注意
本文档适用于 Ceph 开发版本。
使用mClock和WPQ调度器的QoS研究
简介
mClock调度器为每个使用它的服务提供三个控制。在Ceph中,使用mClock的服务例如客户端I/O、后台恢复、清理、快照修剪和PG删除。这三个控制用于根据其权重按比例分配资源给每个服务,同时保证服务至少获得其预留量,且不超过其限制。在Ceph中,这些控制用于在已知每个OSD的IOPS容量的情况下,为每种服务类型分配IOPS。mClock调度器基于权重, 保留和limit are used for predictable allocation of resources to each service in proportion to its weight subject to the constraint that the service receives at least its reservation and no more than its limit. In Ceph, these controls are used to allocate IOPS for each service type provided the IOPS capacity of each OSD is known. The mClock scheduler is based on 的 dmClock 算法的队列调度程序实现的。有关网络配置的详细信息,请参阅基于 mClock 的 QoS部分内容详细介绍。
Ceph对mClock的使用主要是实验性的,并以探索的心态进行。这仍然适用于其他组织和个人,他们继续使用代码库或根据他们的需求修改它。56a765: DmClock存在于它自己的
DmClock exists in its own 存储库中。在Ceph太平洋发布之前,可以通过将osd_op_queueCeph选项设置为保留, 权重和limit。例如,osd_mclock_scheduler_client_[res,wgt,lim]是这样一个选项。参见基于 mClock 的 QoS部分以获取更多详细信息。即使设置了所有mClock选项,由于以下原因,mClock的全部功能也无法实现:
未知OSD容量,以吞吐量(IOPS)衡量。
没有限制执行。换句话说,使用mClock的服务被允许超出其限制,导致预期的QoS目标未实现。
每种服务类型的份额没有分布在操作分片数量上。
为了解决上述问题,对Ceph代码库中的mClock调度器进行了改进。参见mClock 配置参考。通过改进,mClock的使用更加用户友好和直观。这是许多步骤中之一,以改进和优化Ceph中mClock的使用方式。
概述
作为改进mClock调度器工作的一部分,进行了比较研究。该研究涉及并行运行客户端操作和后台恢复操作的两个调度器进行测试。结果被汇总并进行了比较。以下统计数据是在每个服务类型的测试结果中,在两个调度器之间进行比较的:
外部客户端
平均吞吐量(IOPS),
平均和百分位数(95th, 99th, 99.5th)延迟,
背景恢复
平均恢复吞吐量,
每秒恢复的错置对象数量
测试环境
软件配置: CentOS 8.1.1911 Linux内核4.18.0-193.6.3.el8_2.x86_64
CPU: 2 x Intel® Xeon® CPU E5-2650 v3 @ 2.30GHz
nproc: 40
系统内存: 64 GiB
Tuned-adm配置文件: network-latency
CephVer: 17.0.0-2125-g94f550a87f (94f550a87fcbda799afe9f85e40386e6d90b232e) quincy (dev)
存储:
Intel® NVMe SSD DC P3700系列 (SSDPE2MD800G4) [4 x 800GB]
Seagate Constellation 7200 RPM 64MB缓存SATA 6.0Gb/s HDD (ST91000640NS) [4 x 1TB]
测试方法
Cephcbt用于测试恢复场景。创建了一个新的恢复测试来并行生成客户端I/O的后台恢复。参见下一节的详细测试步骤。该测试使用默认的权重优先队列(WPQ)调度器进行三次执行,以进行比较。这是为了建立可信的平均值,以便稍后比较mClock调度器的结果。
之后,使用mClock调度器和不同的mClock配置文件(即,high_client_ops, 平衡和high_recovery_ops和
Note
对HDD进行的测试是与和不配置bluestore WAL和dB的测试。下面讨论的图表有助于展示调度器及其配置之间的比较。
建立基准客户端吞吐量(IOPS)
在实际的恢复测试之前,通过遵循mClock 配置参考文档中“使用CBT进行基准测试步骤”部分中提到的步骤,为测试机器上的SSD和HDD建立了基线吞吐量。对于本研究,确定了每种设备类型的以下基线吞吐量:
设备类型 |
基线吞吐量(@4KiB随机写入) |
|---|---|
NVMe SSD |
21500 IOPS (84 MiB/s) |
HDD(带bluestore WAL & dB) |
340 IOPS (1.33 MiB/s) |
HDD(不带bluestore WAL & dB) |
315 IOPS (1.23 MiB/s) |
Note
The bluestore_throttle_bytes和bluestore_throttle_deferred_bytesSSD的基线吞吐量被确定为
MClock配置分配
以下表格显示了每个配置文件的低级mClock份额。对于保留和limit等参数,份额表示为总OSD容量的百分比。对于high_client_ops配置文件,设置保留参数为总OSD容量的50%。因此,对于NVMe(基线21500 IOPS)设备,为客户端操作预留了至少10750 IOPS。一旦启用配置文件,就会在后台进行这些分配。
The 权重参数是无单位的。参见基于 mClock 的 QoS.
high_client_ops(default)
此配置文件在与其他Ceph内部客户端和后台恢复相比时,为外部客户端操作分配了更多的预留和限制。此配置文件默认启用。
服务类型 |
保留 |
权重 |
限制 |
|---|---|---|---|
客户端 |
50% |
2 |
MAX |
背景恢复 |
25% |
1 |
100% |
后台最佳努力 |
25% |
2 |
MAX |
平衡
此配置文件将相同的预留分配给客户端操作和后台恢复操作。内部最佳努力客户端获得的预留较低,但限制非常高,以便在没有竞争服务的情况下快速完成。
服务类型 |
保留 |
权重 |
限制 |
|---|---|---|---|
客户端 |
40% |
1 |
100% |
背景恢复 |
40% |
1 |
150% |
后台最佳努力 |
20% |
2 |
MAX |
high_recovery_ops
与外部客户端和其他Ceph内部客户端相比,此配置文件为后台恢复分配了更多的预留。例如,管理员可以暂时启用此配置文件,以在非高峰时段加快后台恢复。
服务类型 |
保留 |
权重 |
限制 |
|---|---|---|---|
客户端 |
30% |
1 |
80% |
背景恢复 |
60% |
2 |
200% |
后台最佳努力 |
1 (最小) |
2 |
MAX |
custom
自定义配置文件允许用户完全控制mClock和Ceph配置参数。要使用此配置文件,用户必须深入了解Ceph和mClock调度器的工作原理。必须手动设置不同服务类型的所有保留, 权重和limit参数以及任何Ceph选项。此配置文件可用于实验和探索目的,或者如果内置配置文件不满足要求。在这种情况下,启用此配置文件之前必须进行充分的测试。
恢复测试步骤
在启动Ceph集群之前,根据上一节获得的基线吞吐量,适当地设置了以下mClock配置参数:
请参阅mClock 配置参考 for more details.
使用cbt的测试步骤
使用4个osd启动Ceph集群。
将OSD配置为3个复制因子。
创建一个恢复池来填充恢复数据。
创建一个客户端池并在其中预填充一些对象。
创建恢复线程并将一个OSD标记为下线并移除。
在集群处理OSD下线事件后,恢复数据被预填充到恢复池中。对于涉及SSD的测试,将100K 4MiB对象预填充到恢复池中。对于涉及HDD的测试,将5K 4MiB对象预填充到恢复池中。
在预填充阶段完成后,下线的OSD被启动并上线。回填阶段从这一点开始。
一旦回填/恢复开始,测试就在另一个线程上使用单个客户端在客户端池上启动客户端I/O。
在上述步骤8中,cbt捕获了与客户端延迟和带宽相关的统计数据。该测试还捕获了错置对象的总数和每秒恢复的错置对象数量。
总而言之,上述步骤在测试期间创建了两个池。在一个池上触发恢复,在另一个池上同时触发客户端I/O。下面讨论了测试期间捕获的统计数据。
非默认Ceph恢复选项
除了上面提到的非默认bluestore节流之外,为了在WPQ和mClock调度器的测试中测试两者,修改了以下Ceph恢复相关选项。
osd_max_backfills= 1000osd_recovery_max_active= 1000
上述选项对每个OSD的并发本地和远程回填操作设置了高限制。在这些条件下测试了mClock调度器的功能,并讨论了以下结果。
测试结果
使用NVMe SSD的测试结果
客户端吞吐量比较
以下图表显示了调度器及其各自配置的平均客户端吞吐量比较。
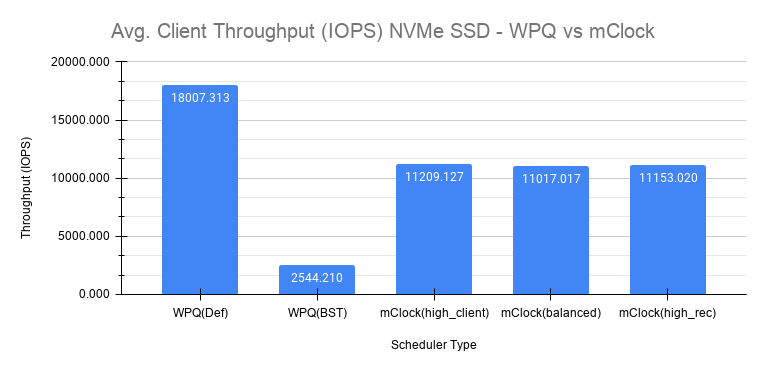
图表中的WPQ(默认)显示了使用WPQ调度器并设置所有其他Ceph配置设置为默认值时获得的平均客户端吞吐量。2257e3: 的默认设置限制每个OSD的并发本地和远程回填或恢复的数量为1。因此,与基线值21500 IOPS相比,获得的平均客户端吞吐量令人印象深刻,仅为18000 IOPS以上。osd_max_backfills limits the number
of concurrent local and remote backfills or recoveries per OSD to 1. As a
result, the average client throughput obtained is impressive at just over 18000
IOPS when compared to the baseline value which is 21500 IOPS.
然而,使用WPQ调度器以及第51ef11:节中提到的非默认选项,情况就大不相同,如图表中的WPQ(BST)所示。在这种情况下,获得的平均客户端吞吐量急剧下降到仅2544 IOPS。非默认恢复选项显然对客户端吞吐量有显著影响。换句话说,恢复操作压倒了客户端操作。下面的章节进一步讨论了在这些条件下的恢复率。非默认Ceph恢复选项, things are quite different as shown in the chart for WPQ(BST). In this case, the average client throughput obtained drops dramatically to only 2544 IOPS. The non-default recovery options clearly had a significant impact on the client throughput. In other words, recovery operations overwhelm the client operations. Sections further below discuss the recovery rates under these conditions.
使用非默认选项,使用mClock并启用默认配置文件(high_client_ops)执行了相同的测试。根据配置文件的分配,预留目标为50%(10750 IOPS)在恢复操作期间通过平均吞吐量11209 IOPS得到满足。这是WPQ(BST)获得的吞吐量的4倍多。
如上图所示,获得与平衡(11017 IOPS)和high_recovery_ops(11153 IOPS)配置文件相似的吞吐量。这清楚地表明,mClock能够在多个并发回填/恢复操作正在进行时为客户端提供所需的QoS。
客户端延迟比较
以下图表显示了平均完成延迟(clat)以及平均95th、99th和99.5th百分位数在调度器及其各自配置之间的比较。
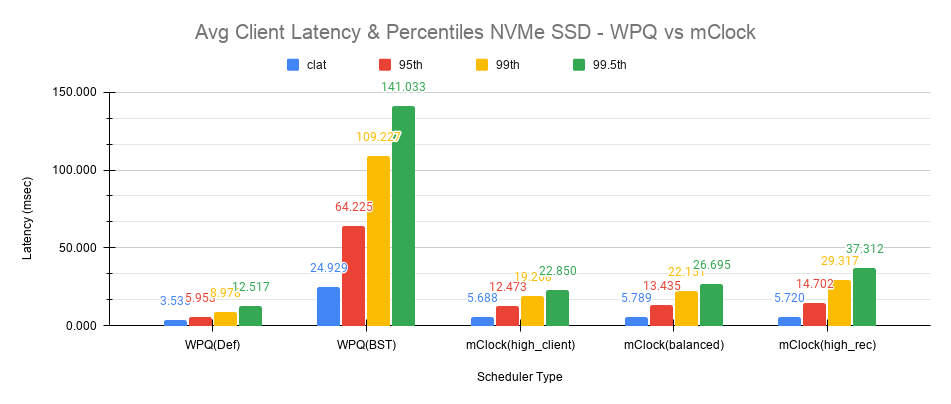
使用WPQ(默认)获得的平均clat延迟为3.535毫秒。但在这种情况下,并发恢复的数量非常有限,平均约为97个对象/秒或~388 MiB/s,并且是客户端看到低延迟的主要因素。
使用WPQ(BST)和非默认恢复选项,情况就大不相同,平均clat延迟上升到平均近25毫秒,这是7倍糟糕!这是由于并发恢复数量很高,测量为~350个对象/秒或~1.4 GiB/s,这接近最大OSD带宽。
使用启用的mClock和默认high_client_ops配置文件,平均clat延迟为5.688毫秒,考虑到高数量的并发活动后台回填/恢复,这是令人印象深刻的。mClock将恢复速率限制在根据最小配置文件分配的25%的最大OSD带宽的平均80个对象/秒或~320 MiB/s,从而允许客户端操作满足QoS目标。
使用其他配置文件(如平衡和high_recovery_ops),平均客户端clat延迟没有变化很大,保持在5.7 - 5.8毫秒之间,如上图所示的平均百分位数延迟有所变化。
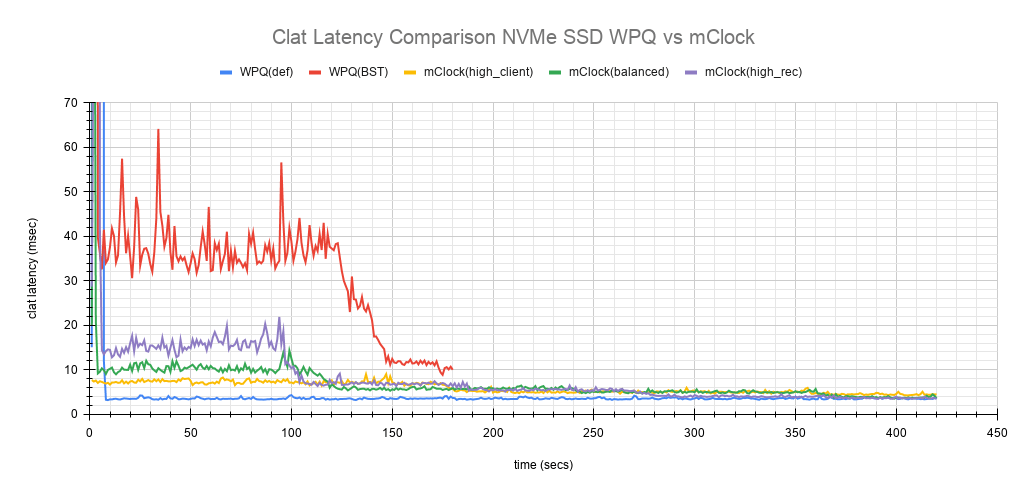
也许更有趣的图表是上面显示的跟踪测试期间平均clat延迟变化的比较图表。该图表显示了WPQ和mClock配置文件之间平均延迟的差异)。在测试的初始阶段,大约150秒内,WPQ调度器和mClock调度器配置文件之间的平均延迟差异非常明显且易于理解。配置文件high_client_ops显示了最低延迟,其次是平衡和high_recovery_ops配置文件。WPQ(BST)在整个测试过程中具有最高的平均延迟。
恢复统计比较
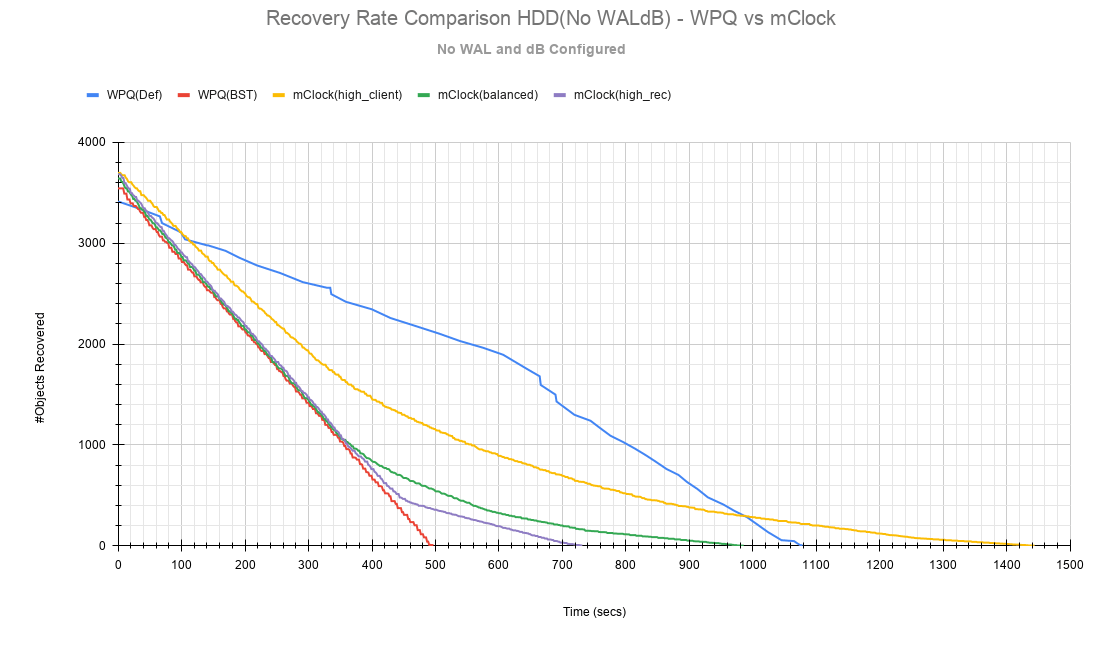
另一个需要考虑的重要方面是mClock配置文件设置如何影响恢复带宽和恢复时间。以下图表概述了每个mClock配置文件的恢复速率和时间,以及它们与WPQ调度器的差异。在所有情况下要恢复的总对象数约为75000个对象,如下图所示。
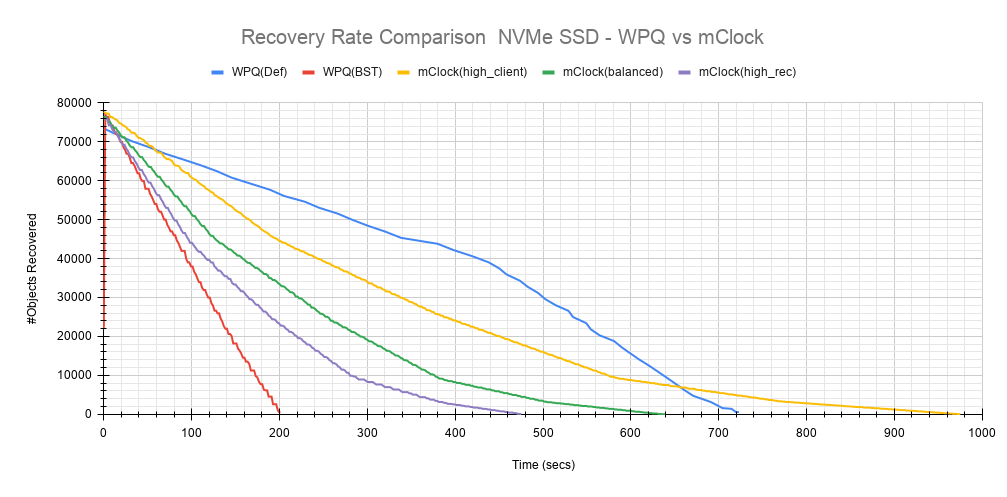
直觉上,high_client_ops应该对恢复操作影响最大,这确实如此,因为它平均需要966秒才能在80个对象/秒的速度下完成恢复。正如预期的那样,恢复带宽最低,平均约为~320 MiB/s。
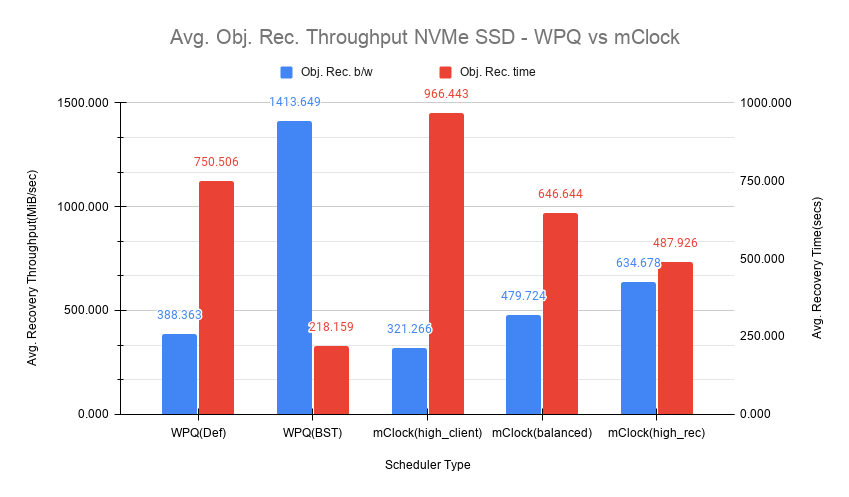
The 平衡配置文件通过为客户端和恢复操作分配相同的预留和权重提供了良好的折衷方案。恢复速率曲线落在high_recovery_ops和high_client_ops曲线之间,平均带宽约为~480 MiB/s,并在~120个对象/秒的速度下平均需要~647秒才能完成恢复。
The high_recovery_ops配置文件以牺牲其他操作为代价,提供了最快完成恢复操作的方式。与使用high_client_ops配置文件观察到的带宽相比,恢复带宽几乎是2倍,约为~635 MiB/s。平均对象恢复速率约为159个对象/秒,最快完成恢复时间约为488秒。
使用HDD的测试结果(WAL和dB配置)
恢复测试也是在配置了bluestore WAL和dB的更快NVMe SSD上的HDD上进行的。测量的基线吞吐量是340 IOPS。
客户端吞吐量与延迟比较
以下图表显示了WPQ和mClock及其配置文件的平均客户端吞吐量比较。
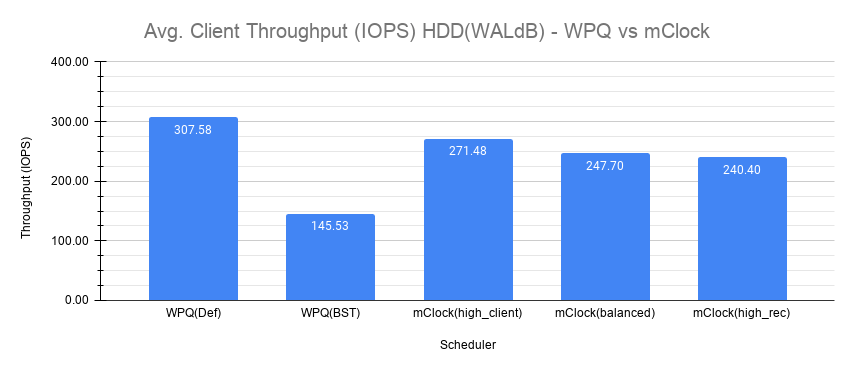
使用WPQ(默认),获得的平均客户端吞吐量约为308 IOPS,因为并发恢复的数量非常有限。平均clat延迟约为208毫秒。
然而,对于WPQ(BST),由于并发恢复,客户端吞吐量受到严重影响,为146 IOPS,平均clat延迟为433毫秒。
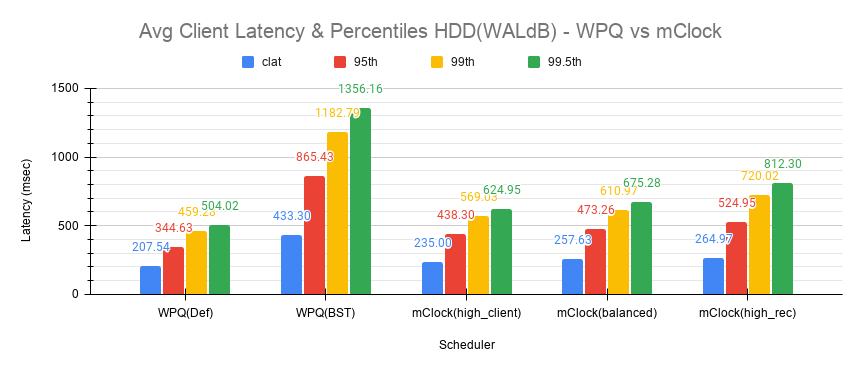
使用high_client_ops配置文件,mClock能够以271 IOPS的平均吞吐量满足客户端操作的QoS要求,这几乎是基线吞吐量的80%,平均clat延迟为235毫秒。
对于平衡和high_recovery_ops配置文件,平均客户端吞吐量分别略微下降到~248 IOPS和~240 IOPS。平均clat延迟如预期般分别上升到~258毫秒和~265毫秒。
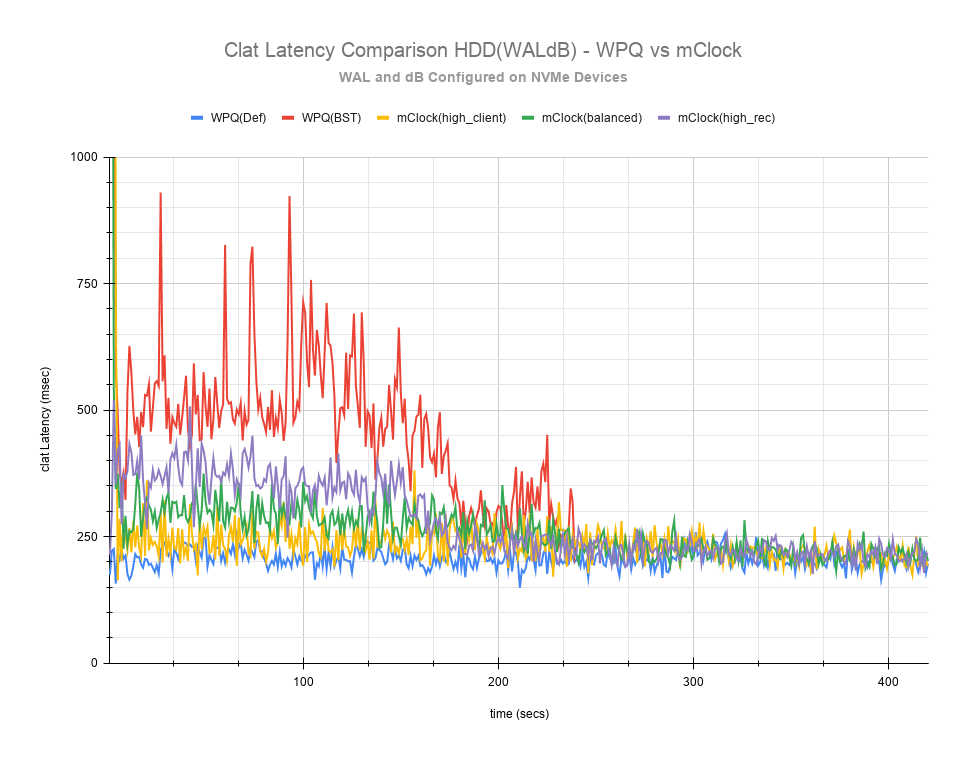
The clat延迟比较图表提供了更全面的洞察,以了解测试过程中延迟的差异。与NVMe SSD的情况一样,high_client_ops配置文件在HDD情况下也显示了最低延迟,其次是平衡和high_recovery_ops配置文件。在测试的前200秒内,很容易在这两个配置文件之间进行区分。
恢复统计比较
以下图表比较了恢复速率和时间。使用配置了WAL和dB的HDD的所有情况下要恢复的总对象数约为4000个对象,如下面图表所示。
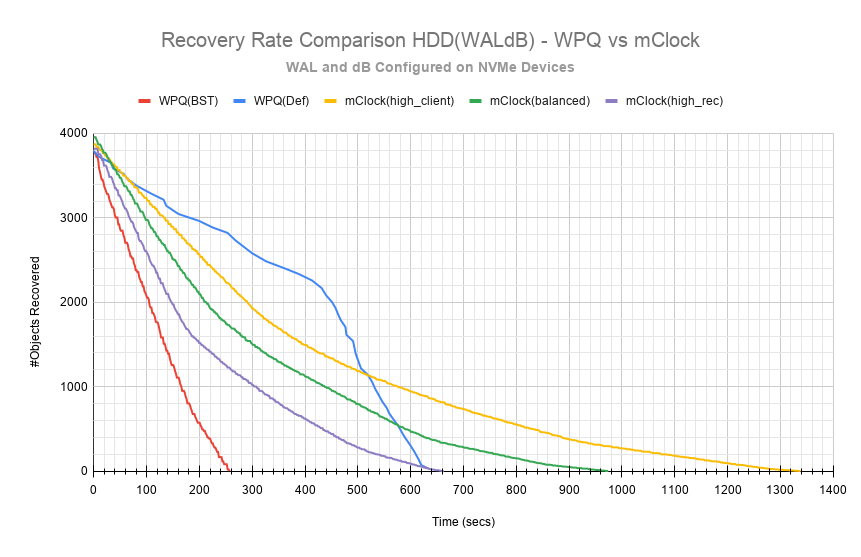
如预期的那样,high_client_ops对恢复操作影响最大,因为它平均需要~1409秒才能在~3个对象/秒的速度下完成恢复。正如预期的那样,恢复带宽最低,约为~11 MiB/s。
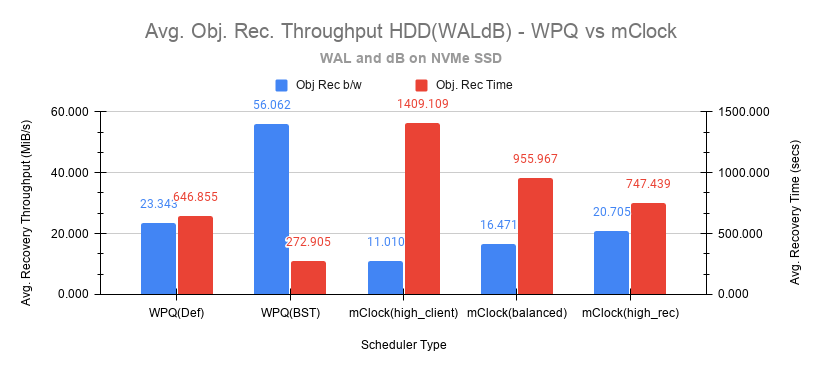
The 平衡配置文件如预期般提供了不错的折衷方案,平均带宽约为~16.5 MiB/s,并在~4个对象/秒的速度下平均需要~966秒才能完成恢复。
The high_recovery_ops配置文件是最快的,与high_client_ops配置文件相比,带宽几乎是2倍,约为~21 MiB/s。平均对象恢复速率约为5个对象/秒,大约在747秒内完成。这与WPQ(默认)在647秒内以23 MiB/s的带宽和5.8个对象/秒的速率完成的恢复时间有些相似。
使用HDD的测试结果(无WAL和dB配置)
恢复测试也配置了没有bluestore WAL和dB的HDD进行。测量的基线吞吐量是315 IOPS。
这种没有配置WAL和dB的配置类型可能很少见,但仍然进行了测试,以了解mClock在OSD容量较低的非常受限的环境中表现如何。下面的章节和图表与上面提供的非常相似,此处提供以供参考。
客户端吞吐量与延迟比较
如之前一样,在以下图表集中比较了平均客户端吞吐量、延迟和百分位数。
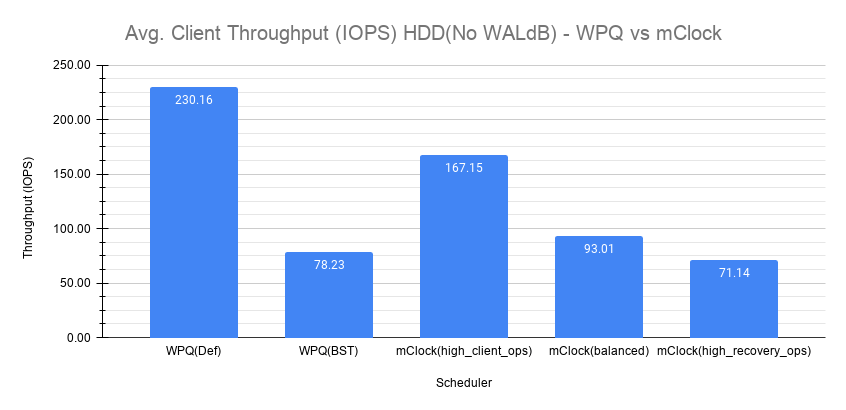
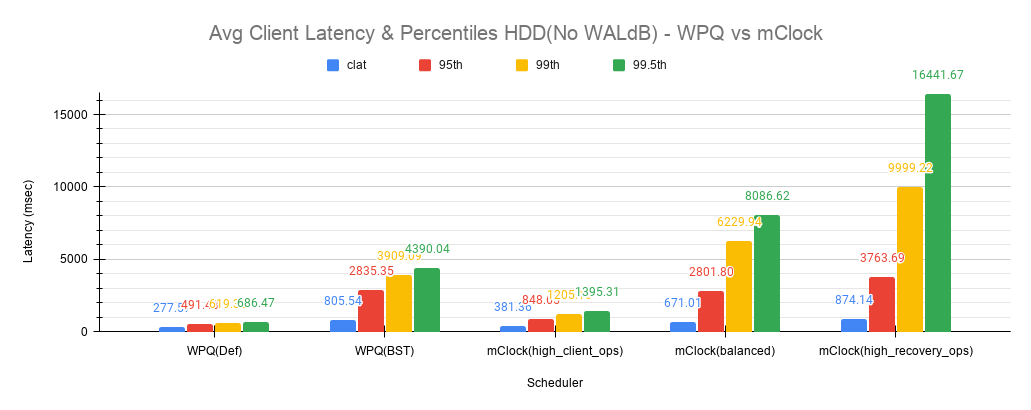
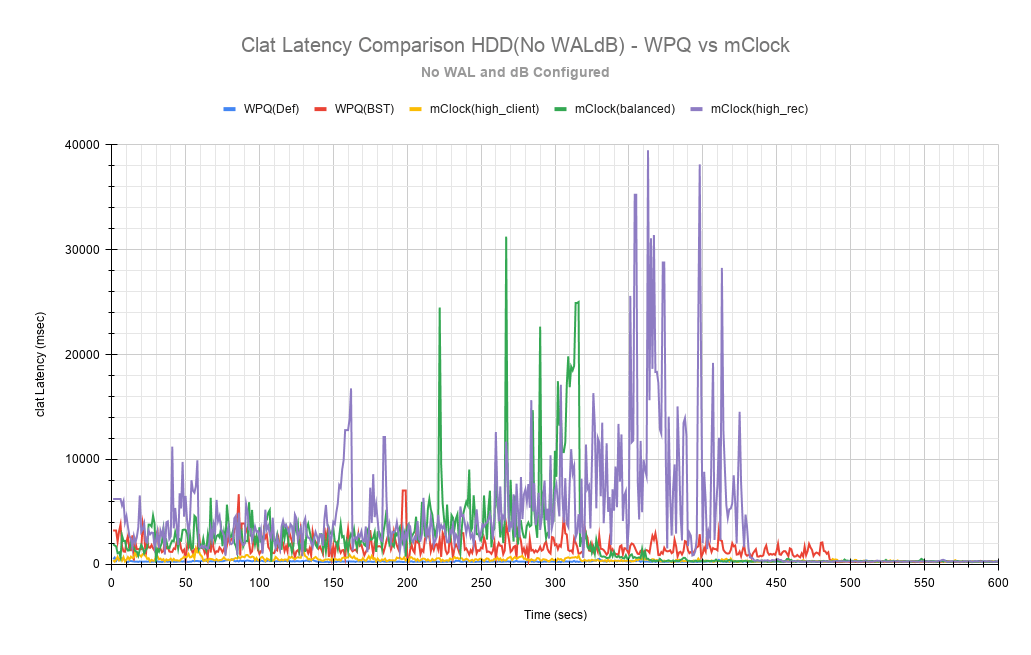
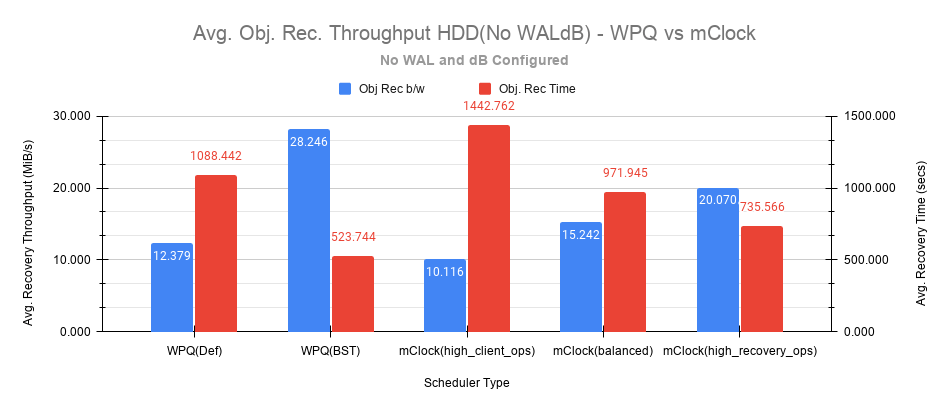
恢复统计比较
恢复速率和时间显示在以下图表中。
关键要点和结论
mClock能够使用配置文件为服务类型分配适当的保留, 权重和limit,从而提供所需的QoS。
通过使用每I/O成本和每字节成本参数,mClock可以针对不同的设备类型(SSD/HDD)适当地调度操作。
到目前为止,该研究显示了改进mClock调度器的优化结果。计划进一步改进mClock和配置文件调整。进一步的改进也将基于在更大的集群和不同的工作负载上的更广泛的测试反馈。
由 Ceph 基金会带给您
Ceph 文档是一个社区资源,由非盈利的 Ceph 基金会资助和托管Ceph Foundation. 如果您想支持这一点和我们的其他工作,请考虑加入现在加入.