数据与模型版本控制
数据科学团队常常面临关于数据和机器学习模型版本管理的问题:我们如何统一跟踪数据、源代码和机器学习模型的变化?组织和存储这些文件及目录的不同变体的最佳方式是什么?
该领域另一个问题与记账有关:需要能够识别过去的数据输入和处理过程,以便理解结果、共享知识或调试。
数据版本控制(DVC)允许你将数据和模型的版本保存在 Git 提交中,同时将实际内容存储在本地或云存储中。它还提供了在不同数据内容之间切换的机制。最终,你可以获得一个涵盖数据、代码和机器学习模型的统一历史记录,可以自由追溯——这正是你工作的完整日志!
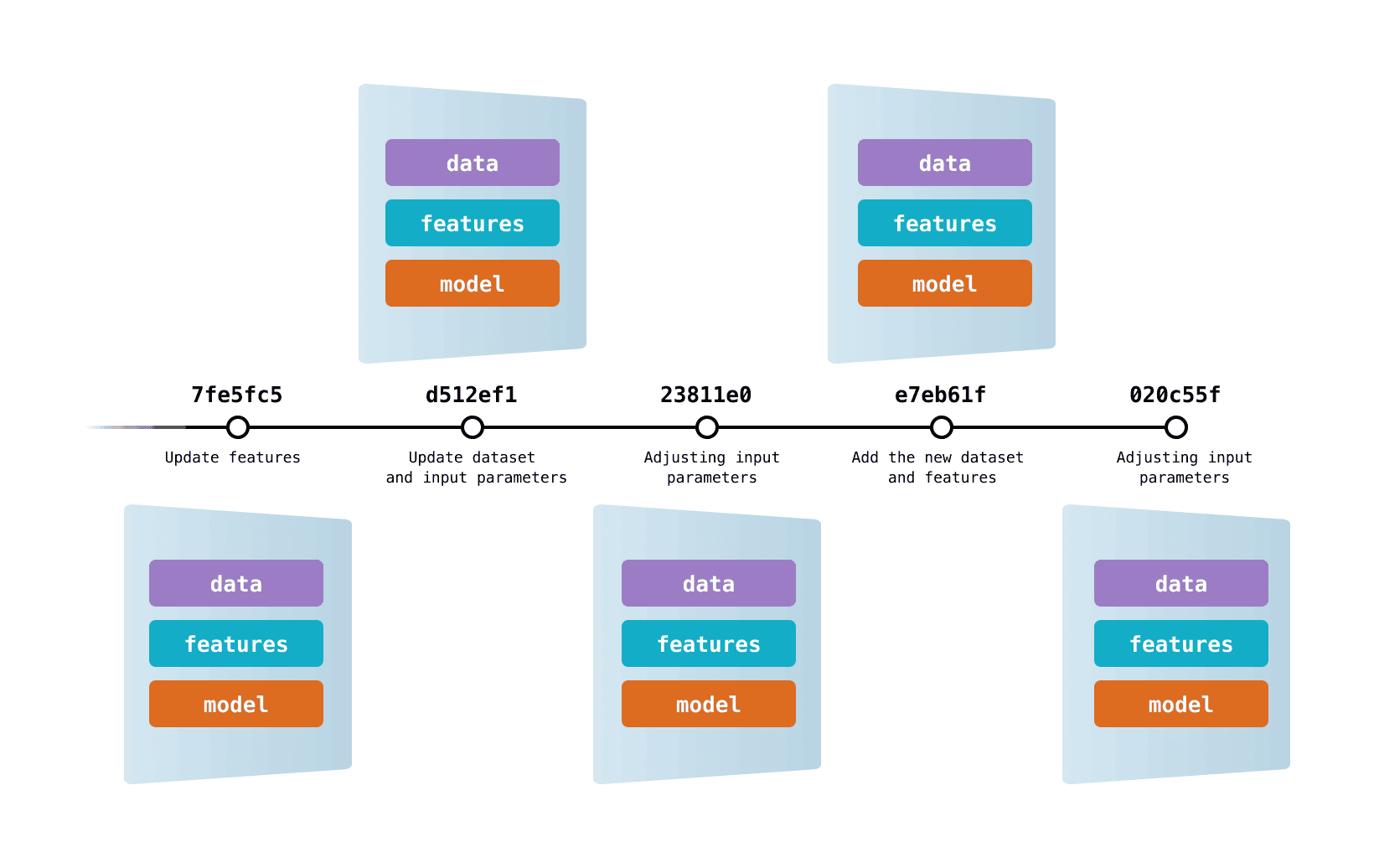
DVC 实现了通过代码化进行数据版本管理。你只需生成简单的 元文件,描述需要跟踪的数据集、机器学习产物等内容。这些元数据可存入 Git,替代大文件本身。现在,你可以使用 DVC 创建数据的 快照、恢复旧版本、复现实验、记录不断变化的 指标等!
👩💻 感兴趣吗? 尝试我们的 版本控制教程,亲身体验 DVC 的使用感受。
当你使用 DVC 时,你的数据文件和目录的独特版本会被系统化地 缓存(避免文件重复)。工作数据存储与你的 工作区 分离,以保持项目轻量化,但通过 DVC 自动管理的文件 链接 保持连接。
我们方法的优势包括:
-
一致性:使用稳定的文件名保持项目可读性——即使数据多变,文件名也不必随之更改。不再需要像
data/20190922/labels_v7_final这样复杂的路径,也无需频繁修改代码中的路径。 -
高效的数据管理:为你的数据和模型使用熟悉且成本效益高的存储方案(例如 SFTP、S3、HDFS、等等),摆脱 Git 托管的 限制。DVC 能够 优化 大文件的存储和传输。
-
协作:轻松在团队内部和远程分发项目并共享其数据,或在其他地方 重用 项目。
-
数据合规性:将数据修改请求作为 Git 拉取请求 进行审查。审计项目不可变的历史记录,了解数据集或模型何时被批准以及原因。
-
GitOps:将你的数据科学项目与 Git 生态系统连接起来。Git 工作流为你打开通往高级 CI/CD 工具(如 CML)、特定模式(如 数据注册表)以及其他最佳实践的大门。
总之,数据科学和机器学习是迭代过程,数据、模型和代码的生命周期以不同的节奏运行。DVC 帮助你有效管理并规范这些流程。