教程:数据注册表基础
构建注册表
将数据集添加到注册表可以非常简单,只需将相关数据文件或目录放入 工作区,并用 dvc add 命令进行跟踪。对于替代实际数据的 .dvc 文件(如下方的 music/songs.dvc),可遵循标准的 Git 工作流程。这使得团队能够在与源代码相同的层级上协作处理数据:
该示例数据集实际上 存在。
$ mkdir -p music/songs
$ cp ~/Downloads/millionsongsubset_full music/songs
$ dvc add music/songs/
$ git add music/songs.dvc music/.gitignore
$ git commit -m "Track 1.8 GB 10,000 song dataset in music/"实际数据存储在项目的 缓存 中,并可被 推送 到一个或多个 远程存储 位置,以便其他人或其他地点也能访问该注册表:
$ dvc remote add -d myremote s3://mybucket/dvcstore
$ dvc push💡 将 DVC 仓库 组织为数据注册表的一个好方法是使用目录对相似数据进行分组,例如
images/、natural-language/等。例如,我们的 数据集注册表 包含像get-started/和use-cases/这样的目录,对应本网站的各个部分。
使用注册表
从数据注册表中消费产物(artifacts)的主要方法是使用 dvc import 和 dvc get 命令,以及 Python API dvc.api。但首先,我们可能希望浏览其内容。
列出数据
为了在 DVC 仓库中查找所需数据,可使用 dvc list 命令(类似于 ls 或第三方工具如 aws s3 ls):
$ dvc list -R https://github.com/iterative/dataset-registry
.gitignore
README.md
get-started/.gitignore
get-started/data.xml
get-started/data.xml.dvc
images/.gitignore
images/dvc-logo-outlines.png
...Git 跟踪的文件和 DVC 跟踪的数据(或模型等)都会被列出。
数据下载
dvc get 类似于使用直接下载工具如 wget(HTTP)、aws s3 cp(S3)等。要从 DVC 仓库获取数据集,我们可以运行如下命令:
$ dvc get https://github.com/example/registry music/songs此命令会从项目的默认远程下载 music/songs 并放置在当前工作目录中。
数据导入工作流
dvc import 使用与 dvc get 相同的语法:
$ dvc import https://github.com/example/registry images/faces除了下载数据外,导入操作还会保存本地项目对数据源(注册表仓库)依赖关系的信息。这是通过生成一个特殊的导入 .dvc 文件来实现的,其中包含这些元数据。
每当注册表中的数据集发生变化时,我们可以通过 dvc update 命令更新本地数据:
$ dvc update faces.dvc该命令会根据源仓库的最新提交下载新增和修改的文件,并删除已移除的文件;同时相应地更新 .dvc 文件。
请注意,
dvc get、dvc import和dvc update都提供了一个--rev选项,用于从源仓库的特定提交中下载数据。
在 Python 代码中使用 DVC 数据
随 DVC 安装的 dvc 包中包含了我们的Python API,其中提供了 open 函数,可用于直接从外部DVC 项目加载或流式读取数据:
import dvc.api
model_path = 'model.pkl'
repo_url = 'https://github.com/example/registry'
with dvc.api.open(model_path, repo_url) as f:
model = pickle.load(f)
# ... Use the model!这会将 model.pkl 作为类文件对象打开。此示例展示了一种简单的机器学习模型部署方法,但也可扩展至更复杂的场景,例如构建模型库。
另请参阅 dvc.api.read() 和 dvc.api.get_url() 函数。
更新注册表
数据集是不断演进的,而 DVC 已为此做好准备。只需更改注册表中的数据,然后再次运行 dvc add 来应用更新:
$ cp 1000/more/songs/* music/songs/
$ dvc add music/songs/DVC 会修改相应的 .dvc 文件以反映这些变更,Git 会自动跟踪这些变化:
$ git status
...
modified: music/songs.dvc
$ git commit -am "Add 1,000 more songs to music/ dataset."对多个数据集重复这一过程,便可构建出一个稳健的注册表。最终结果本质上是一个对一组元数据文件进行版本管理的仓库。来看一个示例:
$ tree --filelimit=10
.
├── images
│ ├── .gitignore
│ ├── cats-dogs [2800 entries] # Listed in .gitignore
│ ├── faces [10000 entries] # Listed in .gitignore
│ ├── cats-dogs.dvc
│ └── faces.dvc
├── music
│ ├── .gitignore
│ ├── songs [11000 entries] # Listed in .gitignore
│ └── songs.dvc
├── text
...别忘了使用 dvc push 将数据变更推送到远程存储,以便其他人可以获取!
$ dvc push管理注册表
现在你已经了解了如何构建轻量级的数据注册表、更新它以及从中获取文件。随着注册表或团队规模的扩大,你可能会难以管理跨多个项目的全部产物。如何保持它们的组织性?如何知道该使用哪个版本?又该如何与团队以外的人员共享?DVC 结合 DVC Studio 可帮助你扩展注册表,并解决这些问题。
添加元数据
你可以记录有关产物的额外元数据,以帮助组织和便于他人发现。可在项目的 dvc.yaml 文件中添加别名及其他元数据:
# dvc.yaml
artifacts:
get-started-data:
path: get-started/data.xml.dvc
type: data
desc: 'Stack Overflow questions'
labels:
- nlp
- classification一旦你将这些信息通过 git commit 和 git push 推送到已连接 DVC Studio 的项目中,团队中的任何人都可以在模型注册表中查看、筛选或搜索所有项目的内容。尽管上述产物并非模型,但你可以调整筛选条件,将其用于任意类型的产物:
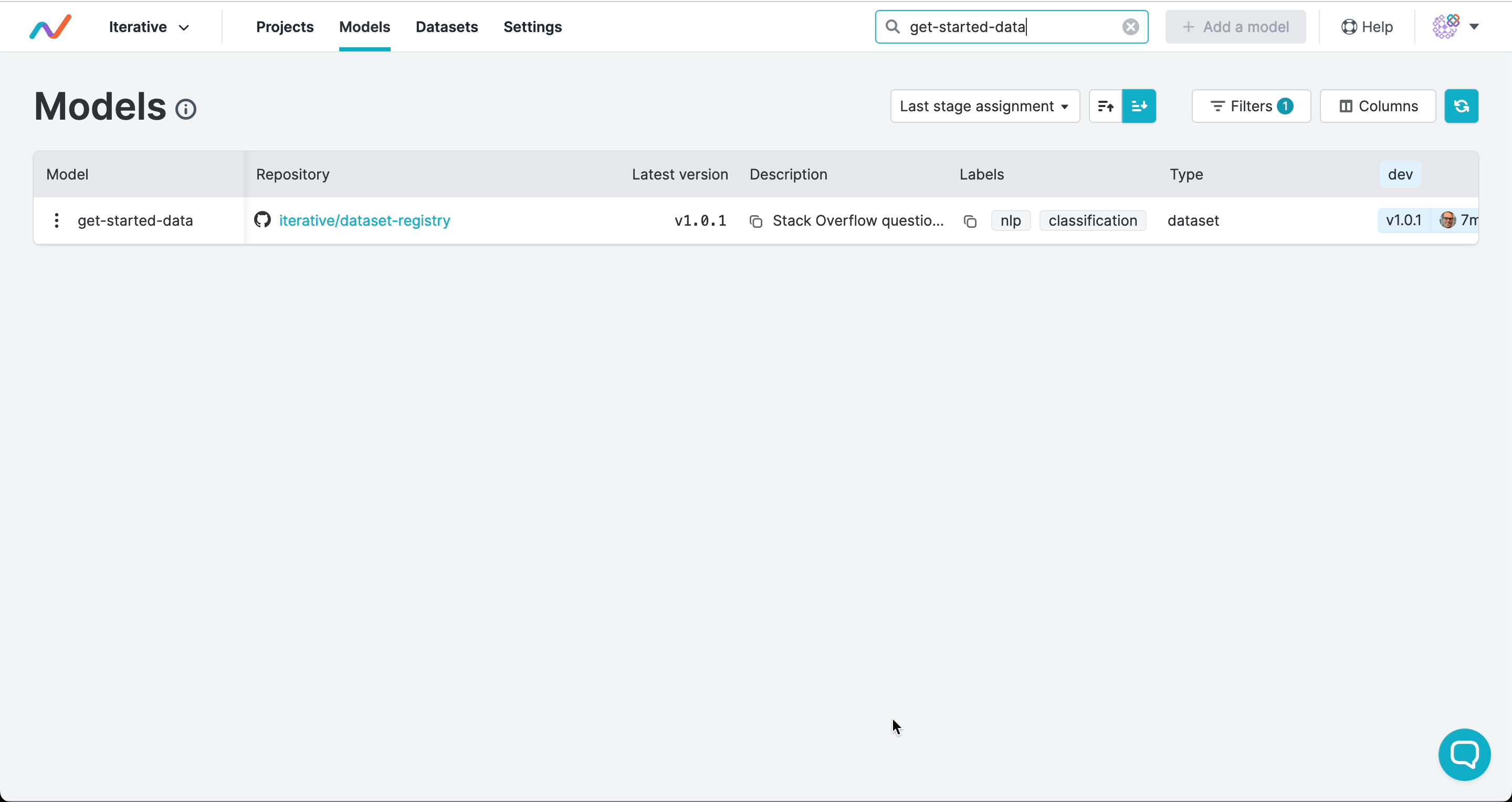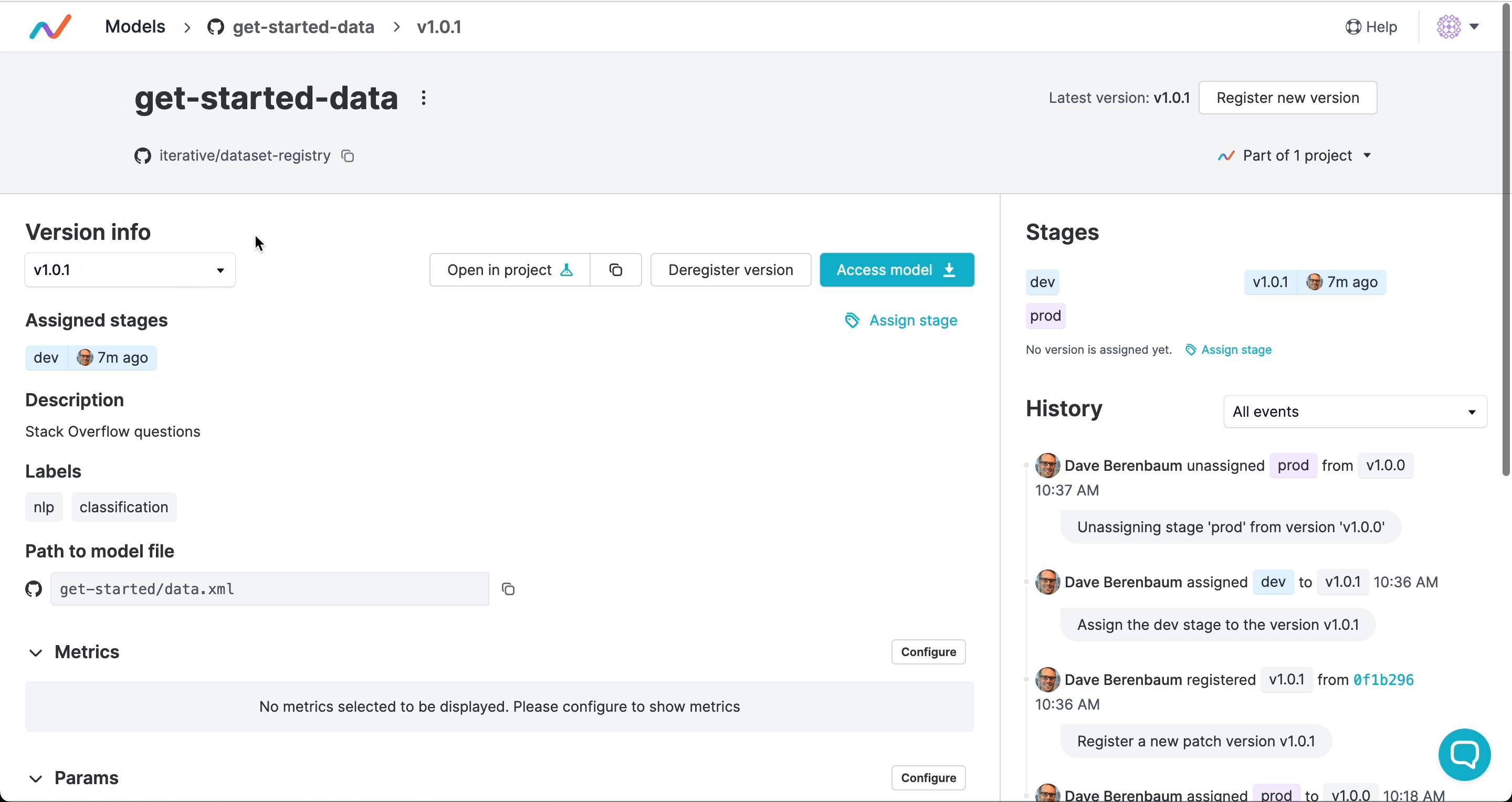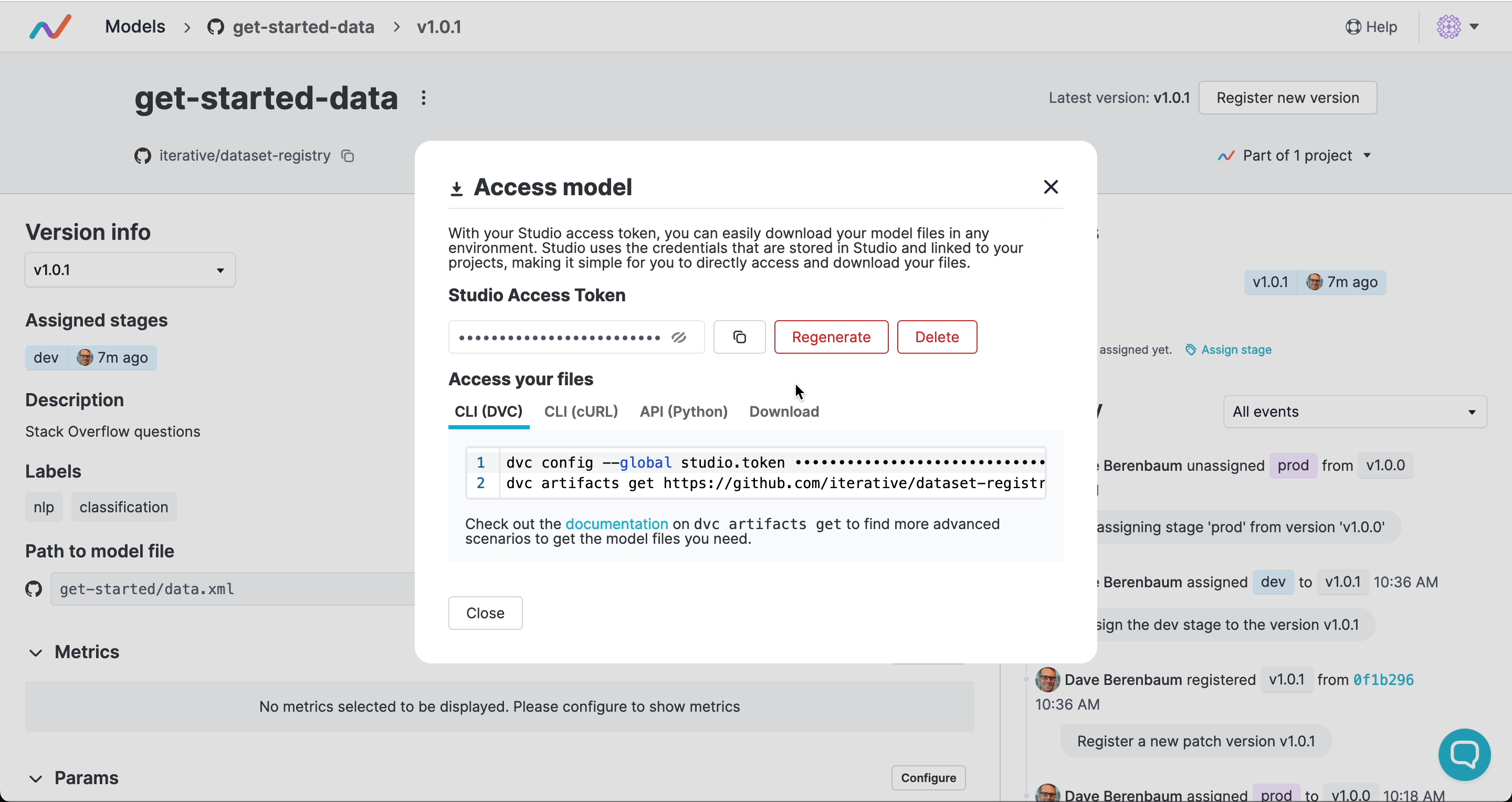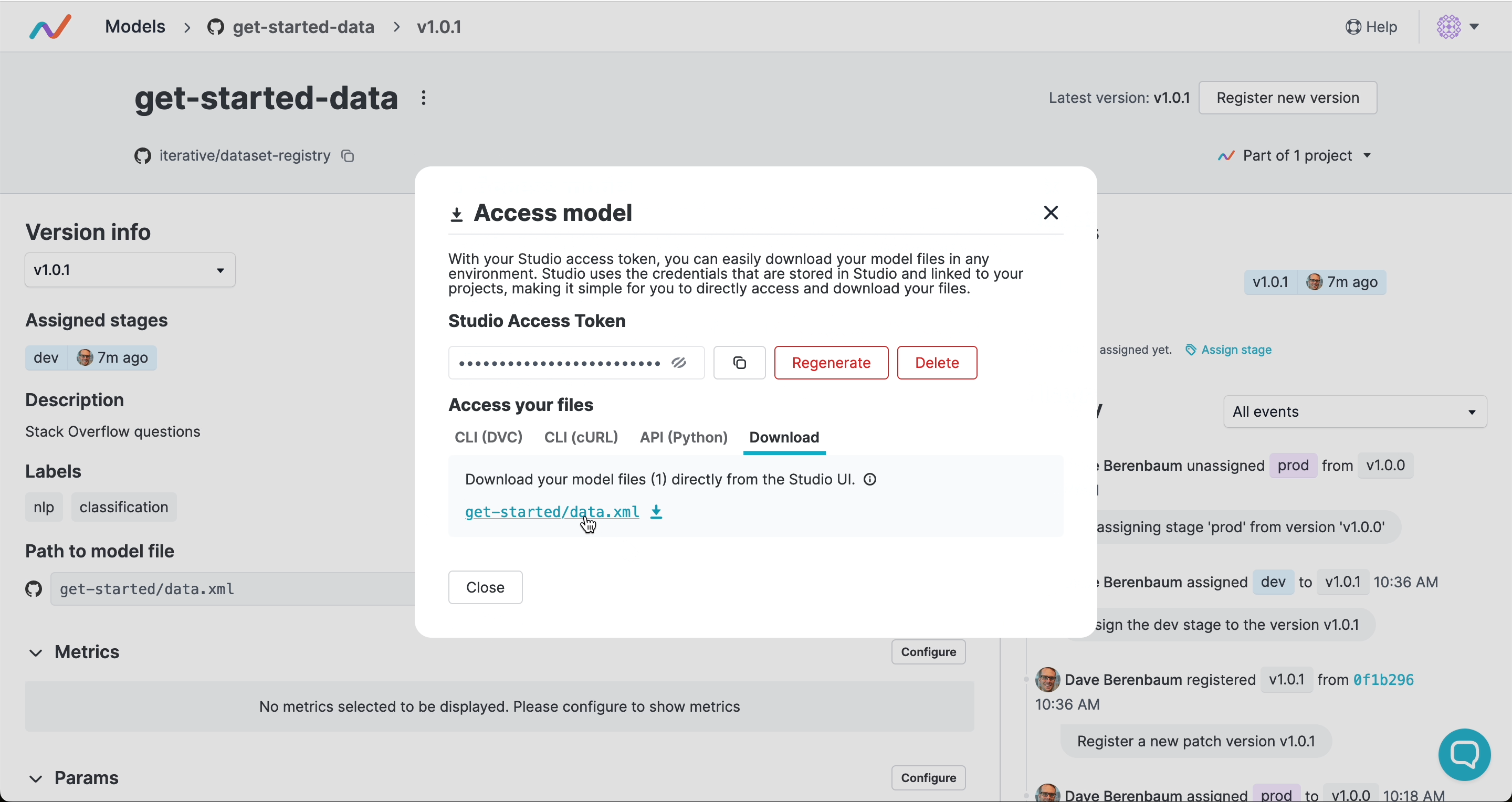
注册版本并分配阶段
版本号和阶段标记指明应使用的提交,并可触发自动化工作流。与软件开发类似,你可以使用语义化版本控制来为产物发布打标签,并将产物版本标记为生产、开发或其他生命周期阶段:
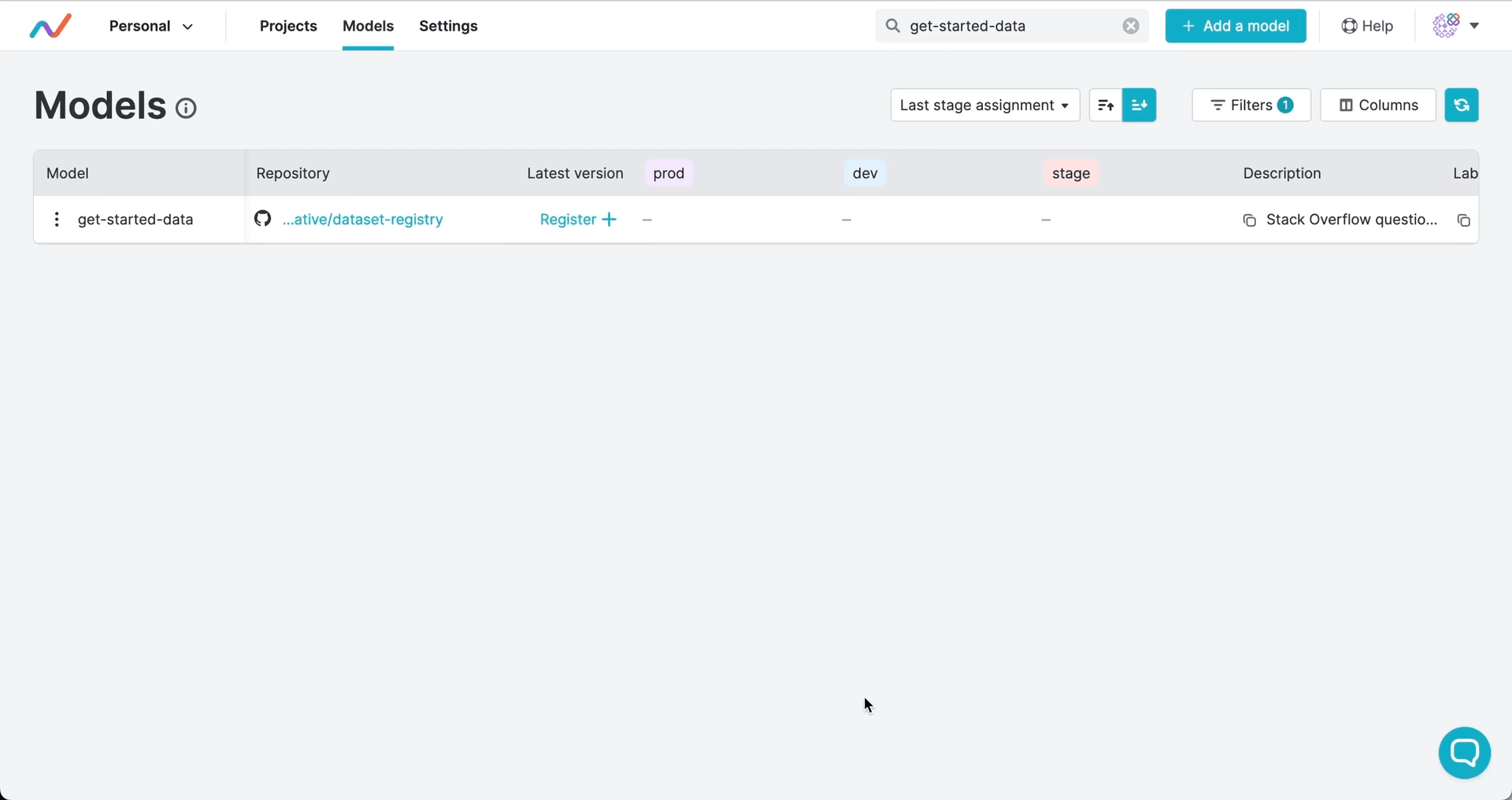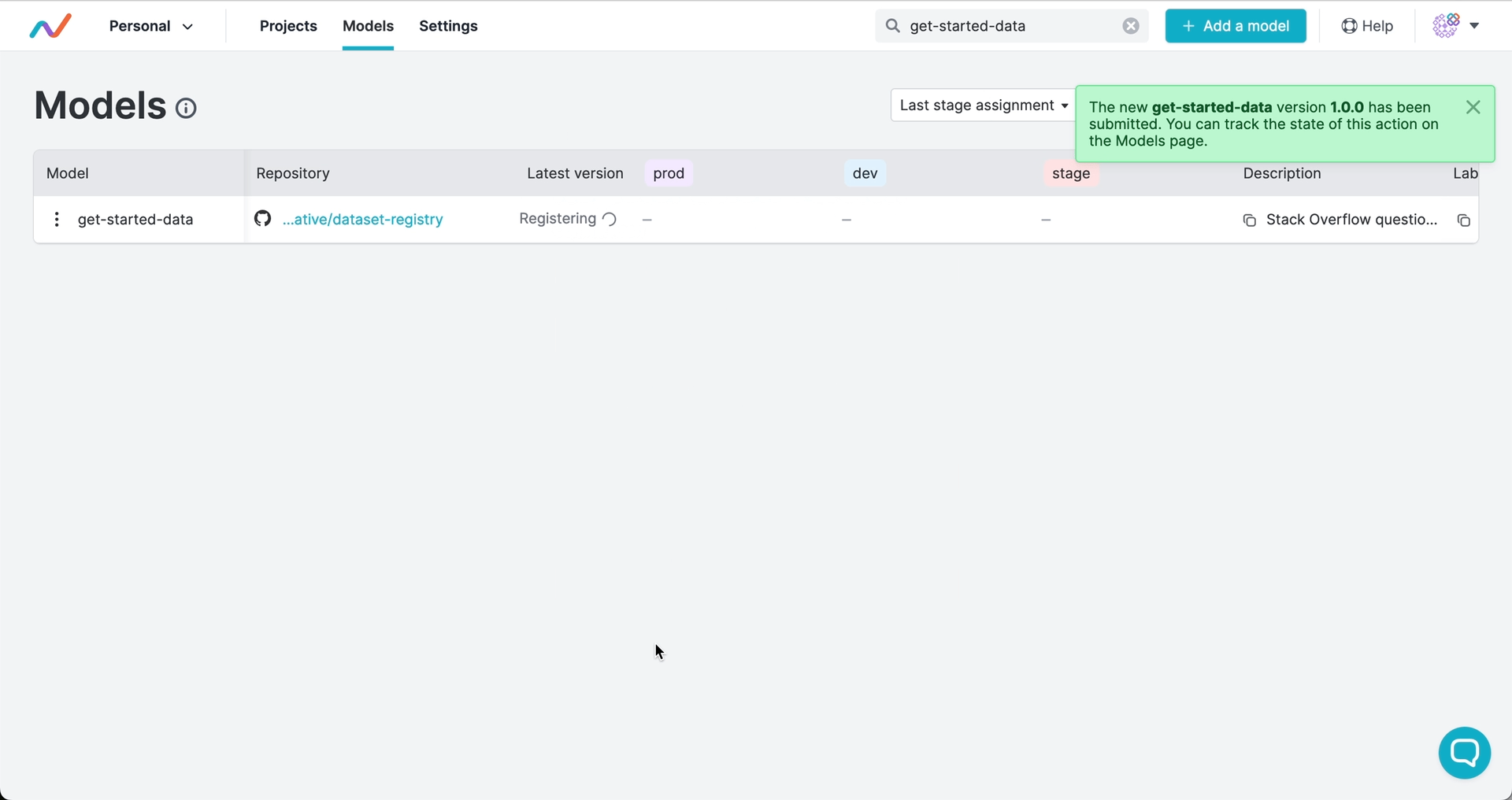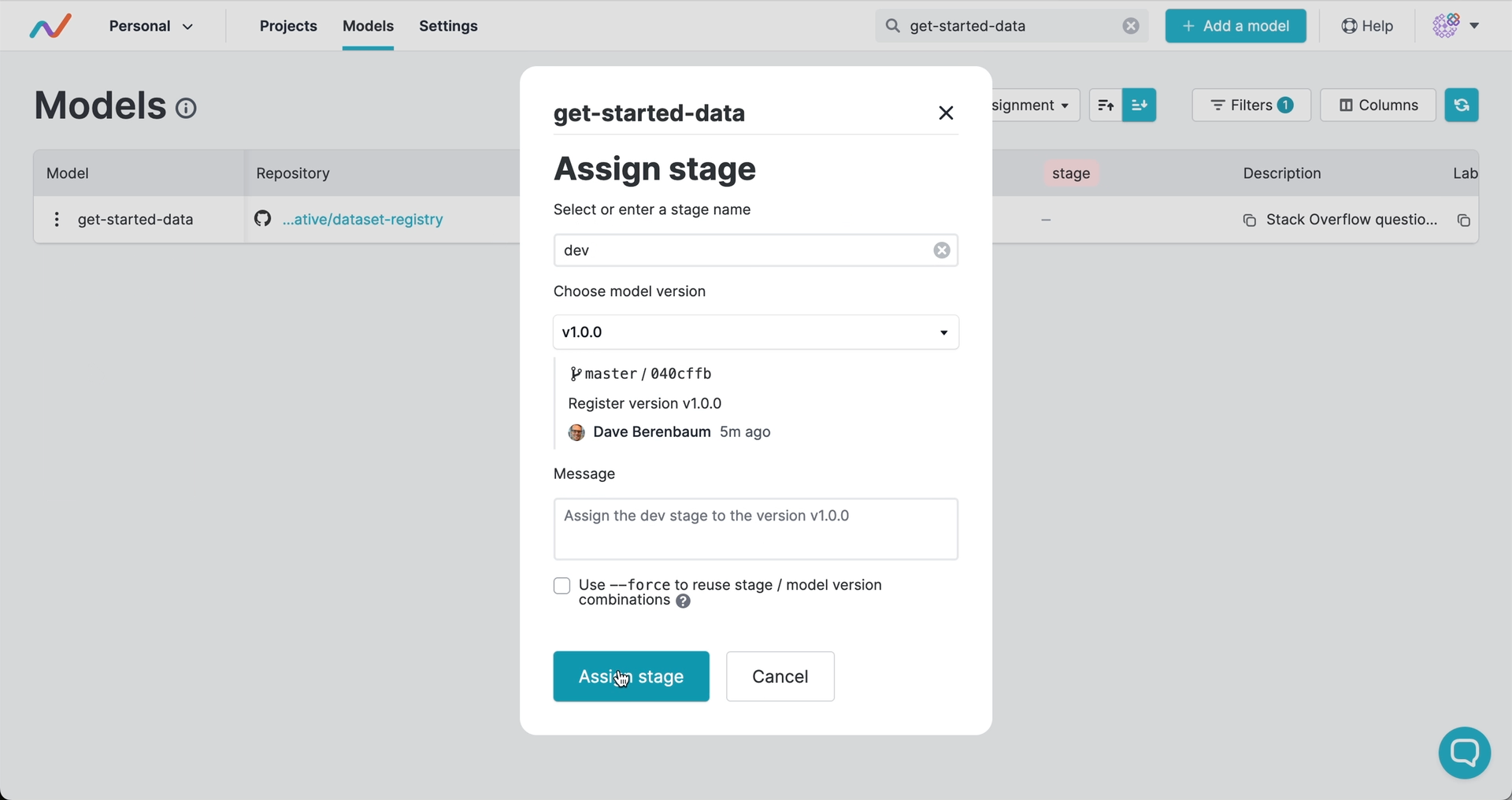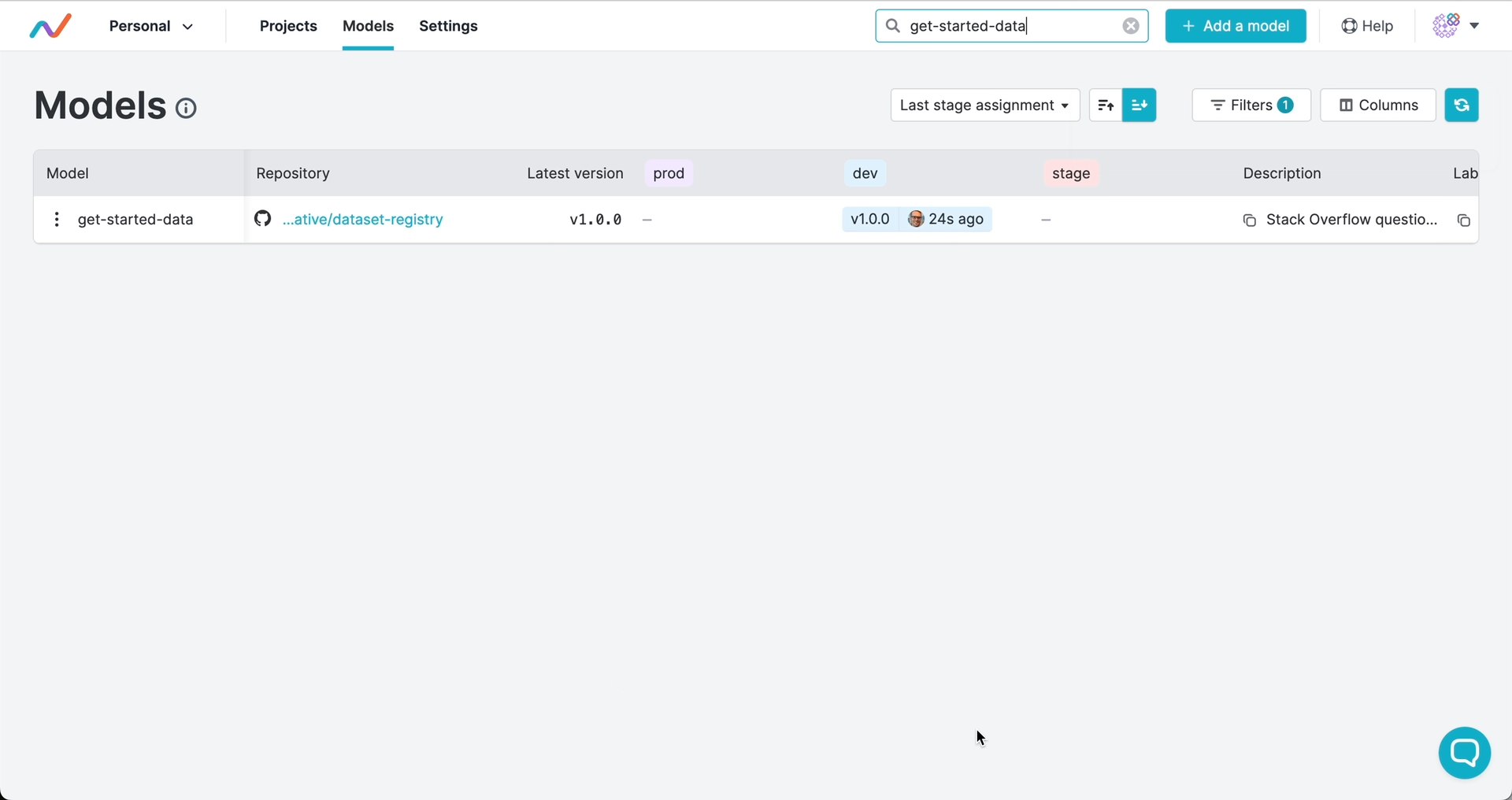
版本和阶段由 GTO 保存为 Git 标签。这意味着你的完整发布历史都保留在 Git 中,且在注册版本或分配阶段时,可触发 CI/CD 工作流中的部署、测试或其他操作。
访问产物
其他人可以通过版本或阶段下载或流式传输产物,而无需访问你的 Git 仓库或云存储。如果你在 DVC Studio 中连接了云凭证,团队中的任何人都可以仅使用 Studio 令牌 在 UI 中或以编程方式访问该产物: