注意
本文档适用于 Ceph 开发版本。
监控 OSDs 和 PGs
高可用性和高可靠性需要一个容错的方法来管理硬件和软件问题。Ceph 没有单点故障,即使在“降级”模式下它也能服务数据请求。Ceph 的 b38f9c: 数据data placement引入了一层间接层,以确保数据不会直接绑定到特定的 OSD。因此,跟踪系统故障需要找到放置组(PG) 以及问题的根本原因下的底层 OSD。
提示
集群的一部分出现故障可能会阻止您访问特定对象,但这并不意味着您无法访问其他对象。当您遇到故障时,不要惊慌。只需按照监控您的 OSD 和放置组的步骤进行操作,然后开始故障排除。
Ceph 是自修复的。但是,当问题仍然存在时,监控 OSD 和放置组将帮助您识别问题。
监控 OSDs
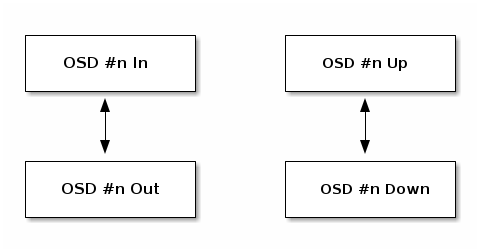
OSD 要么in服务 (in) 或无法服务 ( of service (out)。OSD 要么正在运行且可访问 (up),要么未运行且不可访问 (down).
如果 OSD 是up,它可能是in服务(客户端可以读写数据)或它out无法服务。如果 OSD 最初是in但由于故障或手动操作被设置为out状态,Ceph 将将放置组迁移到其他 OSD 以维护配置的冗余性。
如果 OSD 是out无法服务,CRUSH 不会将其分配放置组。如果 OSD 是down,它也将out.
Note
如果 OSD 是down和in,则存在问题,这表明集群不处于健康状态。
如果您运行命令ceph health, ceph -s或ceph -w,您可能会注意到集群并不总是显示HEALTH OK。不要惊慌。在某些情况下,集群不好的主意。showHEALTH OK:
是预期和正常的。您还没有启动集群。
您刚刚启动或重新启动了集群,它还没有准备好显示健康状态,因为 PG 正在创建中,OSD 正在互操作。
您刚刚添加或删除了 OSD。
您刚刚修改了您的集群映射。
检查 OSD 是否up并运行是监控它们的一个重要方面:每当集群启动并运行时,集群中每个 OSD 也应该in the cluster should also
be up并运行。要查看集群的所有 OSD 是否都在运行,请运行以下命令:
ceph osd stat
输出提供以下信息:OSD 的总数(x),有多少 OSD 是up(y),有多少 OSD 是in(z),以及映射时代(eNNNN)。
x osds: y up, z in; epoch: eNNNN
如果集群中in的 OSD 数量大于up,请运行以下命令以识别ceph-osd
daemons that are not running:
ceph osd tree
#ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 2.00000 pool openstack
-3 2.00000 rack dell-2950-rack-A
-2 2.00000 host dell-2950-A1
0 ssd 1.00000 osd.0 up 1.00000 1.00000
1 ssd 1.00000 osd.1 down 1.00000 1.00000
提示
搜索精心设计的 CRUSH 层次结构以识别特定 OSD 的物理位置可能有助于您解决集群问题。
如果 OSD 是down,请运行以下命令启动它:
sudo systemctl start ceph-osd@1
对于已停止或无法重新启动的 OSD 相关的问题,请参阅OSD未运行.
PG 集合
当 CRUSH 将 PG 分配给 OSD 时,它会注意池所需的 PG 副本数量,然后将每个副本分配给不同的 OSD。例如,如果池需要 PG 的三个副本,CRUSH 可能会osd.1, osd.2和osd.3分别分配给CRUSH 映射中设置的故障域的伪随机放置;因此,在大集群中,PG 很少被分配给立即相邻的 OSD。
Ceph 使用 OSD 的行动集处理客户端请求:这是当前拥有 PG 片段完整且工作版本的 OSD 集合,因此负责处理请求。相比之下,上集是包含特定 PG 片段的 OSD 集合。数据被移动或复制到上集,或计划被移动或复制,到上集。有关网络配置的详细信息,请参阅放置组概念.
有时 Acting Set 中的 OSD 是down或以其他方式无法服务 PG 中的对象请求。当出现这种情况时,不要惊慌。此类情况的常见示例包括:
您添加或删除了 OSD,CRUSH 将 PG 重新分配给
一个 OSD 是
down,已重新启动,现在recovering.Acting Set 中的 OSD 是
down或无法服务请求,另一个 OSD 暂时承担了它的职责。
通常,Up Set 和 Acting Set 是相同的。当它们不同时,这可能表示 Ceph 正在迁移 PG(换句话说,PG 已重新映射),一个 OSD 正在恢复,或者集群存在问题(在这种情况下,Ceph 通常显示“HEALTH WARN”状态和“stuck stale”消息)。
要检索 PG 列表,请运行以下命令:
ceph pg dump
要查看特定 PG 的 Acting Set 和 Up Set 中的 OSD,请运行以下命令:
ceph pg map {pg-num}
输出提供以下信息:osdmap 时代(eNNN)、PG 编号
osdmap eNNN pg {raw-pg-num} ({pg-num}) -> up [0,1,2] acting [0,1,2]
Note
如果 Up Set 和 Acting Set 不匹配,这可能表示集群正在自我平衡或集群存在问题。
对等
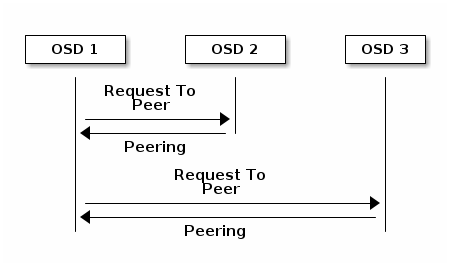
在您可以将数据写入 PG 之前,它必须处于active状态,并且最好处于clean状态。为了使 Ceph 确定 PG 的当前状态,必须进行对等。也就是说,PG 的主 OSD(Acting Set 中的第一个 OSD)必须与次要和后续 OSD 对等,以便就 PG 的当前状态达成共识。在以下图中,我们假设一个具有 PG 三个副本的池:
监控 PG 状态
如果您运行命令ceph health, ceph -s或ceph -w,您可能会注意到集群并不总是显示HEALTH OK。在检查 OSD 是否正在运行后,您还应该检查 PG 状态。在某些 PG 对等相关的情不好的主意。showHEALTH OK:
You have just created a pool and the PGs haven’t peered yet.
The PGs are recovering.
You have just added an OSD to or removed an OSD from the cluster.
You have just modified your CRUSH map and your PGs are migrating.
There is inconsistent data in different replicas of a PG.
Ceph is scrubbing a PG’s replicas.
Ceph doesn’t have enough storage capacity to complete backfilling operations.
If one of these circumstances causes Ceph to show HEALTH WARN, don’t
panic. In many cases, the cluster will recover on its own. In some cases, however, you
might need to take action. An important aspect of monitoring PGs is to check their
status as active和clean: that is, it is important to ensure that, when the
cluster is up and running, all PGs are active and (preferably) clean.
To see the status of every PG, run the following command:
ceph pg stat
The output provides the following information: the total number of PGs (x), how many
PGs are in a particular state such as active+clean (y), and the
amount of data stored (z).
x pgs: y active+clean; z bytes data, aa MB used, bb GB / cc GB avail
Note
It is common for Ceph to report multiple states for PGs (for example,
active+clean, active+clean+remapped, active+clean+scrubbing.
Here Ceph shows not only the PG states, but also storage capacity used (aa), the amount of storage capacity remaining (bb), and the total storage capacity of the PG. These values can be important in a few cases:
The cluster is reaching its
near full ratio或full ratio.Data is not being distributed across the cluster due to an error in the CRUSH configuration.
要检索 PG 列表,请运行以下命令:
ceph pg dump
To format the output in JSON format and save it to a file, run the following command:
ceph pg dump -o {filename} --format=json
To query a specific PG, run the following command:
ceph pg {poolnum}.{pg-id} query
Ceph will output the query in JSON format.
The following subsections describe the most common PG states in detail.
Creating
PGs are created when you create a pool: the command that creates a pool
specifies the total number of PGs for that pool, and when the pool is created
all of those PGs are created as well. Ceph will echo creating while it is
creating PGs. After the PG(s) are created, the OSDs that are part of a PG’s
Acting Set will peer. Once peering is complete, the PG status should be
active+clean. This status means that Ceph clients begin writing to the
PG.

对等
When a PG peers, the OSDs that store the replicas of its data converge on an agreed state of the data and metadata within that PG. When peering is complete, those OSDs agree about the state of that PG. However, completion of the peering process does 不好的主意。 mean that each replica has the latest contents.
Active
After Ceph has completed the peering process, a PG should become active。上集active state means that the data in the PG is generally available for
read and write operations in the primary and replica OSDs.
Clean
When a PG is in the clean state, all OSDs holding its data and metadata
have successfully peered and there are no stray replicas. Ceph has replicated
all objects in the PG the correct number of times.
Degraded
When a client writes an object to the primary OSD, the primary OSD is
responsible for writing the replicas to the replica OSDs. After the primary OSD
writes the object to storage, the PG will remain in a degraded
state until the primary OSD has received an acknowledgement from the replica
OSDs that Ceph created the replica objects successfully.
The reason that a PG can be active+degraded is that an OSD can be
active even if it doesn’t yet hold all of the PG’s objects. If an OSD goes
down, Ceph marks each PG assigned to the OSD as degraded. The PGs must
peer again when the OSD comes back online. However, a client can still write a
new object to a degraded PG if it is active.
如果 OSD 是down和degraded condition persists, Ceph might mark the
down OSD as out of the cluster and remap the data from the down OSD
to another OSD. The time between being marked down and being marked out
is determined by mon_osd_down_out_interval, which is set to 600 seconds
by default.
A PG can also be in the degraded state because there are one or more
objects that Ceph expects to find in the PG but that Ceph cannot find. Although
you cannot read or write to unfound objects, you can still access all of the other
objects in the degraded PG.
Recovering
Ceph was designed for fault-tolerance, because hardware and other server
problems are expected or even routine. When an OSD goes down, its contents
might fall behind the current state of other replicas in the PGs. When the OSD
has returned to the up state, the contents of the PGs must be updated to
reflect that current state. During that time period, the OSD might be in a
recovering状态。
Recovery is not always trivial, because a hardware failure might cause a cascading failure of multiple OSDs. For example, a network switch for a rack or cabinet might fail, which can cause the OSDs of a number of host machines to fall behind the current state of the cluster. In such a scenario, general recovery is possible only if each of the OSDs recovers after the fault has been resolved.]
Ceph provides a number of settings that determine how the cluster balances the
resource contention between the need to process new service requests and the
need to recover data objects and restore the PGs to the current state. The
osd_recovery_delay_start setting allows an OSD to restart, re-peer, and
even process some replay requests before starting the recovery process. The
osd_recovery_thread_timeout setting determines the duration of a thread
timeout, because multiple OSDs might fail, restart, and re-peer at staggered
rates. The osd_recovery_max_active setting limits the number of recovery
requests an OSD can entertain simultaneously, in order to prevent the OSD from
failing to serve. The osd_recovery_max_chunk setting limits the size of
the recovered data chunks, in order to prevent network congestion.
Back Filling
When a new OSD joins the cluster, CRUSH will reassign PGs from OSDs that are already in the cluster to the newly added OSD. It can put excessive load on the new OSD to force it to immediately accept the reassigned PGs. Back filling the OSD with the PGs allows this process to begin in the background. After the backfill operations have completed, the new OSD will begin serving requests as soon as it is ready.
During the backfill operations, you might see one of several states:
backfill_wait indicates that a backfill operation is pending, but is not
yet underway; backfilling indicates that a backfill operation is currently
underway; and backfill_toofull indicates that a backfill operation was
requested but couldn’t be completed due to insufficient storage capacity. When
a PG cannot be backfilled, it might be considered incomplete.
The backfill_toofull state might be transient. It might happen that, as PGs
are moved around, space becomes available. The backfill_toofull state is
similar to backfill_wait in that backfill operations can proceed as soon as
conditions change.
Ceph provides a number of settings to manage the load spike associated with the
reassignment of PGs to an OSD (especially a new OSD). The osd_max_backfills
setting specifies the maximum number of concurrent backfills to and from an OSD
(default: 1; note you cannot change this if the mClock scheduler is active,
unless you set osd_mclock_override_recovery_settings = true, see
mClock backfill).
The backfill_full_ratio setting allows an OSD to refuse a
backfill request if the OSD is approaching its full ratio (default: 90%). This
setting can be changed with the ceph osd set-backfillfull-ratio command. If
an OSD refuses a backfill request, the osd_backfill_retry_interval setting
allows an OSD to retry the request after a certain interval (default: 30
seconds). OSDs can also set osd_backfill_scan_min和osd_backfill_scan_max in order to manage scan intervals (default: 64 and
512, respectively).
Remapped
When the Acting Set that services a PG changes, the data migrates from the old Acting Set to the new Acting Set. Because it might take time for the new primary OSD to begin servicing requests, the old primary OSD might be required to continue servicing requests until the PG data migration is complete. After data migration has completed, the mapping uses the primary OSD of the new Acting Set.
Stale
Although Ceph uses heartbeats in order to ensure that hosts and daemons are
running, the ceph-osd daemons might enter a stuck state where they are
not reporting statistics in a timely manner (for example, there might be a
temporary network fault). By default, OSD daemons report their PG, up through,
boot, and failure statistics every half second (that is, in accordance with a
value of 0.5), which is more frequent than the reports defined by the
heartbeat thresholds. If the primary OSD of a PG’s Acting Set fails to report
to the monitor or if other OSDs have reported the primary OSD down, the
monitors will mark the PG stale.
When you start your cluster, it is common to see the stale state until the
peering process completes. After your cluster has been running for a while,
however, seeing PGs in the stale state indicates that the primary OSD for
those PGs is down or not reporting PG statistics to the monitor.
识别有问题的 PG
As previously noted, a PG is not necessarily having problems just because its
state is not active+clean. When PGs are stuck, this might indicate that
Ceph cannot perform self-repairs. The stuck states include:
Unclean: PGs contain objects that have not been replicated the desired number of times. Under normal conditions, it can be assumed that these PGs are recovering.
Inactive: PGs cannot process reads or writes because they are waiting for an OSD that has the most up-to-date data to come back
up.Stale: PG are in an unknown state, because the OSDs that host them have not reported to the monitor cluster for a certain period of time (determined by
mon_osd_report_timeout).
To identify stuck PGs, run the following command:
ceph pg dump_stuck [unclean|inactive|stale|undersized|degraded]
For more detail, see Placement Group Subsystem. To troubleshoot stuck PGs, see Troubleshooting PG Errors.
查找对象位置
To store object data in the Ceph Object Store, a Ceph client must:
Set an object name
Specify a pool
The Ceph client retrieves the latest cluster map, the CRUSH algorithm calculates how to map the object to a PG, and then the algorithm calculates how to dynamically assign the PG to an OSD. To find the object location given only the object name and the pool name, run a command of the following form:
ceph osd map {poolname} {object-name} [namespace]
As the cluster evolves, the object location may change dynamically. One benefit of Ceph’s dynamic rebalancing is that Ceph spares you the burden of manually performing the migration. For details, see the 架构部分。
由 Ceph 基金会带给您
Ceph 文档是一个社区资源,由非盈利的 Ceph 基金会资助和托管Ceph Foundation. 如果您想支持这一点和我们的其他工作,请考虑加入现在加入.