度实验性,可能会更改或删除。
Ceph 使用 RADOS 机制提供去重。下面我们解释如何执行去重。
先决条件
如果 Ceph 集群是从 Ceph 主线启动的,用户需要检查ceph-test包含 ceph-dedup-tool 的包是否已安装。
详细说明
用户可以使用 ceph-dedup-tool 进行estimate, sample-dedup,
chunk-scrub, and chunk-repair操作。为了给用户提供更好的便利性,我们已经通过 ceph-dedup-tool 启用了必要的操作,并且我们建议用户使用任何类型的脚本自由地使用以下操作。
1. 估计目标池的空间节省比例使用ceph-dedup-tool.
ceph-dedup-tool --op estimate
--pool [BASE_POOL]
--chunk-size [CHUNK_SIZE]
--chunk-algorithm [fixed|fastcdc]
--fingerprint-algorithm [sha1|sha256|sha512]
--max-thread [THREAD_COUNT]
此 CLI 命令将显示在池上应用去重时可以节省多少存储空间。如果节省的空间量高于用户的预期,则该池可能值得执行去重。BASE_POOL,其中目标去重对象存储。用户还需要多次运行 ceph-dedup-tool,使用不同的chunk_size来找到最佳片段大小。请注意,在 fastcdc 片段算法的情况下(不是固定的),最佳值可能因每个对象的内容而异。
示例输出:
{
"chunk_algo": "fastcdc",
"chunk_sizes": [
{
"target_chunk_size": 8192,
"dedup_bytes_ratio": 0.4897049
"dedup_object_ratio": 34.567315
"chunk_size_average": 64439,
"chunk_size_stddev": 33620
}
],
"summary": {
"examined_objects": 95,
"examined_bytes": 214968649
}
}
上面的示例是执行estimate. target_chunk_size is the same as
chunk_size由用户提供的命令时的输出。dedup_bytes_ratio显示了从检查的字节中冗余的字节数。例如,1 -dedup_bytes_ratio表示节省的存储空间百分比。dedup_object_ratio是生成的片段对象 /examined_objects. chunk_size_average表示执行 CDC 时平均划分的片段大小——这可能不同于target_chunk_size,因为 CDC 根据内容生成不同的片段边界。chunk_size_stddev表示片段大小的标准差。
2. 创建片段池。
ceph osd pool create [CHUNK_POOL]
3. 运行去重命令(有两种方法)。
sample-dedup
ceph-dedup-tool --op sample-dedup
--pool [BASE_POOL]
--chunk-pool [CHUNK_POOL]
--chunk-size [CHUNK_SIZE]
--chunk-algorithm [fastcdc]
--fingerprint-algorithm [sha1|sha256|sha512]
--chunk-dedup-threshold [THRESHOLD]
--max-thread [THREAD_COUNT]
--sampling-ratio [SAMPLE_RATIO]
--wakeup-period [WAKEUP_PERIOD]
--loop
--snap
The sample-dedup命令生成由THREAD_COUNT指定的线程来对BASE_POOL上的对象进行去重。根据采样率——如果SAMPLE_RATIO是 100,则进行全搜索,如果片段在迭代过程中冗余超过THRESHOLD次,则线程选择性地执行去重。如果设置了 --loop,线程将在WAKEUP_PERIOD后唤醒。如果没有,线程将在一次迭代后退出。
示例输出:
$ bin/ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
ssd 303 GiB 294 GiB 9.0 GiB 9.0 GiB 2.99
TOTAL 303 GiB 294 GiB 9.0 GiB 9.0 GiB 2.99
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
.mgr 1 1 577 KiB 2 1.7 MiB 0 97 GiB
base 2 32 2.0 GiB 517 6.0 GiB 2.02 97 GiB
chunk 3 32 0 B 0 0 B 0 97 GiB
$ bin/ceph-dedup-tool --op sample-dedup --pool base --chunk-pool chunk
--fingerprint-algorithm sha1 --chunk-algorithm fastcdc --loop --sampling-ratio 100
--chunk-dedup-threshold 2 --chunk-size 8192 --max-thread 4 --wakeup-period 60
$ bin/ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
ssd 303 GiB 298 GiB 5.4 GiB 5.4 GiB 1.80
TOTAL 303 GiB 298 GiB 5.4 GiB 5.4 GiB 1.80
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
.mgr 1 1 577 KiB 2 1.7 MiB 0 98 GiB
base 2 32 452 MiB 262 1.3 GiB 0.50 98 GiB
chunk 3 32 258 MiB 25.91k 938 MiB 0.31 98 GiB
object dedup
ceph-dedup-tool --op object-dedup
--pool [BASE_POOL]
--object [OID]
--chunk-pool [CHUNK_POOL]
--fingerprint-algorithm [sha1|sha256|sha512]
--dedup-cdc-chunk-size [CHUNK_SIZE]
The object-dedup命令触发由OID指定的 RADOS 对象的去重。CHUNK_SIZE应该从上面步骤 1 的结果中获取。fastcdc将默认设置,其他参数,如fingerprint-algorithm和CHUNK_SIZE将作为池的默认值设置。object-dedup,因为片段边界应根据更新内容重新计算。snap。去重完成后,目标对象在BASE_POOL中的大小为零(被清除),并生成片段对象——这些出现在CHUNK_POOL.
4. 读写 I/O
完成步骤 3 后,用户不需要考虑任何与 I/O 相关的内容。去重的对象与现有的 RADOS 操作完全兼容。
5. 运行清理以修复引用计数
在处理去重的 RADOS 对象的引用计数时,偶尔可能会出现引用不匹配的错误阳性。这些不匹配将通过定期清理池来修复:
ceph-dedup-tool --op chunk-scrub
--chunk-pool [CHUNK_POOL]
--pool [POOL]
--max-thread [THREAD_COUNT]
The chunk-scrub命令识别元数据对象和片段对象之间的引用不匹配。参数chunk-pool告诉 ceph-dedup-tool 目标片段对象的位置。
示例输出:
引用不匹配是故意创建的,通过使用 chunk-get-ref 将引用(dummy-obj)插入到片段对象(2ac67f70d3dd187f8f332bb1391f61d4e5c9baae)中。
$ bin/ceph-dedup-tool --op dump-chunk-refs --chunk-pool chunk --object 2ac67f70d3dd187f8f332bb1391f61d4e5c9baae
{
"type": "by_object",
"count": 2,
"refs": [
{
"oid": "testfile2",
"key": "",
"snapid": -2,
"hash": 2905889452,
"max": 0,
"pool": 2,
"namespace": ""
},
{
"oid": "dummy-obj",
"key": "",
"snapid": -2,
"hash": 1203585162,
"max": 0,
"pool": 2,
"namespace": ""
}
]
}
$ bin/ceph-dedup-tool --op chunk-scrub --chunk-pool chunk --max-thread 10
10 seconds is set as report period by default
join
join
2ac67f70d3dd187f8f332bb1391f61d4e5c9baae
--done--
2ac67f70d3dd187f8f332bb1391f61d4e5c9baae ref 10:5102bde2:::dummy-obj:head: referencing pool does not exist
--done--
Total object : 1
Examined object : 1
Damaged object : 1
6. 修复不匹配的片段引用
如果在chunk-scrub后出现任何引用不匹配,建议执行chunk-repair操作来修复引用不匹配。操作chunk-repair有助于解决引用不匹配并恢复一致性。
ceph-dedup-tool --op chunk-repair
--chunk-pool [CHUNK_POOL_NAME]
--object [CHUNK_OID]
--target-ref [TARGET_OID]
--target-ref-pool-id [TARGET_POOL_ID]
chunk-repair修复了target-ref,这是一个错误的object的引用。为了正确修复它,用户必须输入正确的TARGET_OID和TARGET_POOL_ID.
$ bin/ceph-dedup-tool --op chunk-repair --chunk-pool chunk --object 2ac67f70d3dd187f8f332bb1391f61d4e5c9baae --target-ref dummy-obj --target-ref-pool-id 10
2ac67f70d3dd187f8f332bb1391f61d4e5c9baae has 1 references for dummy-obj
dummy-obj has 0 references for 2ac67f70d3dd187f8f332bb1391f61d4e5c9baae
fix dangling reference from 1 to 0
$ bin/ceph-dedup-tool --op dump-chunk-refs --chunk-pool chunk --object 2ac67f70d3dd187f8f332bb1391f61d4e5c9baae
{
"type": "by_object",
"count": 1,
"refs": [
{
"oid": "testfile2",
"key": "",
"snapid": -2,
"hash": 2905889452,
"max": 0,
"pool": 2,
"namespace": ""
}
]
}
由 Ceph 基金会带给您
Ceph 文档是一个社区资源,由非盈利的 Ceph 基金会资助和托管Ceph Foundation. 如果您想支持这一点和我们的其他工作,请考虑加入现在加入.