注意
本文档适用于 Ceph 开发版本。
波塞冬存储
关键概念和目标
作为 Crimson 的可插拔后端存储之一,PoseidonStore 仅针对高端 NVMe SSD(不关心 ZNS 设备)。
完全为低 CPU 消耗而设计
针对不同数据类型(原地、非原地)的混合更新策略,通过减少主机端 GC 来最小化 CPU 消耗。
移除类似 RocksDB 的黑盒组件以及 BlueStore 中的文件抽象层,以避免不必要的开销(例如,数据复制和序列化/反序列化)
利用 NVMe 功能(原子大写命令,原子写入单元正常)。使用 io_uring,新的内核异步 I/O 接口,以选择性地使用中断驱动模式以提高 CPU 效率(或轮询模式以降低延迟)。
分片数据/处理模型
背景
原地和非原地更新策略都有其优缺点。
日志结构存储
基于日志结构的存储系统是采用非原地更新方法的典型示例。它永远不会修改已写入的数据。写入始终指向日志的末尾。它支持 I/O 顺序化。
优点
毫无疑问,一次顺序写入就足够存储数据
它自然支持事务(这是没有覆盖,所以存储可以回滚到先前的稳定状态)
对闪存友好(它减轻了 SSD 上的 GC 负担)
缺点
存在主机端 GC,这会导致开销
I/O 放大(主机端)
更多的主机 CPU 消耗
元数据查找缓慢
空间开销(活数据和未使用数据共存)
原地更新存储
原地更新策略已广泛应用于传统文件系统,如 ext4 和 xfs。一旦一个块被放置在给定的磁盘位置,它就不会移动。因此,写入会去磁盘的相应位置。
优点
更少的主机 CPU 消耗(不需要主机端 GC)
快速查找
对于日志结构,没有额外的空间,但存在内部碎片
缺点
写入更多以记录数据(元数据和数据部分是分开的)
它不能支持事务。需要某种 WAL 来确保一般情况下更新的原子性
对闪存不友好(由于设备级 GC,给 SSD 带来更多负担)
动机和关键思想
在现代分布式存储系统中,服务器节点可以配备多个 NVMe 存储设备。实际上,一台服务器上可以连接十台或更多的 NVMe SSD。因此,由于服务器节点中有限的 CPU 资源,很难实现 NVMe SSD 的全部性能。在这样的环境中,CPU 往往成为性能瓶颈。因此,我们现在应该专注于最小化主机 CPU 消耗,这与 Crimson 的目标相同。
为了实现高度针对 CPU 消耗的对象存储,已经做出了三个设计选择。
PoseidonStore 没有像 BlueStore 中的 RocksDB 这样的黑盒组件。
因此,它可以避免不必要的数据复制和序列化/反序列化开销。此外,我们可以移除一个不必要的文件抽象层,这是运行 RocksDB 所必需的。对象数据和元数据现在直接映射到磁盘块。消除所有这些开销将减少 CPU 消耗(例如,预分配、NVME 原子特性)。
PoseidonStore 对不同数据大小使用混合更新策略,类似于 BlueStore。
正如我们所讨论的,原地和非原地更新策略都有其优缺点。由于 CPU 仅在小 I/O 工作负载下成为瓶颈,我们选择原地更新用于小 I/O 以最小化 CPU 消耗,同时选择非原地更新用于大 I/O 以避免双重写入。对于小数据,双重写入从长远来看可能比主机 GC 开销在 CPU 消耗方面更好。尽管它完全将 GC 交给 SSD,
PoseidonStore 利用 io_uring,新的内核异步 I/O 接口来利用中断驱动 I/O。
类似 SPDK 的用户空间驱动 I/O 解决方案通过避免系统调用并从应用程序实现零拷贝访问来提供高 I/O 性能。然而,它不支持中断驱动 I/O,这只有在内核空间驱动 I/O 时才可能。轮询对于低延迟很好,但对于 CPU 效率不好。另一方面,中断对于 CPU 效率很好,但对于低延迟不好(但随着 I/O 大小增加,这并不那么糟糕)。请注意,像 DPDK 这样的网络加速解决方案也过度消耗 CPU 资源用于轮询。在网络和存储处理中都使用轮询会加剧 CPU 消耗。由于网络通常比存储更快且具有更高的优先级,因此轮询应仅应用于网络处理。
高端 NVMe SSD 有足够的性能来处理更多工作。此外,SSD 寿命目前不是实际问题(有足够的程序擦除周期限制[1])。另一方面,对于大 I/O 工作负载,主机可以处理主机 GC。此外,当它们的大小很大时,主机可以更有效地收集无效对象。
观察
Ceph 中的两种数据类型
数据(对象数据)
双重写入的成本很高
存储此数据的最佳方法是原地更新
存储数据至少需要两次操作:1)数据和 2)数据的位置。然而,即使它加剧了 SSD 上的 WAF,常数数量的操作也比非原地更好
元数据或小数据(例如,object_info_t、快照集、pg_log 和集合)
一个对象有多个小尺寸的元数据条目
存储此数据的最佳解决方案是 WAL + 使用缓存
存储元数据的有效方法是将所有与数据相关的元数据合并,并通过单个写入操作存储,即使它需要后台刷新来更新数据分区
设计
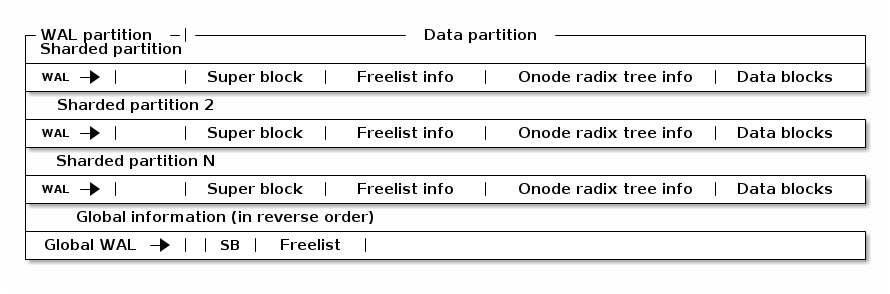
WAL
日志、元数据和小数据存储在 WAL 分区中
WAL 分区中的空间以循环方式不断重用
根据需要将数据刷新到 WAL 以修剪 WAL
磁盘布局
数据块是元数据块或数据块
Freelist 管理空闲空间 B+树的根
超级块包含数据分区管理信息
Onode 根树信息包含 onode 根树的根
I/O 过程
Write
对于传入的写入,根据请求大小不同处理数据;数据要么写入两次(WAL),要么以日志结构的方式写入。
如果 Request Size ≤ 阈值(类似于 BlueStore 中的最小分配大小)
将数据和元数据写入 [WAL] —刷新—> 分别将它们写入 [数据部分(原地)] 和 [元数据部分]。
由于 CPU 在小 I/O 工作负载下成为瓶颈,因此使用原地更新方案。从长远来看,小数据的双重写入可能比主机 GC 开销在 CPU 消耗方面更好
否则如果 Request Size > 阈值
将数据附加到 [数据部分(日志结构)] —> 将相应的元数据写入 [WAL] —刷新—> 将元数据写入 [元数据部分]
对于大 I/O 工作负载,主机可以处理主机 GC
请注意,阈值可以配置为一个非常大的数字,以便仅发生(1)这种情况。通过上述 crimson 优化,我们可以控制整体 I/O 过程。
详细流程
我们使用提供原子性保证的 NVMe 写入命令(原子写入单元电源故障)
阶段 1
如果数据很小
如果数据很大
阶段 2
如果数据很小
如果数据很大
读取
使用缓存的对象元数据来查找数据位置
如果未缓存,需要在检查点和对象元数据分区后搜索 WAL 以找到最新的元数据
刷新(WAL --> 数据分区)
刷新已提交的 WAL 条目。有两种情况(1. WAL 的大小接近满,2. 刷新信号)。我们可以通过批量处理来减轻频繁刷新的开销,但这会导致延迟完成。
故障一致性
大型情况
故障发生在写入数据块后立即发生
数据分区 --> | 数据块 |
我们不需要关心这种情况。数据尚未分配。块将被重用。
故障发生在写入 WAL 后立即发生
数据分区 --> | 数据块 |
WAL --> | TxBegin A | 日志条目 | TxEnd A |
写入过程已完成,因此没有数据丢失或不一致状态
小型情况
故障发生在写入 WAL 后立即发生
WAL --> | TxBegin A | 日志条目| TxEnd A |
所有数据都已写入
比较
最佳情况(预分配)
仅需要在 WAL 和数据分区上进行写入,而无需更新对象元数据(位置)。
最坏情况
至少需要在 WAL、对象元数据和数据块上额外写入三次。
如果从 WAL 到数据分区的刷新频繁发生,onode 树的基数树结构需要多次更新。为了最小化这种开销,我们可以利用批量处理来最小化树上的更新(与对象相关的数据具有局部性,因为它将具有相同的父节点,因此可以最小化更新)
如果 WAL 接近满或需要刷新信号,则需要刷新 WAL。
此设计的假设是 OSD 可以将最新的元数据作为单个副本进行管理。因此,附加的条目不需要读取
无论是最佳情况还是最坏情况,都不会产生严重的 I/O 放大(它产生 I/O,但 I/O 率是恒定的),这与 LSM-树数据库不同(所提出的设
Detailed Design
Onode lookup
Radix tree Our design is entirely based on the prefix tree. Ceph already makes use of the characteristic of OID’s prefix to split or search the OID (e.g., pool id + hash + oid). So, the prefix tree fits well to store or search the object. Our scheme is designed to lookup the prefix tree efficiently.
Sharded partition A few bits (leftmost bits of the hash) of the OID determine a sharded partition where the object is located. For example, if the number of partitions is configured as four, The entire space of the hash in hobject_t can be divided into four domains (0x0xxx ~ 0x3xxx, 0x4xxx ~ 0x7xxx, 0x8xxx ~ 0xBxxx and 0xCxxx ~ 0xFxxx).
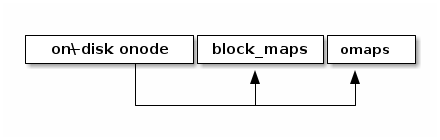
Ondisk onode
struct onode { extent_tree block_maps; b+_tree omaps; map xattrs; }
onode contains the radix tree nodes for lookup, which means we can search for objects using tree node information in onode. Also, if the data size is small, the onode can embed the data and xattrs. The onode is fixed size (256 or 512 byte). On the other hands, omaps and block_maps are variable-length by using pointers in the onode.
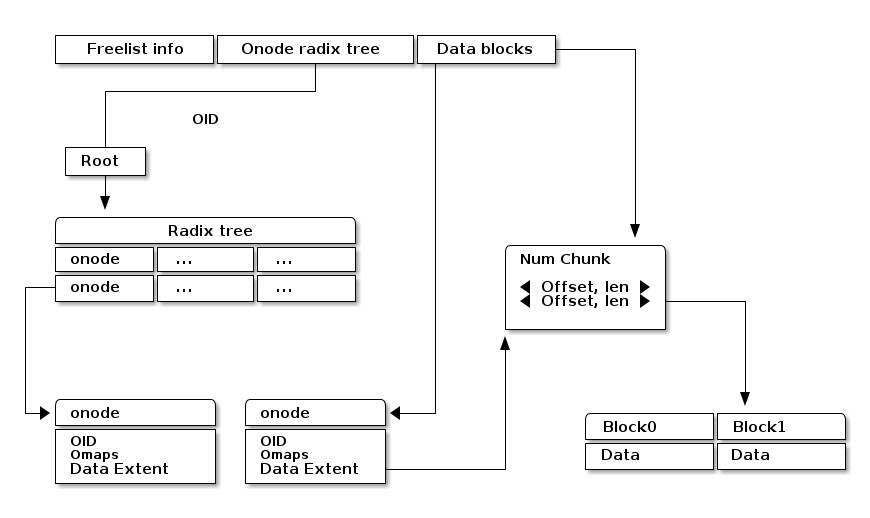
Lookup The location of the root of onode tree is specified on Onode radix tree info, so we can find out where the object is located by using the root of prefix tree. For example, shared partition is determined by OID as described above. Using the rest of the OID’s bits and radix tree, lookup procedure find outs the location of the onode. The extent tree (block_maps) contains where data chunks locate, so we finally figure out the data location.
Allocation
Sharded partitions
The entire disk space is divided into several data chunks called sharded partition (SP). Each SP has its own data structures to manage the partition.
Data allocation
As we explained above, the management infos (e.g., super block, freelist info, onode radix tree info) are pre-allocated in each shared partition. Given OID, we can map any data in Data block section to the extent tree in the onode. Blocks can be allocated by searching the free space tracking data structure (we explain below).
+-----------------------------------+ | onode radix tree root node block | | (Per-SP Meta) | | | | # of records | | left_sibling / right_sibling | | +--------------------------------+| | | keys[# of records] || | | +-----------------------------+|| | | | start onode ID ||| | | | ... ||| | | +-----------------------------+|| | +--------------------------------|| | +--------------------------------+| | | ptrs[# of records] || | | +-----------------------------+|| | | | SP block number ||| | | | ... ||| | | +-----------------------------+|| | +--------------------------------+| +-----------------------------------+
Free space tracking The freespace is tracked on a per-SP basis. We can use extent-based B+tree in XFS for free space tracking. The freelist info contains the root of free space B+tree. Granularity is a data block in Data blocks partition. The data block is the smallest and fixed size unit of data.
+-----------------------------------+ | Free space B+tree root node block | | (Per-SP Meta) | | | | # of records | | left_sibling / right_sibling | | +--------------------------------+| | | keys[# of records] || | | +-----------------------------+|| | | | startblock / blockcount ||| | | | ... ||| | | +-----------------------------+|| | +--------------------------------|| | +--------------------------------+| | | ptrs[# of records] || | | +-----------------------------+|| | | | SP block number ||| | | | ... ||| | | +-----------------------------+|| | +--------------------------------+| +-----------------------------------+
Omap and xattr In this design, omap and xattr data is tracked by b+tree in onode. The onode only has the root node of b+tree. The root node contains entries which indicate where the key onode exists. So, if we know the onode, omap can be found via omap b+tree.
Fragmentation
Internal fragmentation
We pack different types of data/metadata in a single block as many as possible to reduce internal fragmentation. Extent-based B+tree may help reduce this further by allocating contiguous blocks that best fit for the object
External fragmentation
Frequent object create/delete may lead to external fragmentation In this case, we need cleaning work (GC-like) to address this. For this, we are referring the NetApp’s Continuous Segment Cleaning, which seems similar to the SeaStore’s approach Countering Fragmentation in an Enterprise Storage System (NetApp, ACM TOS, 2020)
WAL
Each SP has a WAL. The data written to the WAL are metadata updates, free space update and small data. Note that only data smaller than the predefined threshold needs to be written to the WAL. The larger data is written to the unallocated free space and its onode’s extent_tree is updated accordingly (also on-disk extent tree). We statically allocate WAL partition aside from data partition pre-configured.
Partition and Reactor thread
In early stage development, PoseidonStore will employ static allocation of partition. The number of sharded partitions is fixed and the size of each partition also should be configured before running cluster. But, the number of partitions can grow as below. We leave this as a future work. Also, each reactor thread has a static set of SPs.

缓存
There are mainly two cache data structures; onode cache and block cache. It looks like below.
Onode cache: lru_map <OID, OnodeRef>;
Block cache (data and omap): Data cache --> lru_map <paddr, value>
To fill the onode data structure, the target onode needs to be retrieved using the prefix tree. Block cache is used for caching a block contents. For a transaction, all the updates to blocks (including object meta block, data block) are first performed in the in-memory block cache. After writing a transaction to the WAL, the dirty blocks are flushed to their respective locations in the respective partitions. PoseidonStore can configure cache size for each type. Simple LRU cache eviction strategy can be used for both.
CoW/Clone
As for CoW/Clone, a clone has its own onode like other normal objects.
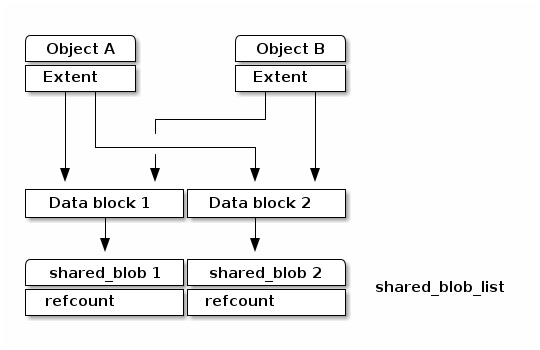
Although each clone has its own onode, data blocks should be shared between the original object and clones if there are no changes on them to minimize the space overhead. To do so, the reference count for the data blocks is needed to manage those shared data blocks.
To deal with the data blocks which has the reference count, poseidon store makes use of shared_blob which maintains the referenced data block.
As shown the figure as below, the shared_blob tracks the data blocks shared between other onodes by using a reference count. The shared_blobs are managed by shared_blob_list in the superblock.
Plans
All PRs should contain unit tests to verify its minimal functionality.
WAL and block cache implementation
As a first step, we are going to build the WAL including the I/O procedure to read/write the WAL. With WAL development, the block cache needs to be developed together. Besides, we are going to add an I/O library to read/write from/to the NVMe storage to utilize NVMe feature and the asynchronous interface.
Radix tree and onode
First, submit a PR against this file with a more detailed on disk layout and lookup strategy for the onode radix tree. Follow up with implementation based on the above design once design PR is merged. The second PR will be the implementation regarding radix tree which is the key structure to look up objects.
范围树
This PR is the extent tree to manage data blocks in the onode. We build the extent tree, and demonstrate how it works when looking up the object.
B+tree for omap
We will put together a simple key/value interface for omap. This probably will be a separate PR.
CoW/Clone
To support CoW/Clone, shared_blob and shared_blob_list will be added.
Integration to Crimson as to I/O interfaces
At this stage, interfaces for interacting with Crimson such as queue_transaction(), read(), clone_range(), etc. should work right.
配置
We will define Poseidon store configuration in detail.
Stress test environment and integration to teuthology
We will add stress tests and teuthology suites.
Footnotes
由 Ceph 基金会带给您
Ceph 文档是一个社区资源,由非盈利的 Ceph 基金会资助和托管Ceph Foundation. 如果您想支持这一点和我们的其他工作,请考虑加入现在加入.