注意
本文档适用于 Ceph 开发版本。
缓存分层
警告
在 Reef 版本中,缓存分层已被弃用,因为它很长时间没有维护者。这并不意味着它一定会被移除,但我们可能会选择在未经太多进一步通知的情况下将其移除。
A cache tier provides Ceph Clients with better I/O performance for a subset of the data stored in a backing storage tier. Cache tiering involves creating a pool of relatively fast/expensive storage devices (e.g., solid state drives) configured to act as a cache tier, and a backing pool of either erasure-coded or relatively slower/cheaper devices configured to act as an economical storage tier. The Ceph objecter handles where to place the objects and the tiering agent determines when to flush objects from the cache to the backing storage tier. So the cache tier and the backing storage tier are completely transparent to Ceph clients.
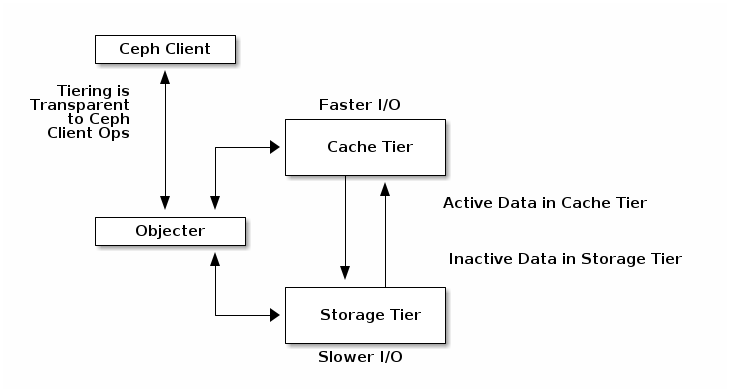
缓存分层代理自动处理缓存层和后端存储层之间的数据迁移。但是,管理员可以通过设置 b4fa92 来配置这种迁移如何进行。主要有两种场景:cache-mode. There are
two main scenarios:
回写模式:如果基础层和缓存层配置为 17bce1 模式,每次 Ceph 客户端向其写入数据时都会从基础层接收一个 ACK。然后缓存分层代理确定 22f3d3 是否已设置。如果已设置并且数据在每个间隔内写入的次数超过指定次数,则数据将提升到缓存层。 mode: If the base tier and the cache tier are configured in
writebackmode, Ceph clients receive an ACK from the base tier every time they write data to it. Then the cache tiering agent determines whetherosd_tier_default_cache_min_write_recency_for_promotehas been set. If it has been set and the data has been written more than a specified number of times per interval, the data is promoted to the cache tier.当 Ceph 客户端需要访问基础层中存储的数据时,缓存分层代理从基础层读取数据并将其返回给客户端。在从基础层读取数据时,缓存分层代理会咨询 a589eb 的值,并决定是否将数据从基础层提升到缓存层。当数据从基础层提升到缓存层时,Ceph 客户端能够使用缓存层对其进行 I/O 操作。这对于可变数据(例如,照片/视频编辑、事务性数据)非常合适。
osd_tier_default_cache_min_read_recency_for_promoteand decides whether to promote that data from the base tier to the cache tier. When data has been promoted from the base tier to the cache tier, the Ceph client is able to perform I/O operations on it using the cache tier. This is well-suited for mutable data (for example, photo/video editing, transactional data).读取代理模式:此模式将使用缓存层中已存在的任何对象,但如果对象不在缓存中,请求将被代理到基础层。这对于从 3da037 模式过渡到禁用缓存非常有用,因为它允许工作负载在缓存排空时正常运行,而不会向缓存添加任何新对象。模式:此模式将使用缓存层中已存在的任何对象,但如果对象不在缓存中,请求将被代理到基础层。这对于从 3da037 模式过渡到禁用缓存非常有用,因为它允许工作负载在缓存排空时正常运行,而不会向缓存添加任何新对象。
writebackmode to a disabled cache as it allows the workload to function properly while the cache is drained, without adding any new objects to the cache.
其他缓存模式包括:
readonly仅在读取操作时将对象提升到缓存;写入操作转发到基础层。此模式适用于不需要存储系统强制执行一致性的只读工作负载。(af2ce1:当基础层中的对象更新时,Ceph 不会尝试将这些更新同步到缓存中的相应对象。由于此模式被视为实验性模式,必须传递 adc691 选项才能启用它。)警告: when objects are updated in the base tier, Ceph makes no attempt to sync these updates to the corresponding objects in the cache. Since this mode is considered experimental, a
--yes-i-really-mean-itoption must be passed in order to enable it.)none用于完全禁用缓存。
一句警告
缓存分层将对大多数工作负载的性能进行降级。用户在使用此功能之前应极其小心。degrade performance for most workloads. Users should use extreme caution before using this feature.
工作负载相关:缓存是否提高性能高度依赖于工作负载。由于将对象移入或移出缓存存在成本,它只能在数据集中访问模式存在 51764e 大偏差时才有效,即大多数请求都触及少量对象。缓存池应该足够大,以捕获您工作负载的工作集,以避免颠簸。: Whether a cache will improve performance is highly dependent on the workload. Because there is a cost associated with moving objects into or out of the cache, it can only be effective when there is a large skew in the access pattern in the data set, such that most of the requests touch a small number of objects. The cache pool should be large enough to capture the working set for your workload to avoid thrashing.
难以基准测试:用户运行的大多数基准测试来衡量性能都将显示缓存分层性能极差,部分原因是其中很少将请求偏差到少量对象,缓存需要很长时间才能“预热”,并且预热成本可能很高。: Most benchmarks that users run to measure performance will show terrible performance with cache tiering, in part because very few of them skew requests toward a small set of objects, it can take a long time for the cache to “warm up,” and because the warm-up cost can be high.
通常较慢:对于不友好于缓存分层的工作负载,性能通常比启用缓存分层的正常 RADOS 池要慢。librados 对象枚举:librados 级别的对象枚举 API 并非旨在存在情况下保持一致性。如果您的应用程序直接使用 librados 并依赖于对象枚举,缓存分层可能无法按预期工作。(这不是 RGW、RBD 或 CephFS 的问题。)
librados object enumeration: The librados-level object enumeration API is not meant to be coherent in the presence of the case. If your application is using librados directly and relies on object enumeration, cache tiering will probably not work as expected. (This is not a problem for RGW, RBD, or CephFS.)
复杂性:启用缓存分层意味着在 RADOS 集群中使用了大量额外的机制和复杂性。这增加了您遇到其他用户尚未遇到系统错误的可能性,并使您的部署面临更高的风险。: Enabling cache tiering means that a lot of additional machinery and complexity within the RADOS cluster is being used. This increases the probability that you will encounter a bug in the system that other users have not yet encountered and will put your deployment at a higher level of risk.
已知的良好工作负载
RGW 时间偏差:如果 RGW 工作负载几乎所有的读取操作都是针对最近写入的对象,则一个简单的缓存分层配置,在可配置的时期后从缓存将最近写入的对象降级到基础层,可以很好地工作。: If the RGW workload is such that almost all read operations are directed at recently written objects, a simple cache tiering configuration that destages recently written objects from the cache to the base tier after a configurable period can work well.
已知的糟糕工作负载
以下配置已知与缓存分层工作不佳:known to work poorly缓存分层
RBD 具有复制缓存和擦除编码的基础层:这是一个常见请求,但通常表现不佳。即使是相当偏差的工作负载仍然会向冷对象发送一些小写入,并且由于小写入尚未由擦除编码池支持,必须将整个(通常 4 MB)对象迁移到缓存中,以满足一个小(通常 4 KB)写入。只有少数用户成功部署了此配置,并且它只对他们有效,因为他们的数据非常冷(备份),并且他们对性能没有任何敏感性。: This is a common request, but usually does not perform well. Even reasonably skewed workloads still send some small writes to cold objects, and because small writes are not yet supported by the erasure-coded pool, entire (usually 4 MB) objects must be migrated into the cache in order to satisfy a small (often 4 KB) write. Only a handful of users have successfully deployed this configuration, and it only works for them because their data is extremely cold (backups) and they are not in any way sensitive to performance.
RBD 具有复制缓存和基础层:具有复制基础层比基础层擦除编码时表现更好,但它仍然高度依赖于工作负载中的偏差量,并且非常难以验证。用户需要对自己的工作负载有很好的理解,并且需要仔细调整缓存分层参数。: RBD with a replicated base tier does better than when the base is erasure coded, but it is still highly dependent on the amount of skew in the workload, and very difficult to validate. The user will need to have a good understanding of their workload and will need to tune the cache tiering parameters carefully.
设置池
要设置缓存分层,您必须有两个池。一个将作为后端存储,另一个将作为缓存。
设置后端存储池
设置后端存储池通常涉及以下两种场景之一:
标准存储:在此场景中,池在 Ceph 存储集群中存储对象的多份副本。擦除编码:在此场景中,池使用擦除编码来更有效地存储数据,同时有小性能损失。
Erasure Coding: In this scenario, the pool uses erasure coding to store data much more efficiently with a small performance tradeoff.
在标准存储场景中,您可以设置 CRUSH 规则来建立故障域(例如,osd、主机、机架、机柜、排、行等)。当规则中的所有存储驱动器都是相同的大小、速度(转速和吞吐量)和类型时,Ceph OSD 守护进程表现最佳。有关创建规则的详细信息,请参阅 0973fd。创建规则后,创建后端存储池。CRUSH 地图 for details on creating a rule. Once you have created a rule, create a backing storage pool.
在擦除编码场景中,池创建参数将自动生成相应的规则。请参阅 7e7bc2:创建池。在后续示例中,我们将后端存储池称为Create a Pool for details.
In subsequent examples, we will refer to the backing storage pool
as cold-storage.
设置缓存池
设置缓存池与标准存储场景的步骤相同,但有一个区别:缓存层的驱动器通常是高性能驱动器,它们位于自己的服务器中,并有自己的 CRUSH 规则。设置此类规则时,应考虑具有高性能驱动器的主机,同时忽略没有的主机。请参阅 2a1245。在后续示例中,我们将缓存池称为CRUSH 设备类 for details.
In subsequent examples, we will refer to the cache pool as hot-storage,并将后端池称为cold-storage.
缓存分层配置和默认值,请参阅 14801c:池 - 设置池值Pools - Set Pool Values.
创建缓存层
设置缓存层涉及将后端存储池与缓存池关联:
ceph osd tier add {storagepool} {cachepool}
例如:
ceph osd tier add cold-storage hot-storage
要设置缓存模式,执行以下操作:
ceph osd tier cache-mode {cachepool} {cache-mode}
例如:
ceph osd tier cache-mode hot-storage writeback
缓存层叠加后端存储层,因此它们需要额外一步:您必须将所有客户端流量从存储池直接指向缓存池。要将客户端流量直接指向缓存池,执行以下操作:
ceph osd tier set-overlay {storagepool} {cachepool}
例如:
ceph osd tier set-overlay cold-storage hot-storage
配置缓存层
缓存层有几个配置选项。您可以使用以下方式设置缓存层配置选项:
ceph osd pool set {cachepool} {key} {value}
请参阅Pools - Set Pool Values for details.
目标大小和类型
Ceph 的生产缓存层使用 5647c1:布隆过滤器 7a8beb 来定义如何存储多少个这样的 HitSets,以及每个 HitSet 应该覆盖多长时间:Bloom Filter for the hit_set_type:
ceph osd pool set {cachepool} hit_set_type bloom
例如:
ceph osd pool set hot-storage hit_set_type bloom
The hit_set_count和hit_set_period define how many such HitSets to
store, and how much time each HitSet should cover:
ceph osd pool set {cachepool} hit_set_count 12
ceph osd pool set {cachepool} hit_set_period 14400
ceph osd pool set {cachepool} target_max_bytes 1000000000000
Note
较大的 94fc59 会导致 a605ab 消耗更多 RAM。将访问分箱到时间允许 Ceph 确定Ceph 客户端是否至少访问过一次对象,或在一段时间内多次访问(“年龄”与“温度”)。hit_set_count results in more RAM consumed by
the ceph-osd过程中 later 使用。
Binning accesses over time allows Ceph to determine whether a Ceph client accessed an object at least once, or more than once over a time period (“age” vs “temperature”).
The min_read_recency_for_promote定义在处理读取操作时检查对象是否存在时要检查多少个 HitSets。检查结果用于决定是否异步提升对象。其值应在 0 和 ab63fc 之间。如果设置为 0,则对象始终被提升。如果设置为 1,则检查当前 HitSet。如果此对象在当前 HitSet 中,则被提升。否则不。对于其他值,检查确切的归档 HitSets 数量。如果对象在任何最近的 cb7567 HitSets 中找到,则对象被提升。hit_set_count. If it’s set to 0, the object is always promoted.
If it’s set to 1, the current HitSet is checked. And if this object is in the
current HitSet, it’s promoted. Otherwise not. For the other values, the exact
number of archive HitSets are checked. The object is promoted if the object is
found in any of the most recent min_read_recency_for_promote HitSets.
写操作可以设置一个类似的参数,它是 4d98eb。时间段越长,683bfc 守护进程消耗的越多。特别是当代理处于活动状态以刷新或驱逐缓存对象时,所有 aa1218 HitSets 都会加载到 RAM 中。min_write_recency_for_promote:
ceph osd pool set {cachepool} min_read_recency_for_promote 2
ceph osd pool set {cachepool} min_write_recency_for_promote 2
Note
The longer the period and the higher the
min_read_recency_for_promote和min_write_recency_for_promote``values, the more RAM the ``ceph-osd
daemon consumes. In particular, when the agent is active to flush
or evict cache objects, all hit_set_count HitSets are loaded
into RAM.
缓存大小
缓存分层代理执行两个主要功能:
刷新:代理识别已修改(或脏)的对象,并将它们转发到存储池进行长期存储。 The agent identifies modified (or dirty) objects and forwards them to the storage pool for long-term storage.
驱逐:代理识别未修改(或干净)的对象,并从缓存中驱逐最不常用的对象。 The agent identifies objects that haven’t been modified (or clean) and evicts the least recently used among them from the cache.
绝对大小
缓存分层代理可以根据字节数或对象的总数来刷新或驱逐对象。要指定最大字节数,执行以下操作:
ceph osd pool set {cachepool} target_max_bytes {#bytes}
例如,要在 1 TB 时刷新或驱逐,执行以下操作:
ceph osd pool set hot-storage target_max_bytes 1099511627776
要指定最大对象数,执行以下操作:
ceph osd pool set {cachepool} target_max_objects {#objects}
例如,要在 1M 对象时刷新或驱逐,执行以下操作:
ceph osd pool set hot-storage target_max_objects 1000000
Note
Ceph 无法自动确定缓存池的大小,因此需要在此处配置绝对大小,否则刷新/驱逐将不起作用。如果您指定了两个限制,缓存分层代理将在触发任一阈值时开始刷新或驱逐。35b7b9: 只有当 f910ff 达到 5bc030 时,所有客户端请求才会被阻塞。
Note
All client requests will be blocked only when target_max_bytes或target_max_objects reached
Relative Sizing
相对大小target_max_bytes / target_max_objects in
绝对大小:缓存分层代理可以根据缓存池的大小(由 07958f 指定)相对地刷新或驱逐对象。当缓存池包含一定百分比的已修改(或脏)对象时,缓存分层代理将它们刷新到存储池。要设置 705a4b,例如,将值设置为 7960e0 将在它们达到缓存池容量的 40% 时开始刷新已修改(脏)对象:). When the cache pool consists of a certain percentage of
modified (or dirty) objects, the cache tiering agent will flush them to the
storage pool. To set the cache_target_dirty_ratio,执行以下命令:
ceph osd pool set {cachepool} cache_target_dirty_ratio {0.0..1.0}
For example, setting the value to 0.4 will begin flushing modified
(dirty) objects when they reach 40% of the cache pool’s capacity:
ceph osd pool set hot-storage cache_target_dirty_ratio 0.4
当脏对象达到其容量的某个百分比时,以更高的速度刷新脏对象。要设置 705a4b,例如,将值设置为 99e217 将在它们达到缓存池容量的 60% 时开始积极刷新脏对象。显然,最好在 dirty_ratio 和 full_ratio 之间设置值:cache_target_dirty_high_ratio:
ceph osd pool set {cachepool} cache_target_dirty_high_ratio {0.0..1.0}
For example, setting the value to 0.6 will begin aggressively flush dirty
objects when they reach 60% of the cache pool’s capacity. obviously, we’d
better set the value between dirty_ratio and full_ratio:
ceph osd pool set hot-storage cache_target_dirty_high_ratio 0.6
当缓存池达到其容量的某个百分比时,缓存分层代理将驱逐对象以保持空闲容量。要设置 705a4b,例如,将值设置为 a3ced6 将在它们达到缓存池容量的 80% 时开始刷新未修改(干净)对象:cache_target_full_ratio,执行以下命令:
ceph osd pool set {cachepool} cache_target_full_ratio {0.0..1.0}
For example, setting the value to 0.8 will begin flushing unmodified
(clean) objects when they reach 80% of the cache pool’s capacity:
ceph osd pool set hot-storage cache_target_full_ratio 0.8
缓存年龄
您可以指定对象在缓存分层代理刷新最近修改(或脏)对象到后端存储池之前的最低年龄:
ceph osd pool set {cachepool} cache_min_flush_age {#seconds}
例如,要在 10 分钟后刷新已修改(或脏)对象,执行以下操作:
ceph osd pool set hot-storage cache_min_flush_age 600
您可以指定对象在从缓存层驱逐之前的最低年龄:
ceph osd pool {cache-tier} cache_min_evict_age {#seconds}
例如,要在 30 分钟后驱逐对象,执行以下操作:
ceph osd pool set hot-storage cache_min_evict_age 1800
移除缓存层
移除缓存层的具体步骤取决于它是回写缓存还是只读缓存。
移除只读缓存
由于只读缓存没有修改数据,您可以在不丢失缓存中对象最近更改的情况下禁用和移除它。
将缓存模式更改为 2e7710 以禁用它:
noneto disable it.:ceph osd tier cache-mode {cachepool} none例如:
ceph osd tier cache-mode hot-storage none从后端池中移除缓存池:
ceph osd tier remove {storagepool} {cachepool}例如:
ceph osd tier remove cold-storage hot-storage
移除写入回写缓存
由于写入回写缓存可能包含已修改的数据,在禁用和移除它之前,您必须采取措施确保不会丢失缓存中对象的任何最近更改。
将缓存模式更改为 5e53d4,以便新对象和已修改对象将刷新到后端存储池:
proxyso that new and modified objects will flush to the backing storage pool.:ceph osd tier cache-mode {cachepool} proxy例如:
ceph osd tier cache-mode hot-storage proxy确保缓存池已刷新。这可能需要几分钟:
rados -p {cachepool} ls如果缓存池仍然有对象,您可以手动刷新它们。例如:
rados -p {cachepool} cache-flush-evict-all移除覆盖,以便客户端不会将流量指向缓存:
ceph osd tier remove-overlay {storagetier}例如:
ceph osd tier remove-overlay cold-storage最后,从后端存储池中移除缓存层池:
ceph osd tier remove {storagepool} {cachepool}例如:
ceph osd tier remove cold-storage hot-storage
排错未找到的对象
在某些情况下,重新启动 OSD 可能会导致未找到的对象。
以下是在从 Ceph 14.2.6 升级到 Ceph 14.2.7 的过程中出现未找到对象的示例:
2/543658058 objects unfound (0.000%)
pg 19.12 has 1 unfound objects
pg 19.2d has 1 unfound objects
Possible data damage: 2 pgs recovery_unfound
pg 19.12 is active+recovery_unfound+undersized+degraded+remapped, acting [299,310], 1 unfound
pg 19.2d is active+recovery_unfound+undersized+degraded+remapped, acting [290,309], 1 unfound
# ceph pg 19.12 list_unfound
{
"num_missing": 1,
"num_unfound": 1,
"objects": [
{
"oid": {
"oid": "hit_set_19.12_archive_2020-02-25 13:43:50.256316Z_2020-02-25 13:43:50.325825Z",
"key": "",
"snapid": -2,
"hash": 18,
"max": 0,
"pool": 19,
"namespace": ".ceph-internal"
},
"need": "3312398'55868341",
"have": "0'0",
"flags": "none",
"locations": []
}
],
"more": false
现场的一些测试表明,未找到的对象可以被删除而不会产生任何不良影响(请参阅 d4bb89:跟踪问题 #44286,注释 3 c4eb50)。Pawel Stefanski 建议只要对象是 a5ad56 的一部分,删除丢失或未找到的对象就是安全的。Tracker Issue #44286, Note 3). Pawel Stefanski suggests
that deleting missing or unfound objects is safe as long as the objects are a
part of .ceph-internal::hit_set_PGID_archive.
Various members of the upstream Ceph community have reported in 跟踪问题 #44286上游 Ceph 社区的一些成员在 42d21f:跟踪问题 #44286 中报告说,以下版本的 Ceph 受到此问题的影响:
14.2.8
14.2.16
15.2.15
16.2.5
17.2.7
请参阅跟踪问题 #44286跟踪问题 #44286 的历史记录。
由 Ceph 基金会带给您
Ceph 文档是一个社区资源,由非盈利的 Ceph 基金会资助和托管Ceph Foundation. 如果您想支持这一点和我们的其他工作,请考虑加入现在加入.