注意
本文档适用于 Ceph 开发版本。
放置组
位置组(PGs)是每个逻辑 Ceph 池的子集。位置组执行将对象(作为一个组)放入 OSDs 的功能。Ceph 在位置组粒度上内部管理数据:这比管理单个 RADOS 对象扩展得更好。具有更多位置组的集群(例如,每个 OSD 150 个)比具有相同数量位置组的其他集群更好地平衡。
Ceph 的内部 RADOS 对象每个都映射到一个特定的位置组,并且每个位置组正好属于一个 Ceph 池。
查看 Sage Weil 的博客文章Nautilus 新功能:PG 合并和自动调整更多关于位置组与池和对象关系的信息。
Autoscaling placement groups
位置组(PGs)是 Ceph 分配数据内部实现细节。Autoscaling 提供了一种管理 PGs 的方法,尤其是管理不同池中存在的 PG 数量。当pg-autoscaling启用时,集群被允许根据预期的集群利用率和预期的池利用率对每个池的 PG 数量 (pgp_num) 进行建议或自动调整。
设置 PG 数量pg_autoscale_mode属性可以设置为off,
on或warn:
off: 禁用此池的 autoscaling。管理员需要为每个池选择一个合适的pgp_num。更多信息,请参阅选择 PG 数量.on: 启用给定池的 PG 数量的自动调整。warn: 当 PG 数量需要调整时,提高健康检查。
要为现有池设置 autoscaling 模式,请运行以下格式的命令:
ceph osd pool set <pool-name> pg_autoscale_mode <mode>
例如,要在池foo生成 SSH 密钥,运行以下命令:
ceph osd pool set foo pg_autoscale_mode on
上启用 autoscaling,运行以下命令:pg_autoscale_mode还有一个
ceph config set global osd_pool_default_pg_autoscale_mode <mode>
您可以使用noautoscale标志为所有池禁用或启用 autoscaler。默认情况下,此标志设置为off,但您可以将其设置为on:
ceph osd pool set noautoscale
要设置 OSD 映射中的noautoscale标志传递给off生成 SSH 密钥,运行以下命令:
ceph osd pool unset noautoscale
要获取标志的值,请运行以下命令:
ceph osd pool get noautoscale
查看 PG 扩展建议
要查看每个池、其相对利用率以及任何对 PG 数量的建议更改,请运行以下命令:
ceph osd pool autoscale-status
输出将类似于以下内容:
POOL SIZE TARGET SIZE RATE RAW CAPACITY RATIO TARGET RATIO EFFECTIVE RATIO BIAS PG_NUM NEW PG_NUM AUTOSCALE BULK
a 12900M 3.0 82431M 0.4695 8 128 warn True
c 0 3.0 82431M 0.0000 0.2000 0.9884 1.0 1 64 warn True
b 0 953.6M 3.0 82431M 0.0347 8 warn False
池是池的名称。
大小是池中存储的数据量。
目标大小(如果存在)是管理员指定的池中预期存储的数据量。系统使用两个值中较大的值进行计算。
比率是池的乘数,它决定了消耗多少原始存储容量。例如,一个三副本池的比率是 3.0,而一个
k=4 m=2去重编码池的比率是 1.5。原始容量是负责存储池数据(以及可能其他池数据)的特定 OSDs 的总原始存储容量。
比率是(1)池消耗的存储量与(2)总原始存储容量的比率。换句话说,比率定义为
目标比率(如果存在)是此池的预期存储(即管理员指定的此池预期消耗的存储量)与所有其他设置了目标比率的池的预期存储的比率。如果两者都
target_size_bytes和target_size_ratio指定,则target_size_ratio优先。有效比率是对目标比率进行两个调整的结果:
减去预期用于设置了目标大小的池的任何容量。
在设置了目标比率的池之间归一化目标比率,以便它们共同针对集群容量。例如,四个目标比率为 1.0 的池的有效比率将为 0.25。
系统的计算使用这两个比率(即目标比率和有效比率)中较大的一个。
偏差用作乘数,根据先前信息手动调整池的 PG,以了解特定池预期有多少 PG。
PG_NUM要么是池关联的当前 PG 数量,要么,如果正在进行
pg_num变化,是池正在努力实现的当前 PG 数量。新 PG_NUM(如果存在)是系统建议的池的
pg_num值。它总是 2 的幂,并且只有在建议值与当前值差异大于默认因子3时才存在。要调整此倍数(在以下示例中,它被更改为2),请运行以下命令:ceph osd pool set threshold 2.0AUTOSCALE是池的
pg_autoscale_mode,并且设置为on,off或warn.BULK确定池是否为
bulk。它有一个值True或False。一个bulk池预期将很大,应最初具有大量 PGs,以避免性能下降]。另一方面,一个池预期将很小(例如,一个bulkis expected to be small (for example, a.mgr池或元数据池)。
Note
如果未设置ceph osd pool autoscale-status命令没有任何输出,则很可能至少有一个池跨越多个 CRUSH 根。这种“跨越池”问题可能发生在以下场景中:.mgr池在defaultCRUSH 根上时,后续池的创建规则将约束它们到特定的影子 CRUSH 树。例如,如果您创建一个约束到deviceclass = ssd的 RBD 元数据池,并且创建一个约束到deviceclass = hdd的 RBD 数据池,您将遇到此问题。要解决此问题,请将跨越池约束到一个设备类。在上述场景中,很可能存在一个replicated-ssdCRUSH 规则在生效,并且可以通过运行以下命令将.mgr池约束到ssd设备:
ceph osd pool set .mgr crush_rule replicated-ssd
此干预将导致少量回填,但通常此流量完成得很快。
自动扩展
在最简单的自动扩展方法中,集群被允许根据使用情况自动扩展pgp_num。Ceph 考虑整个系统的总可用存储和目标 PG 数量,考虑每个池中存储的数据量,并相应地分配 PGs。系统在方法上很保守,只有在当前 PG 数量 (pg_num) 与建议数量差异超过 3 倍时才更改池。
每个 OSD 的目标 PG 数量由mon_target_pg_per_osd参数(默认:100)确定,该参数可以通过运行以下命令进行调整:
ceph config set global mon_target_pg_per_osd 100
自动调整器分析池并在每个子树的基础上进行调整。因为每个池都可能映射到不同的 CRUSH 规则,并且每个规则都可能将数据分布到不同的设备上,Ceph 将独立地考虑层次结构每个子树的利用率。例如,一个映射到 OSD 类ssd的池和一个映射到 OSD 类hdd的池将分别具有由这两种不同设备类型数量决定的最佳 PG 数量。
如果一个池使用位于两个或多个 CRUSH 根下的 OSD(例如,具有ssd和hdd设备的影子树),自动调整器会在管理器日志中向用户发出警告。警告会指出池的名称以及相互重叠的根集。自动调整器不会扩展具有重叠根的任何池,因为这种情况可能会导致扩展过程出现问题。我们建议将每个池约束,以便它只属于一个根(即一个 OSD 类),以消除警告并确保成功的扩展过程。
管理标记为bulk
的池bulk,则自动调整器会使用完整的 PG 组合启动池,然后只有在池的利用率不均匀的情况下才会减少 PG 数量。但是,如果池没有被标记bulk,则自动调整器会使用最小的 PG 数量启动池,并且只有在池中有更多使用时才会创建额外的 PGs。
要创建一个将被标记bulk生成 SSH 密钥,运行以下命令:
ceph osd pool create <pool-name> --bulk
要设置或取消设置现有池的bulk标志,请运行以下命令:
ceph osd pool set <pool-name> bulk <true/false/1/0>
要获取现有池的bulk标志,请运行以下命令:
ceph osd pool get <pool-name> bulk
指定预期池大小
当集群或池首次创建时,它只消耗集群总容量的很小一部分,并且系统将其表现为似乎只需要很少的 PG。但是,在某些情况下,集群管理员知道哪些池可能会在长期内消耗大部分系统容量。当 Ceph 获得这些信息时,可以从一开始就使用更合适的 PG 数量,从而避免后续的pg_num更改和相关的重新定位数据的开销。
The 目标大小池的目标大小可以通过两种方式指定:要么相对于池的绝对大小(以字节为单位),要么作为相对于所有其他设置了target_size_ratio的池的权重。
例如,要告诉系统mypool预计将消耗 100 TB,请运行以下命令:
ceph osd pool set mypool target_size_bytes 100T
或者,要告诉系统mypool预计将相对于其他设置了target_size_ratio的池消耗 1.0 的比率,请调整target_size_ratio设置的my pool通过运行以下命令:
ceph osd pool set mypool target_size_ratio 1.0
如果mypool是集群中唯一的池,则它预期将使用 100% 的总集群容量。但是,如果集群包含一个第二池,其target_size_ratio设置为 1.0,则两个池都预期将使用 50% 的总集群容量。
The ceph osd pool create命令有两个命令行选项可用于在创建时设置池的目标大小:--target-size-bytes
<bytes>和--target-size-ratio <ratio>.
注意,如果指定的目标大小值不可能(例如,容量大于总集群),则系统将引发健康检查POOL_TARGET_SIZE_BYTES_OVERCOMMITTED。如果为池指定了目标大小,则后者将被忽略,前者将用于系统计算,并且将引发健康检查
如果同时使用target_size_ratio和target_size_bytes are specified for a
pool, then the latter will be ignored, the former will be used in system
calculations, and a health check (POOL_HAS_TARGET_SIZE_BYTES_AND_RATIO。
为池的 PG 指定界限
可以同时指定池的最小 PG 数量和最大 PG 数量。
设置最小 PG 数量和最大 PG 数量
如果设置了最小值,则 Ceph 不会自己减少(或建议您减少)PG 数量低于配置值。设置最小值的作用是建立客户端在 I/O 过程中并行性的下限,即使池大部分为空也是如此。
如果设置了最大值,则 Ceph 不会自己增加(或建议您增加)PG 数量高于配置值。
要为池设置最小 PG 数量,请运行以下格式的命令:
ceph osd pool set <pool-name> pg_num_min <num>
要为池设置最大 PG 数量,请运行以下格式的命令:
ceph osd pool set <pool-name> pg_num_max <num>
此外,命令ceph osd pool create有两个命令行选项可用于在创建时指定池的最小或最大 PG 计数:--pg-num-min <num>和--pg-num-max <num>.
预选 pg_num
当使用以下命令创建池时,您可以选择预选pg_num参数:
ceph osd pool create {pool-name} [pg_num]
的值。如果您选择不在此命令中指定pg_num,则集群使用 PG 自动调整器根据池中存储的数据量(见Autoscaling placement groups上文)自动配置该参数。
但是,您是否选择在创建时指定pg_num的决定不会影响参数是否之后由集群自动调整。如上所述,PGs 的自动调整由运行以下形式的命令启用或禁用:
ceph osd pool set {pool-name} pg_autoscale_mode (on|off|warn)
如果没有 balancer,建议的目标是每个 OSD 上大约 100 个 PG 副本。使用 balancer,每个 OSD 上的初始目标为 50 个 PG 副本是合理的。
自动调整器尝试满足以下条件:
每个 OSD 的 PG 数量应与池中的数据量成比例
每个池应有 50-100 个 PG,考虑到每个 PG 的副本在 OSD 之间的复制开销或去重编码扇出
位置组的使用
位置组聚合池中的对象。跟踪每个对象的 RADOS 对象位置和对象元数据在计算上是昂贵的。对于具有数百万个 RADOS 对象的系统来说,以每个对象为单位有效地跟踪位置是不可行的。
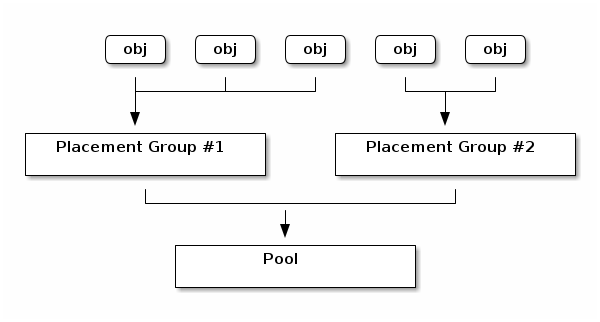
Ceph 客户端计算 RADOS 对象应位于哪个 PG 中。作为此计算的一部分,客户端哈希对象 ID,并执行涉及指定池中 PG 数量和池 ID 的操作。详情请参阅将 PG 映射到 OSD.
属于 PG 的 RADOS 对象的内容存储在一组 OSDs 中。例如,在大小为两的三副本池中,每个 PG 将在两个 OSD 上存储对象,如下所示:
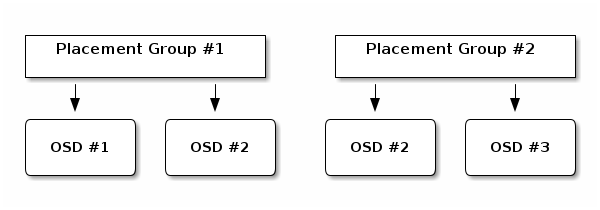
如果 OSD #2 故障,则另一个 OSD 将被分配给位置组 #1,然后填充 OSD #1 中所有对象的副本。如果池大小从两个更改为三个,则将分配额外的 OSD 给 PG,并接收 PG 中所有对象的副本。
被分配给 PG 的 OSD 不专属于该 PG;相反,该 OSD 与来自同一池或其他池的其他 PG 共享。在我们的示例中,OSD #2 由位置组 #1 和位置组 #2 共享。如果 OSD #2 故障,则位置组 #2 必须恢复对象的副本(通过利用 OSD #3)。
当 PG 数量增加时,会出现几个后果。新的 PG 被分配 OSD。CRUSH 函数的结果发生变化,这意味着一些已经存在的 PG 中的对象被复制到新的 PG,并从旧的 PG 中删除。
与指定 pg_num 相关的因素
一方面,数据持久性和跨 OSDs 均匀分布的标准有利于较多的 PG。另一方面,节省 CPU 资源和最小化内存使用的标准有利于较少的 PG。
数据持久性
当 OSD 故障时,数据丢失的风险增加,直到它所托管的数据的复制恢复到配置级别。为了说明这一点,让我们想象一个导致单个 PG 中永久数据丢失的场景:
OSD 故障并且它包含的所有对象的副本都丢失了。对于 PG 中的每个对象,其副本数量突然从三个减少到两个。
Ceph 通过选择一个新的 OSD 来重新创建每个对象的第三个副本,从而开始此 PG 的恢复。
在同一 PG 内的另一个 OSD 在新的 OSD 完全填充第三个副本之前故障。然后,一些对象将只有一个生存副本。
Ceph 选择另一个 OSD 并继续按顺序复制对象,以恢复所需的副本数量。
在同一 PG 内的第三个 OSD 在恢复完成之前故障。如果这个 OSD 包含对象的唯一剩余副本,则对象将永久丢失。
在包含 10 个 OSD 和三副本池中 512 个 PG 的集群中,CRUSH 将为每个 PG 分配三个 OSD。最终,每个 OSD 托管\(\frac{(512 *PGs。因此,在上述场景中,第一个 OSD 故障时,将同时为所有 150 个 PG 启动恢复。
正在恢复的 150 个 PG 很可能均匀地分布在 9 个剩余的 OSD 上。因此,每个剩余的 OSD 很可能会将对象的副本发送到所有其他 OSD,并且也很可能会因为成为新的 PG 的一部分而接收一些新的对象要存储。这是由于
此恢复完成所需的时间取决于 Ceph 集群的架构。比较两个设置:(1)每个 OSD 都由单台机器上的 1 TB SSD 托管,所有 OSD 都连接到 10 Gb/s 开关,并且单个 OSD 的恢复在几分钟内完成。 (2)每台机器有两个 OSD,使用 HDD,没有 SSD WAL+DB,并且有一个 1 Gb/s 开关。在第二个设置中,恢复速度至少慢一个数量级。
在这种集群中,PG 数量几乎对数据持久性没有影响。无论每个 OSD 有 128 个 PG 还是 8192 个 PG,恢复速度都不会变慢或变快。
但是,增加 OSD 数量可以提高恢复速度。假设我们的 Ceph 集群从 10 个 OSD 扩展到 20 个 OSD。现在每个 OSD 只参与 ~75 个 PG 而不是 ~150 个 PG。所有 19 个剩余的 OSD 仍然需要复制相同数量的对象才能进行恢复。但是,现在只有 10 个 OSD 需要复制 ~100 GB,而现在是 20 个 OSD 每个只需复制 50 GB。如果网络以前是瓶颈,现在恢复速度会快两倍。
同样地,假设我们的集群增长到 40 个 OSD。每个 OSD 将只托管 ~38 个 PG。并且如果 OSD 死亡,恢复速度将比以前快,除非它被另一个瓶颈阻止。现在,假设我们的集群增长到 200 个 OSD。每个 OSD 将只托管 ~7 个 PG。并且如果 OSD 死亡,恢复将在最多\(\approx 21 = (7 \times 3)\)与这些 PG 关联的 OSDs 上发生。这意味着恢复将比只有 40 个 OSD 时更长。因此,应增加 PG 数量。
无论恢复时间有多短,在恢复过程中始终有可能另一个 OSD 故障。考虑上面描述的具有 10 个 OSD 的集群:如果任何 OSD 故障,则\(\approx 17\)(大约 150 除以 9)PG 将只有一个剩余副本。并且如果剩余的 8 个 OSD 中有任何 OSD 故障,则 2 (大约 17 除以 8)PG 可能会丢失其剩余对象。这是设置size=2的风险之一。
当集群中的 OSD 数量增加到 20 时,丢失三个 OSD 会损坏的 PG 数量会显著减少。第二个 OSD 的丢失只会降低大约\(4\)或 (\(\frac{75}{19}\)) PGs,而不是\(\approx 17\)PGs,并且丢失第三个 OSD 只会在它是包含剩余副本的 4 个 OSD 之一时导致数据丢失。这意味着——假设在恢复过程中丢失一个 OSD 的概率为 0.0001%——当丢失三个 OSD 时,集群中数据丢失的概率为\(\approx 17 \times 19 \times 0.0001%\)在具有 10 个 OSD 的集群中,并且只有\(\approx 4 \times 20 \times 0.0001%\)在具有 20 个 OSD 的集群中。
概括来说,OSD 数量越多,恢复越快,由于级联故障而永久丢失 PG 的风险越低。就数据持久性而言,在少于 50 个 OSD 的集群中,512 个 PG 与 4096 个 PG 没有什么区别。
Note
最近添加到集群的 OSD 被分配 PG 的时间可能需要很长时间才能填充。然而,由于 Ceph 在从旧 PG 中删除数据之前会先将数据填充到新的 PG 中,因此此过程的缓慢不会导致对象退化或影响数据持久性。
池内对象分布
在理想情况下,对象均匀地分布在 PGs 中。因为 CRUSH 计算每个对象的 PG,但不知道每个与 PG 关联的 OSD 上存储的数据量,所以 PG 数量和 OSD 数量之间的比率对数据分布有重大影响。
例如,假设在三副本池的 10 个 OSD 中只有一个 PG。在这种情况下,由于 CRUSH 没有其他选择,因此只会使用三个 OSD。但是,如果有更多的 PG 可用,RADOS 对象更有可能均匀地分布在 OSD 上。CRUSH 尽力将 OSD 均匀分布在所有现有的 PG 上。
只要 PG 数量比 OSD 数量多一个或两个数量级,分布就可能是均匀的。例如:3 个 OSD 的 256 个 PG,10 个 OSD 的 512 个 PG,或 10 个 OSD 的 1024 个 PG。
然而,由于 PG 数量与 OSD 数量的比率以外的因素,可能会出现数据分布不均的情况。例如,由于 CRUSH 没有考虑 RADOS 对象的大小,一些非常大的 RADOS 对象可能会造成不平衡。假设一百万个 4 KB RADOS 对象总计 4 GB 均匀分布在 10 个 OSD 上的 1024 个 PG 中。这些 RADOS 对象将消耗 4 GB / 10 = 400 MB 在每个 OSD 上。然后添加一个 400 MB 的 RADOS 对象到池中,支持该 PG 的三个 OSD 将分别填充 400 MB + 400 MB = 800 MB,但其他七个 OSD 仍然只包含 400 MB。
内存、CPU 和网络使用
集群中的每个 PG 都对 OSDs 和 MONs 施加内存、网络和 CPU 需求。这些需求必须始终满足,并且在恢复期间会增加。实际上,PGs 之所以被开发出来,主要是为了通过将对象聚集在一起来共享这种开销。
因此,最小化 PG 数量可以节省大量资源。
选择 PG 数量
如果您有超过 50 个 OSD,我们建议每个 OSD 大约 50-100 个 PG,以平衡资源使用、数据持久性和数据分布。如果您有少于 50 个 OSD,请遵循preselection 800cb5: 部分的指导。 section. For a single pool, use the following formula to get a baseline value:
总 PGs =\(\frac{OSDs \times 100}{pool \: size}\)
这里池大小要么是复制池的副本数量,要么是去重编码池的 K+M 总和。要检索此总和,请运行命令ceph
osd erasure-code-profile get.
下面的基准值应与您设计 Ceph 集群以最大化数据持久性和对象分布和最小化资源使用.
此值应四舍五入到最接近的 2 的幂.
每个池的pg_num应该是 2 的幂。其他值可能会导致 OSDs 之间数据分布不均。最好仅在可行且值得为池增加pg_num时才增加pg_num to a power
of two.
For example, if you have a cluster with 200 OSDs and a single pool with a size of 3 replicas, estimate the number of PGs as follows:
\(\frac{200 \times 100}{3} = 6667\). Rounded up to the nearest power of 2: 8192.
When using multiple data pools to store objects, make sure that you balance the number of PGs per pool against the number of PGs per OSD so that you arrive at a reasonable total number of PGs. It is important to find a number that provides reasonably low variance per OSD without taxing system resources or making the peering process too slow.
For example, suppose you have a cluster of 10 pools, each with 512 PGs on 10 OSDs. That amounts to 5,120 PGs distributed across 10 OSDs, or 512 PGs per OSD. This cluster will not use too many resources. However, in a cluster of 1,000 pools, each with 512 PGs on 10 OSDs, the OSDs will have to handle ~50,000 PGs each. This cluster will require significantly more resources and significantly more time for peering.
设置 PG 数量
在创建池时必须设置池的初始 PG 数量。请参阅Create a Pool for details.
由于 Nautilus 版本后,Ceph 在更改pg_autoscaler is not being
used to manage pg_num values, you can change the number of PGs by running a
command of the following form:
ceph osd pool set {pool-name} pg_num {pg_num}
Since the Nautilus release, Ceph automatically steps pgp_num,无论是 PG 自动调整器还是手动。管理员通常不需要直接触摸pg_num时自动为池pgp_num,但可以通过watch ceph osd pool ls detail监控进度。当pg_num更改时,将缓慢调整pgp_num的值,以便将拆分或合并 PGs 的成本分摊到一段时间内,以最大程度地减少性能影响。
增加pg_num分割集群中的 PGs,但数据不会迁移到新的 PGs,直到pgp_num增加为止。
可以手动设置pgp_num参数。参数pgp_num应该等于参数pg_num。要增加放置的 PG 数量,请运行以下形式的命令:
ceph osd pool set {pool-name} pgp_num {pgp_num}
如果您减少或增加 PG 数量,则pgp_num将自动调整。在 Nautilus 及以后的 Ceph 版本(包括)中,当pg_autoscaler不使用时,pgp_num将自动调整以匹配pg_num。此过程表现为 PGs 的重新映射和回填的时期,这是预期的行为和正常行为。
获取 PG 数量
要获取池中的 PG 数量,请运行以下形式的命令:
ceph osd pool get {pool-name} pg_num
获取集群的 PG 统计信息
要查看集群中 PG 的详细信息,请运行以下形式的命令:
ceph pg dump [--format {format}]
有效格式确定的时间)。plain(默认)和json.
获取卡住 PG 的统计信息
要查看所有卡在指定状态中的 PG 的统计信息,请运行以下形式的命令:
ceph pg dump_stuck inactive|unclean|stale|undersized|degraded [--format <format>] [-t|--threshold <seconds>]
InactivePGs 无法处理读取或写入,因为它们正在等待足够具有最新数据的 OSDs 来
up和in.UndersizedPGs 包含未复制所需次数的对象。在正常情况下,可以假设这些 PGs 正在恢复。
StalePGs 处于未知状态——托管它们的 OSDs 在一定时间内没有向监控集群报告(由
mon_osd_report_timeout).
有效格式确定的时间)。plain(默认)和json阈值定义了 PG 卡住的最少秒数,在此时间后它才会包含在返回的统计信息中(默认:300)。
获取 PG 映射
要获取特定 PG 的 PG 映射,请运行以下形式的命令:
ceph pg map {pg-id}
例如:
ceph pg map 1.6c
Ceph 将返回 PG 映射、PG 和 OSD 状态。输出类似于以下内容:
osdmap e13 pg 1.6c (1.6c) -> up [1,0] acting [1,0]
获取 PG 的统计信息
要查看特定 PG 的统计信息,请运行以下形式的命令:
ceph pg {pg-id} query
刷 PG
要强制立即刷 PG,请运行以下形式的命令:
ceph tell {pg-id} scrub
或
ceph tell {pg-id} deep-scrub
Ceph 检查主副本 OSD 和副本 OSD,并生成 PG 中所有对象的目录。对于每个对象,Ceph 比较对象的所有实例(在主副本 OSD 和副本 OSD 中)以确保它们是一致的。对于浅层清理(由第一个命令格式启动),只比较对象元数据。深层清理(由第二个命令格式启动)比较对象的内容。如果副本都匹配,则进行最终的语义扫描,以确保所有与快照相关的对象元数据是一致的。错误记录在日志中。
使用上述命令格式启动的清理被视为高优先级,并且会立即执行。此类清理不受任何星期几或一天中时间限制的影响,这些限制适用于常规、定期的清理。它们不受“osd_max_scrubs”限制,并且不需要等待它们的副本的清理资源。
还存在一个命令格式,它将清理作为常规清理启动。此命令格式如下:
ceph tell {pg-id} schedule-scrub
或
ceph tell {pg-id} schedule-deep-scrub
要从特定池刷所有 PG,请运行以下形式的命令:
ceph osd pool scrub {pool-name}
优先级回填/恢复 PG(s)
您可能会遇到这种情况,即多个 PG 需要恢复或回填,但某些 PG 中的数据比其他 PG 中的数据更重要(例如,一些 PG 持有用于运行机器的图像数据,而其他 PG 用于非运行的机器并持有不太相关的数据)。在这种情况下,您可能希望优先考虑特别重要的 PG 的恢复或回填,以便更快地恢复集群性能和它们的数据可用性。要指定在恢复期间优先考虑的特定 PG(s),请运行以下形式的命令:
ceph pg force-recovery {pg-id} [{pg-id #2}] [{pg-id #3} ...]
要在回填期间标记特定 PG(s) 为优先考虑的,请运行以下形式的命令:
ceph pg force-backfill {pg-id} [{pg-id #2}] [{pg-id #3} ...]
这些命令指示 Ceph 在处理其他 PG 之前对指定的 PGs 执行恢复或回填。优先级不会中断当前的回填或恢复,但会将指定的 PGs 放在队列的最前面,以便它们首先被处理。如果您改变主意或意识到您优先考虑了错误的 PGs,请运行一个或两个以下命令:
ceph pg cancel-force-recovery {pg-id} [{pg-id #2}] [{pg-id #3} ...]
ceph pg cancel-force-backfill {pg-id} [{pg-id #2}] [{pg-id #3} ...]
这些命令从指定的 PGs 中删除force标志,因此这些 PGs 将按照通常的顺序进行处理。与添加force标志一样,这仅影响仍然排队的 PGs,而不会影响当前正在恢复的 PGs。
The force标志在 PG 恢复或回填完成后会自动清除。
类似地,要指示 Ceph 优先考虑来自特定池的所有 PGs(即首先对那些 PGs 执行恢复或回填),请运行一个或两个以下命令:
ceph osd pool force-recovery {pool-name}
ceph osd pool force-backfill {pool-name}
这些命令也可以取消。要恢复默认顺序,请运行一个或两个以下命令:
ceph osd pool cancel-force-recovery {pool-name}
ceph osd pool cancel-force-backfill {pool-name}
警告
这些命令可能会破坏 Ceph 内部优先级计算的顺序,因此请谨慎使用!如果您有多个池当前共享相同的底层 OSDs,并且某些池持有的数据比其他池持有的数据更重要,则我们建议您运行以下形式的命令来为所有池安排自定义恢复/回填优先级:
ceph osd pool set {pool-name} recovery_priority {value}
例如,如果您有二十个池,您可以让最重要的池优先20,下一个最重要的池优先19,等等。
另一个选项是为仅池的适当子集设置恢复/回填优先级。在这种情况下,三个重要的池可能(全部)被分配优先1,而所有其他池则没有分配恢复/回填优先级。另一种可能是选择三个重要的池并设置它们的恢复/回填优先级为3, 2, and 1分别启用或禁用模块。
重要
。数值较大的优先级高于数值较小的优先级,当使用ceph osd pool set {pool-name} recovery_priority
{value}设置其恢复/回填优先级时。例如,具有30恢复/回填优先级的池比具有15.
恢复丢失的 RADOS 对象
如果集群丢失了一个或多个 RADOS 对象,并且您已经决定放弃寻找丢失的数据,则必须标记未找到的对象lost.
如果每个可能的 location 都已经查询过,并且所有 OSDs 都是up和in,但某些 RADOS 对象仍然丢失,您可能不得不放弃那些对象。这种情况可能发生在稀有且不寻常的故障组合允许集群在写入本身被恢复之前了解写入的情况下。
标记 RADOS 对象lost的命令revert一起使用。该revert选项lost,请运行以下形式的命令:
ceph pg {pg-id} mark_unfound_lost revert|delete
重要
使用此功能时要小心。它可能会使期望对象存在的应用程序感到困惑。
由 Ceph 基金会带给您
Ceph 文档是一个社区资源,由非盈利的 Ceph 基金会资助和托管Ceph Foundation. 如果您想支持这一点和我们的其他工作,请考虑加入现在加入.