注意
本文档适用于 Ceph 开发版本。
手动编辑 CRUSH 地图
Note
手动编辑 CRUSH 映射是一个高级管理员操作。对于大多数安装,CRUSH 变更可以通过 Ceph CLI 实现,而无需手动编辑 CRUSH 映射。如果您已经确定在最近的 Ceph 发布中存在需要手动编辑的情况,请考虑联系 Ceph 开发人员,以便未来的 Ceph 版本不再存在此问题。都是在与dev@ceph.io联系 Ceph 开发人员,以便未来的 Ceph 版本不再存在此问题。
要编辑现有的 CRUSH 映射,请执行以下步骤:
要了解如何为特定池设置 CRUSH 映射规则,请参阅设置池值.
获取 CRUSH 映射
要获取集群的 CRUSH 映射,请运行以下格式的命令:
ceph osd getcrushmap -o {compiled-crushmap-filename}
Ceph 输出(-o)到您指定的文件名。由于 CRUSH 映射是编译格式,因此您必须首先反编译它才能编辑它。
反编译 CRUSH 映射
要反编译 CRUSH 映射,请运行以下格式的命令:
crushtool -d {compiled-crushmap-filename} -o {decompiled-crushmap-filename}
重新编译 CRUSH 映射
要编译 CRUSH 映射,请运行以下格式的命令:
crushtool -c {decompiled-crushmap-filename} -o {compiled-crushmap-filename}
设置 CRUSH 映射
要为您的集群设置 CRUSH 映射,请运行以下格式的命令:
ceph osd setcrushmap -i {compiled-crushmap-filename}
Ceph 从您指定的文件名加载(-i)编译的 CRUSH 映射。
部分
CRUSH 映射有六个主要部分:
可调参数:映射顶部的序言描述了任何可调参数,这些参数不是遗留 CRUSH 行为的一部分。这些可调参数纠正了旧的错误、优化或其他多年来为改进 CRUSH 行为而做出的更改。设备:
devices:设备是存储数据的单个 OSD。
类型: 桶
types定义了 CRUSH 层次结构中使用的桶类型。桶:桶由存储位置的分层聚合(例如,行、机架、机架、主机)及其分配的权重组成。定义桶后,CRUSH 映射定义了层次结构中的每个节点,其类型以及它包含的设备或其他节点。
typeshave been defined, the CRUSH map defines each node in the hierarchy, its type, and which devices or other nodes it contains.规则:规则定义了数据如何在层次结构中的设备之间分布的策略。
选择参数:
choose_args是与层次结构相关联的替代权重,已根据优化数据放置进行调整。单个choose_args映射可用于整个集群,或者可以创建多个choose_args映射,每个映射都为特定池量身定制。
CRUSH 映射设备
设备是存储数据的单个 OSD。在此部分中,集群中的每个 OSD 守护进程通常定义一个设备。设备由一个id(非负整数)和一个name(通常osd.N,其中N是设备id).
标识。设备还可以具有一个device class与之相关联:例如,hdd或ssd。设备类使设备能够被 CRUSH 规则针对。这意味着设备类允许 CRUSH 规则仅选择符合某些特征的 OSD。例如,您可能希望只有 SSD 关联的 RBD 池,以及只有 HDD 关联的另一个 RBD 池。
要查看设备列表,请运行以下命令:
ceph device ls
此命令的输出形式如下:
device {num} {osd.name} [class {class}]
例如:
ceph device ls
device 0 osd.0 class ssd
device 1 osd.1 class hdd
device 2 osd.2
device 3 osd.3
在大多数情况下,每个设备都映射到相应的ceph-osd守护进程。该守护进程可能映射到一个单独的存储设备、一对设备(例如,一个用于数据,一个用于日志或元数据),或在某些情况下一个小型 RAID 设备或较大存储设备的一部分。
CRUSH 映射桶类型
CRUSH 映射中的第二个列表定义了“桶”类型。桶促进了节点和叶子的层次结构。节点桶(也称为非叶子桶)通常表示层次结构中的物理位置。节点聚合其他节点或叶子。叶子桶表示ceph-osd守护进程及其相应的存储介质。
提示
在 CRUSH 的上下文中,“桶”一词用于指代层次结构中的节点(即位置或物理硬件)。然而,在 RADOS 网关 API 的上下文中, however,“桶”一词具有不同的含义。
要向 CRUSH 映射添加桶类型,请在桶类型列表下创建新行。输入type,后跟唯一的数字 ID 和桶名称。按惯例,正好有一个叶子桶类型,它是type 0;但是,您可以给叶子桶任何您喜欢的名称(例如:osd,
disk, drive, storage):
# types
type {num} {bucket-name}
例如:
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 zone
type 10 region
type 11 root
CRUSH 映射桶层次结构
CRUSH 算法根据每个设备的权重值将数据对象分布在存储设备上,近似于均匀概率分布。CRUSH 根据您定义的分层集群映射分布对象及其副本。CRUSH 映射表示可用的存储设备和包含它们的逻辑元素。
要将放置组(PG)映射到跨故障域的 OSD,CRUSH 映射在生成的 CRUSH 映射下定义了桶类型的分层列表。创建桶层次结构的目的是将叶子节点根据其故障域(例如:主机、机架、机架、电源分配单元、机架、行、房间和数据中心)分开。除了表示 OSD 的叶子节点外,层次结构是任意的,您可以根据自己的需求定义它。#types in the generated
CRUSH map. The purpose of creating a bucket hierarchy is to segregate the leaf
nodes according to their failure domains (for example: hosts, chassis, racks,
power distribution units, pods, rows, rooms, and data centers). With the
exception of the leaf nodes that represent OSDs, the hierarchy is arbitrary and
you may define it according to your own needs.
我们建议根据您首选的硬件命名约定调整 CRUSH 映射,并使用清楚地反映物理硬件的桶名称。清晰的命名实践可以使管理集群更容易,并且在 OSD 故障(或其他硬件故障)时需要访问物理硬件时更容易排除故障。
在以下示例中,CRUSH 层次结构有osd叶子桶,并且在host级别有两个节点级桶,它们反过来又是rack桶的子级:
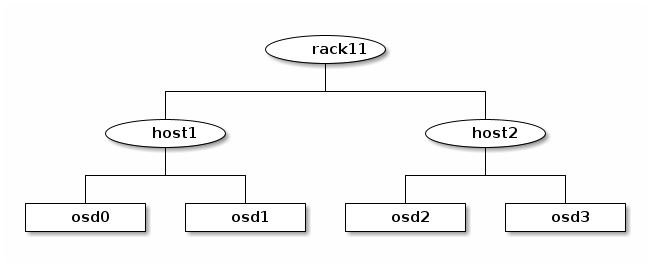
Note
较高级别的类型编号rack桶聚合较低类型编号host桶,这些桶反过来又聚合基本类型 0osd桶的中间权重值。
因为叶子节点反映了在 CRUSH 映射开头#devices列表中已声明的存储设备,因此无需将它们声明为桶实例。您层次结构中第二低的桶类型通常用于聚合设备:通常是down状态并且因此不可用。重要的是避免在单个此类机架内放置多个副本或数据分片,在这种情况下,机架是一个failure domain.
要声明桶实例,请执行以下操作:指定其类型,给它一个唯一的名称(一个字母数字字符串),分配一个用负整数表示的唯一 ID(这是可选的),分配相对于桶中物品的总容量和能力的权重,分配桶算法(通常straw2),并指定桶算法的哈希(通常0,一个反映哈希算法rjenkins1的设置)。桶可以有一个或多个项目。项目可以由节点桶或叶子组成。项目可以有一个权重,反映项目的相对权重。
要声明节点桶,请使用以下语法:
[bucket-type] [bucket-name] {
id [a unique negative numeric ID]
weight [the relative capacity/capability of the item(s)]
alg [the bucket type: uniform | list | tree | straw | straw2 ]
hash [the hash type: 0 by default]
item [item-name] weight [weight]
}
例如,在上述图中,定义了两个主机桶(在以下声明中称为node1和node2)和一个机架桶(在以下声明中称为rack1)。OSD 声明为主机桶内的项目:
host node1 {
id -1
alg straw2
hash 0
item osd.0 weight 1.00
item osd.1 weight 1.00
}
host node2 {
id -2
alg straw2
hash 0
item osd.2 weight 1.00
item osd.3 weight 1.00
}
rack rack1 {
id -3
alg straw2
hash 0
item node1 weight 2.00
item node2 weight 2.00
}
Note
在此示例中,机架桶不包含任何 OSD。相反,它包含较低级别的主机桶,并包括它们权重的总和在项目条目中。
CRUSH 映射规则
CRUSH 映射具有包括池数据放置的规则:这些规则称为“CRUSH 规则”。默认 CRUSH 映射为每个池有一个规则。如果您正在运行大型集群,您可能会创建许多池,并且每个池都可能有自己的非默认 CRUSH 规则。
Note
在大多数情况下,无需修改默认规则。当创建新池时,默认情况下规则将设置为值0(该值表示默认 CRUSH 规则,其数字 ID0).
CRUSH 规则定义了控制数据如何在层次结构中的设备之间分布的策略。规则定义了放置以及复制策略或分配策略,允许您指定 CRUSH 如何放置数据副本。例如,您可能会创建一个规则选择两个目标进行双向镜像,另一个规则选择两个不同数据中心中的三个目标进行三向复制,还有一个规则在六个存储设备上进行纠删编码。有关 CRUSH 规则的详细讨论,请参阅第 3.2的CRUSH - Controlled, Scalable, Decentralized Placement of Replicated Data.
一个正常的 CRUSH 规则的形式如下:
rule <rulename> {
id [a unique integer ID]
type [replicated|erasure]
step take <bucket-name> [class <device-class>]
step [choose|chooseleaf] [firstn|indep] <N> type <bucket-type>
step emit
}
CRUSH MSR(多步重试)规则是 CRUSH 规则的一种特殊类型,它支持重试步骤并提供更好的支持,以配置需要在每个故障域内具有多个 OSD 的配置。MSR 规则的形式如下:
rule <rulename> {
id [a unique integer ID]
type [msr_indep|msr_firstn]
step take <bucket-name> [class <device-class>]
step choosemsr <N> type <bucket-type>
step emit
}
id- 描述:
一个唯一整数,用于标识规则。
- 目的:
规则掩码的组成部分。
- 类型:
整数
- 必需:
是
- 设备空间利用率达到此阈值百分比之前,将 OSD 视为:
0
type- 描述:
表示规则强制执行的复制策略类型。 msr_firstn 和 msr_indep 是一种独特的下降算法,它支持在规则内重试步骤,因此每个故障域都有多个 OSD。
- 目的:
规则掩码的组成部分。
- 类型:
字符串
- 必需:
是
- 设备空间利用率达到此阈值百分比之前,将 OSD 视为:
replicated- 有效值:
replicated,erasure,msr_firstn,msr_indep
step take <bucket-name> [class <device-class>]- 描述:
接收一个桶名称并向下遍历树。如果
device-class参数指定,则参数必须匹配集群内分配给 OSD 的类。仅包含属于该类的设备。- 目的:
规则的组成部分。
- 必需:
是
- 示例:
step take data
step choose firstn {num} type {bucket-type}- 描述:
从当前桶中选择给定类型的桶。
numbuckets of the given type from within the current bucket.{num}通常是池中的副本数量(换句话说,池大小)。如果
{num} == 0,选择pool-num-replicas桶(尽可能多的桶)。如果
pool-num-replicas > {num} > 0,选择该数量的桶。如果
{num} < 0,选择pool-num-replicas - {num}桶的中间权重值。
- 目的:
规则的组成部分。
- 先决条件:
跟随
step take或step choose.- 示例:
step choose firstn 1 type row
step chooseleaf firstn {num} type {bucket-type}- 描述:
选择给定类型的桶集,并从该桶集中的每个桶的子树中选择一个叶子节点(即 OSD)。桶集中的桶数量通常是池中的副本数量(换句话说,池大小)。
如果
{num} == 0,选择pool-num-replicas桶(尽可能多的桶)。如果
pool-num-replicas > {num} > 0,选择该数量的桶。如果
{num} < 0,选择pool-num-replicas - {num}桶的中间权重值。
- 目的:
规则的组成部分。使用
chooseleaf而无需在单独的步骤中选择设备。- 先决条件:
跟随
step take或step choose.- 示例:
step chooseleaf firstn 0 type row
step emit- 描述:
输出堆栈顶部的当前值并清空堆栈。通常在规则的末尾使用,但也可能用于从同一规则中的不同树中选择。
- 目的:
规则的组成部分。
- 先决条件:
跟随
step choose.- 示例:
step emit
重要
一个 CRUSH 规则可以分配给多个池,但一个池不能有多个 CRUSH 规则。
firstn或indep
- 描述:
确定当 CRUSH 映射中的项目(OSD)被标记为
down时 CRUSH 使用的替换策略。当此规则与复制池一起使用时,firstn使用。当此规则与纠删编码池一起使用时,indep时生成。假设一个 PG 存储在 OSD 1、2、3、4 和 5 上,然后 OSD 3 停机。
当在
firstn模式下时,CRUSH 仅调整其计算以选择 OSD 1 和 2,然后选择 3 并发现 3 已停机,重试并选择 4 和 5,最后继续选择新的 OSD:OSD 6。因此,最终的 CRUSH 映射转换是 1、2、3、4、5 → 1、2、4、5、6。但是,如果您正在存储纠删编码池,则上述序列会更改映射到 OSD 4、5 和 6 的数据。模式
indep尝试避免这种不希望的结果。当在indep模式下时,CRUSH 可以预期选择 3,发现 3 已停机,重试并选择 6。因此,最终的 CRUSH 映射转换是 1、2、3、4、5 → 1、2、6、4、5。
step choosemsr {num} type {bucket-type}- 描述:
选择一个 num 桶类型的桶。msr_firstn 和 msr_indep 必须使用 choosemsr 而不是 choose 或 chooseleaf。
如果
{num} == 0,选择pool-num-replicas桶(尽可能多的桶)。如果
pool-num-replicas > {num} > 0,选择该数量的桶。
- 目的:
msr_firstn 和 msr_indep 规则所需的 choose 步骤。
- 先决条件:
跟随
step take和step emit- 示例:
step choosemsr 3 type host
从遗留 SSD 规则迁移到设备类
之前,在 Luminous 发布引入device class功能之前,为了编写应用于特殊设备类型(例如,SSD)的规则,必须手动编辑 CRUSH 映射并维护每个设备类型的并行层次结构。设备类功能提供了一种更透明的方法来实现这一目标。
然而,如果您将集群从现有的手动自定义每个设备映射迁移到新的基于设备类的规则,系统中的所有数据都将重新排序。
The crushtool工具具有几个命令,可以将遗留规则和层次结构转换为新的设备类规则,并允许您开始使用新的设备类规则。有三种可能的转换类型:
--reclassify-root <root-name> <device-class>此命令检查层次结构下
root-name的所有内容,并重写任何引用指定根且形式为take <root-name>的规则,使其改为形式take <root-name> class <device-class>。该命令还以这种方式重新编号桶,以便旧 ID 用于指定类的“影子树”,结果不会发生数据移动。例如,假设您有以下现有规则:
rule replicated_rule { id 0 type replicated step take default step chooseleaf firstn 0 type rack step emit }
如果根
default被重新分类为类hdd,则新规则如下:rule replicated_rule { id 0 type replicated step take default class hdd step chooseleaf firstn 0 type rack step emit }
--set-subtree-class <bucket-name> <device-class>此命令将根桶名称为下树中的每个设备标记为指定的设备类。
此命令通常与
--reclassify-root选项一起使用,以确保该根中的所有设备都标记有正确的类。在某些情况下,然而,其中一些设备已正确标记为不同的类,并且不得重新标记。为了管理这种困难,可以排除--set-subtree-class选项。重映射过程可能不完美,因为以前的规则对多个类的设备有影响,但调整后的规则仅映射到指定设备类的设备。但是,当异常设备不多时,结果的数据移动程度通常在可接受的范围内。--reclassify-bucket <match-pattern> <device-class> <default-parent>此命令允许您将并行类型特定层次结构与正常层次结构合并。例如,许多用户具有类似于以下映射:
host node1 { id -2 # do not change unnecessarily # weight 109.152 alg straw2 hash 0 # rjenkins1 item osd.0 weight 9.096 item osd.1 weight 9.096 item osd.2 weight 9.096 item osd.3 weight 9.096 item osd.4 weight 9.096 item osd.5 weight 9.096 ... } host node1-ssd { id -10 # do not change unnecessarily # weight 2.000 alg straw2 hash 0 # rjenkins1 item osd.80 weight 2.000 ... } root default { id -1 # do not change unnecessarily alg straw2 hash 0 # rjenkins1 item node1 weight 110.967 ... } root ssd { id -18 # do not change unnecessarily # weight 16.000 alg straw2 hash 0 # rjenkins1 item node1-ssd weight 2.000 ... }
此命令重新分类与特定模式匹配的每个桶。模式可以是形式
%suffix或prefix%。例如,在上述示例中,我们会使用模式%-ssd。对于每个匹配的桶,名称的其余部分(对应于%通配符)指定了基桶。匹配桶中的所有设备都标记为指定的设备类,然后移动到基桶。如果基桶不存在(例如,node12-ssd存在但node12不存在),则创建它并在指定的默认父桶下链接。在每种情况下,都注意保留旧桶 ID 以防止数据移动。任何具有take步骤的规则,这些步骤引用旧桶,都会相应地调整。--reclassify-bucket <bucket-name> <device-class> <base-bucket>相同命令也可以不使用通配符来映射单个桶。例如,在之前的示例中,我们希望
ssd桶映射到default桶。转换由上述片段组成的映射的最后一个命令类似于以下内容:
ceph osd getcrushmap -o original crushtool -i original --reclassify \ --set-subtree-class default hdd \ --reclassify-root default hdd \ --reclassify-bucket %-ssd ssd default \ --reclassify-bucket ssd ssd default \ -o adjusted
--compareflag
A --compare标志可用于确保在从遗留 SSD 规则迁移到设备类执行的转换是正确的。此标志测试大量输入与 CRUSH 映射,并检查输出是否为预期结果。控制这些输入的选项与应用于--test命令的选项相同。有关此--compare命令如何应用于上述示例的说明,请参阅以下内容:
crushtool -i original --compare adjusted
rule 0 had 0/10240 mismatched mappings (0)
rule 1 had 0/10240 mismatched mappings (0)
maps appear equivalent
如果命令发现任何差异,则重映射输入的比例将报告在括号中。
当您对调整后的映射满意时,通过运行以下命令将其应用于集群:
ceph osd setcrushmap -i adjusted
手动调整 CRUSH
如果您已经验证所有客户端都在运行最新代码,您可以通过提取 CRUSH 映射、修改值并将映射重新注入集群来调整 CRUSH 可调参数。程序如下:
提取最新的 CRUSH 映射:
ceph osd getcrushmap -o /tmp/crush调整可调参数。在我们的测试中,以下值似乎对大小集群都产生了最佳行为。该程序要求您在
--enable-unsafe-tunables标志。使用此选项时要crushtool命令中指定极其小心:crushtool -i /tmp/crush --set-choose-local-tries 0 --set-choose-local-fallback-tries 0 --set-choose-total-tries 50 -o /tmp/crush.new重新注入修改后的映射:
ceph osd setcrushmap -i /tmp/crush.new
遗留值
要设置 CRUSH 可调参数的遗留值,请运行以下命令:
crushtool -i /tmp/crush --set-choose-local-tries 2 --set-choose-local-fallback-tries 5 --set-choose-total-tries 19 --set-chooseleaf-descend-once 0 --set-chooseleaf-vary-r 0 -o /tmp/crush.legacy
特殊--enable-unsafe-tunables标志是必需的。在运行旧版本的ceph-osd守护进程后恢复到遗留值时要小心,因为功能位没有完全执行。
由 Ceph 基金会带给您
Ceph 文档是一个社区资源,由非盈利的 Ceph 基金会资助和托管Ceph Foundation. 如果您想支持这一点和我们的其他工作,请考虑加入现在加入.