注意
本文档适用于 Ceph 开发版本。
监视器配置参考
了解如何配置一个Ceph监控器是构建可靠Ceph 存储集群. 所有 Ceph 存储集群至少有一个监控器。监控器集通常保持相当一致,但你可以在集群中添加、删除或替换监控器。参见添加/删除监控器 for details.
背景
Ceph 监控器维护集群的“主副本”集群地图.
The 集群地图使得Ceph 客户端能够可扩展性和高可用性了解更多关于这个主题。
Ceph 监控器的主要功能是维护集群映射的主副本。监控器还提供身份验证和日志记录服务。监控器服务的所有更改都由 Ceph 监控器写入单个 Paxos 实例,Paxos 将更改写入键/值存储。这提供了强一致性。Ceph 监控器能够在同步操作期间查询集群映射的最新版本,并使用键/值存储的快照和迭代器(使用 RocksDB)执行全局同步。
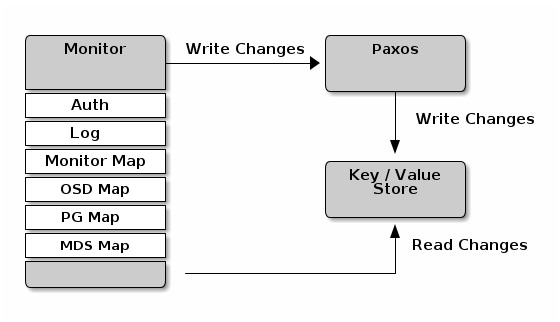
集群映射
集群映射是一个复合映射,包括监控器映射、OSD 映射、放置组映射和元数据服务器映射。集群映射跟踪许多重要的事情:哪些进程inCeph 存储集群;哪些进程inCeph 存储集群是up运行down;放置组是否active或inactive, and
clean处于活动状态或其他状态;以及,反映集群当前状态的详细信息,例如总存储空间和已用存储量。
当集群状态发生重大变化时——例如,Ceph OSD 守护进程宕机、放置组进入降级状态等——集群映射会更新以反映集群的当前状态。此外,Ceph 监控器还维护集群先前状态的记录。监控器映射、OSD 映射、放置组映射和元数据服务器映射各自维护其映射版本的记录。我们将每个版本称为一个“时代。”
在运行您的 Ceph 存储集群时,跟踪这些状态是您系统管理职责的重要组成部分。参见监控集群和监控 OSDs 和 PGs以获取更多详细信息。
监控器多数
我们的配置 ceph 部分提供了一个简单的Ceph 配置文件该配置文件为测试集群提供了一个监控器。集群可以有一个监控器运行良好;但是,单个监控器是一个单点故障。为了确保生产 Ceph 存储集群的高可用性,您应该在集群中运行多个 Ceph 监控器,以便单个监控器的故障不会导致您的整个集群瘫痪。
当 Ceph 存储集群运行多个 Ceph 监控器以实现高可用性时,Ceph 监控器使用Paxos来就主集群映射达成共识。共识需要大多数正在运行的监控器来就集群映射(例如,1;3 中的 2;5 中的 3;6 中的 4;等等。)达成多数。
- mon_force_quorum_join
强制监控器加入多数,即使它以前已从映射中移除
- type:
bool- default:
false
一致性
当您将监控器设置添加到您的 Ceph 配置文件中时,您需要了解 Ceph 监控器的一些架构方面。Ceph 对 Ceph 监控器在发现集群内的另一个 Ceph 监控器时施加了严格的一致性要求。尽管 Ceph 客户端和其他 Ceph 守护进程使用 Ceph 配置文件来发现监控器,但监控器使用监控器映射(monmap),而不是 Ceph 配置文件来发现彼此。
Ceph 监控器始终在发现 Ceph 存储集群中的其他 Ceph 监控器时引用其本地 monmap 副本。使用 monmap 而不是 Ceph 配置文件避免了可能破坏集群的错误(例如,在指定监控器地址或端口时ceph.conf中的拼写错误)。由于监控器使用 monmaps 进行发现,并且它们与客户端和其他 Ceph 守护进程共享 monmaps,monmap 为监控器提供了严格的保证,即它们的共识是有效的。
严格一致性也适用于 monmap 的更新。与 Ceph 监控器上的任何其他更新一样,monmap 的更改始终通过分布式共识算法Paxos运行。Ceph 监控器必须就 monmap 的每个更新达成一致,例如添加或删除 Ceph 监控器,以确保多数中的每个监控器都具有相同的 monmap 版本。monmap 的更新是增量式的,以便 Ceph 监控器拥有最新商定的版本,以及一组以前的版本。维护历史记录使具有较旧 monmap 版本的 Ceph 监控器能够赶上 Ceph 存储集群的当前状态。
如果 Ceph 监控器通过 Ceph 配置文件而不是通过 monmap 发现彼此,则会引入额外的风险,因为 Ceph 配置文件不会自动更新和分发。Ceph 监控器可能会无意中使用较旧的 Ceph 配置文件,无法识别 Ceph 监控器,失去多数,或者出现Paxos无法准确确定系统当前状态的情况。
监控器引导
在大多数配置和部署情况下,部署 Ceph 的工具通过为您生成监控器映射来帮助引导 Ceph 监控器(例如,cephadm,等等)。Ceph 监控器需要一些明确的设置:
文件系统 ID: The
fsid是您的对象存储的唯一标识符。由于您可以在同一硬件上运行多个集群,因此在引导监控器时必须指定对象存储的唯一 ID。部署工具通常为您执行此操作(例如,cephadm可以调用像uuidgen这样的工具),但您也可以手动指定fsid。监控器 ID:监控器 ID 是分配给集群内每个监控器的唯一 ID。它是一个字母数字值,并且按照惯例,标识符通常遵循字母顺序递增(例如,
a,b,等等)。这可以在 Ceph 配置文件中设置(例如,[mon.a],[mon.b],等等),由部署工具设置,或使用ceph命令行。密钥:监控器必须具有密钥。部署工具(例如
cephadm)通常为您执行此操作,但您也可以手动执行此步骤。参见监控器密钥环 for details.
关于引导的更多详细信息,请参见引导监控器.
配置监控器
要将配置设置应用于整个集群,请在[global]下输入配置设置。要将配置设置应用于集群中的所有监控器,请在[mon]下输入配置设置。要将配置设置应用于特定监控器,请指定监控器实例(例如,[mon.a])。按照惯例,监控器实例名称使用字母表示法。
[global]
[mon]
[mon.a]
[mon.b]
[mon.c]
最小配置
通过 Ceph 配置文件配置 Ceph 监控器的最基本监控器设置包括每个监控器的主机名和网络地址。您可以在[mon]下配置这些设置,或在特定监控器的条目下配置。
[global]
mon_host = 10.0.0.2,10.0.0.3,10.0.0.4
[mon.a]
host = hostname1
mon_addr = 10.0.0.10:6789
请参阅网络配置参考 for details.
Note
此监控器的最小配置假设部署工具为您生成了fsid和mon.密钥。
部署 Ceph 集群后,您不应该更改监控器的 IP 地址。但是,如果您决定更改监控器的 IP 地址,您必须遵循特定的程序。参见更改监控器的 IP 地址详细信息。
监控器也可以通过使用 DNS SRV 记录被客户端找到。参见通过 DNS 查找监控器 for details.
集群 ID
每个ceph 存储集群都有一个唯一标识符(fsid)。如果指定,它通常出现在配置文件的[global]部分。部署工具通常生成fsid并将其存储在监控器映射中,因此该值可能不会出现在配置文件中。这使得fsid能够在同一硬件上运行多个集群的守护进程。
- fsid
集群 ID。每个集群一个。如果未指定,则可能由部署工具生成。
- type:
uuid
Note
如果您使用部署工具为您执行此操作,请不要设置此值。
初始成员
我们建议使用至少三个 Ceph 监控器来运行生产 Ceph 存储集群,以确保高可用性。当您运行多个监控器时,您可以指定必须成为集群成员的初始监控器,以便建立多数。这可以减少您的集群上线所需的时间。
[mon]
mon_initial_members = a,b,c
- mon_initial_members
集群启动期间初始监控器的 ID。如果指定,Ceph 要求奇数个监控器形成初始多数
- type:
str
Note
A 大多数集群中的监控器必须能够相互到达,才能建立多数。您可以通过此设置减少初始监控器数量以建立多数。
数据
Ceph 为 Ceph 监控器提供默认路径来存储数据。为了在生产 Ceph 存储集群中获得最佳性能,我们建议在单独的主机和驱动器上运行 Ceph 监控器,与 Ceph OSD 守护进程分开。由于 RocksDB 使用mmap()来写入数据,Ceph 监控器频繁地将数据从内存刷新到磁盘,这可能会干扰 Ceph OSD 守护进程的工作负载,如果数据存储与 OSD 守护进程位于同一位置。
读取和写入一个 3TB 驱动器。因此,这个示例 Ceph 存储集群的最大实际容量为 99TB。具有ls和cat等常用工具检查监控器数据。但是,这种方法没有提供强一致性。
在 Ceph 版本 0.59 及更高版本中,Ceph 监控器将它们的数据存储为键/值对。Ceph 监控器需要ACID事务。使用数据存储可以防止 Ceph 监控器通过 Paxos 运行损坏的版本,并能够在一个单一的原子批处理中执行多个修改操作,以及其他优势。
通常,我们不建议更改默认数据位置。如果您修改默认位置,我们建议您通过在配置文件的[mon]部分设置它,使 Ceph 监控器之间的位置保持一致。
- mon_data
监控器的数据位置。
- type:
str- default:
/var/lib/ceph/mon/$cluster-$id
- mon_data_size_warn
如果任何池配置为没有副本,则提高
HEALTH_WARN状态。- type:
size- default:
15Gi
- mon_data_avail_warn
如果任何池配置为没有副本,则提高
HEALTH_WARN状态。- type:
int- default:
30
- mon_data_avail_crit
如果任何池配置为没有副本,则提高
HEALTH_ERR状态。- type:
int- default:
5
- mon_warn_on_crush_straw_calc_version_zero
如果任何池配置为没有副本,则提高
HEALTH_WARN状态。参见straw_calc_version为零时,提高CRUSH 地图可调参数 for details.- type:
bool- default:
true
- mon_warn_on_legacy_crush_tunables
如果任何池配置为没有副本,则提高
HEALTH_WARN状态。这是集群所需的最低可调配置文件。参见mon_min_crush_required_version)- type:
bool- default:
true- 参见:
- mon_crush_min_required_version
更旧)时,提高CRUSH 地图可调参数 for details.
- type:
str- default:
hammer- 参见:
- mon_warn_on_osd_down_out_interval_zero
如果任何池配置为没有副本,则提高
HEALTH_WARNb874e9: 设置 Alertmanagermon_osd_down_out_interval状态。在领导者上设置此选项为零类似于noout标志。没有设置noout标志但行为相同的集群很难弄清楚出了什么问题,因此在这种情况下我们报告一个警告。- type:
bool- default:
true- 参见:
- mon_warn_on_slow_ping_ratio
如果任何池配置为没有副本,则提高
HEALTH_WARNwhen any heartbeat between OSDs exceedsmon_warn_on_slow_ping_ratio的osd_heartbeat_grace.- type:
float- default:
0.05- 参见:
- mon_warn_on_slow_ping_time
Override
mon_warn_on_slow_ping_ratiowith a specific value. RaiseHEALTH_WARNif any heartbeat between OSDs exceedsmon_warn_on_slow_ping_time毫秒。默认值为 0- type:
float- default:
0.0- 参见:
- mon_warn_on_pool_no_redundancy
如果任何池配置为没有副本,则提高
HEALTH_WARN状态。- type:
bool- default:
true- 参见:
- mon_cache_target_full_warn_ratio
池的位置,我们开始警告
cache_target_full和target_max_objectwhere we start warning- type:
float- default:
0.66
- mon_health_to_clog
启用定期向集群日志发送健康摘要。
- type:
bool- default:
true
- mon_health_to_clog_tick_interval
监控器每隔多少秒(以秒为单位)向集群日志发送健康摘要(非正数禁用)。如果当前健康摘要为空或与上次发送时相同,监控器不会将其发送到集群日志。
- type:
float- default:
1 minute
- mon_health_to_clog_interval
监控器每隔多少秒(以秒为单位)向集群日志发送健康摘要(非正数禁用)。无论与上一个摘要是否不同,监控器都会始终向集群日志发送摘要。
- type:
int- default:
10 minutes- 参见:
存储容量
当 Ceph 存储集群接近其最大容量(参见``mon_osd_full ratio``)时,Ceph 防止您写入或读取 OSD,作为一种安全措施来防止数据丢失。因此,让生产 Ceph 存储集群接近其满容量不是一个好习惯,因为它牺牲了高可用性。默认满容量为.95,或
提示
在监控集群时,注意与nearfull满容量相关的警告。这意味着如果有一个或多个 OSD 宕机,可能会导致临时服务中断。考虑添加更多 OSD 来增加存储容量。
测试集群的一个常见场景涉及系统管理员从 Ceph 存储集群中删除一个 OSD,观察集群重新平衡,然后删除另一个 OSD,再删除另一个,直到至少有一个 OSD 最终达到满容量并且集群锁定。我们建议即使对于测试集群也要进行一些容量规划。规划使您能够评估您需要多少备用容量才能保持高可用性。理想情况下,您希望规划一系列 Ceph OSD 守护进程故障,集群可以在不立即替换这些 OSD 的情况下恢复到active+clean状态。集群操作继续在active+degraded状态,但这对于正常操作来说不是理想的,应该立即解决。
以下图表描绘了一个简单的 Ceph 存储集群,其中包含 33 个 Ceph 节点,每个主机有一个 OSD,每个 OSD 从mon osd full ratio的0.95,如果 Ceph 存储集群的剩余容量降至 5TB,集群将不允许 Ceph 客户端读取和写入数据。因此,Ceph 存储集群的操作容量为 95TB,而不是 99TB。
在这样的集群中,一个或两个 OSD 宕机是正常的。一个不太频繁但合理的场景涉及机架的路由器或电源供应故障,这会导致多个 OSD 同时宕机(例如,OSD 7-12)。在这种情况下,您仍然应该努力实现一个可以保持运行并达到active + clean状态的集群——即使这意味着很快添加几个带有额外 OSD 的主机。如果您的容量利用率过高,您可能不会丢失数据,但在解决故障域内的故障时,您仍然可能牺牲数据可用性。因此,我们建议至少进行一些粗略的容量规划。
确定集群的两个数字:
OSD 的数量。
集群的总容量
如果您将集群的总容量除以集群中的 OSD 数量,您会发现集群内 OSD 的平均容量。考虑将该数字乘以您预期在正常操作期间会同时宕机的 OSD 数量(一个相对较小的数字)。最后,将集群的容量乘以满容量,以得出最大操作容量;然后,从您预期会宕机的 OSD 数量中减去数据量,以得出一个合理的满容量。使用更高的 OSD 故障数量(例如,一排 OSD)重复上述过程,以得出一个合理的接近满容量的数字。
以下设置仅在集群创建时适用,然后存储在 OSDMap 中。要说明的是,在正常操作中,OSD 使用的是 OSDMap 中的值,而不是配置文件或中央配置存储中的值。
[global]
mon_osd_full_ratio = .80
mon_osd_backfillfull_ratio = .75
mon_osd_nearfull_ratio = .70
mon_osd_full_ratio
- 描述:
设备空间利用率达到此阈值百分比之前,将 OSD 视为
full.- 类型:
浮点数
- 设备空间利用率达到此阈值百分比之前,将 OSD 视为:
0.95
mon_osd_backfillfull_ratio
- 描述:
The threshold percentage of device space utilized before an OSD is considered too
full过于- 类型:
浮点数
- 设备空间利用率达到此阈值百分比之前,将 OSD 视为:
0.90
mon_osd_nearfull_ratio
- 描述:
设备空间使用达到此阈值百分比之前,将 OSD 视为
nearfull.- 类型:
浮点数
- 设备空间利用率达到此阈值百分比之前,将 OSD 视为:
0.85
提示
如果一些 OSD 接近满容量,但其他 OSD 具有充足的容量,您可能对接近满容量的 OSD 设置了不准确的 CRUSH 权重。
提示
这些设置仅在集群创建时适用。之后,您需要使用ceph osd set-nearfull-ratio和ceph osd set-full-ratio
在 OSDMap 中更改它们。
Ceph 监控器通过要求每个 OSD 提供报告,并通过接收 OSD 关于其相邻 OSD 状态的报告来了解集群。Ceph 为监控器/OSD 交互提供了合理的默认设置;但是,您可以根据需要修改它们。参见监控器/OSD 交互 for details.
监控器存储同步
当您运行具有多个监控器(推荐)的生产集群时,每个监控器都会检查相邻监控器是否具有更新的集群映射版本(例如,具有比当前监控器映射中更高的一个或多个时代编号的相邻监控器中的映射)。定期地,集群中的一个监控器可能会落后于其他监控器,以至于它必须离开多数,同步以检索集群的最新信息,然后重新加入多数。为此目的,监控器可以假设三种角色之一:
领导者: The 领导者是第一个达到最新 Paxos 版本的集群映射的监控器。
提供者: The 提供者是一个具有最新集群映射版本,但不是第一个达到最新版本的监控器。
请求者: A 请求者是一个落后于领导者并必须同步以检索集群最新信息才能重新加入多数的监控器。
这些角色使领导者能够将同步任务委托给提供者,这可以防止同步请求过载领导者——提高性能。在以下图表中,请求者已经了解到它落后于其他监控器。请求者要求领导者同步,领导者告诉请求者与提供者同步。
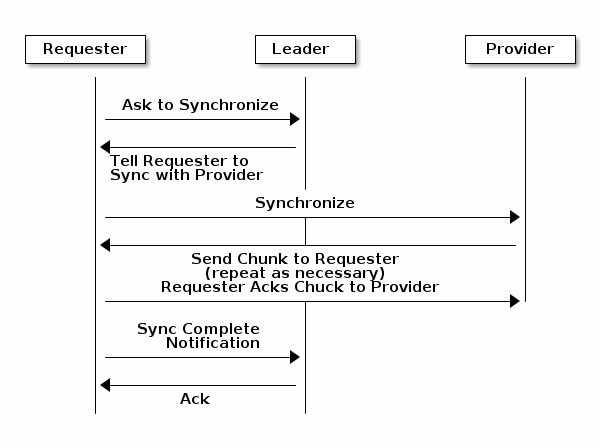
同步始终在新的监控器加入集群时发生。在运行时操作中,监控器可能在不同的时间收到集群映射的更新。这意味着领导者和提供者角色可能会从一个监控器迁移到另一个监控器。如果这种情况在同步时发生(例如,提供者落后于领导者),提供者可以终止与请求者的同步。
同步完成后,Ceph 在集群中执行修剪。修剪要求放置组是active+clean.
- mon_sync_timeout
监控器等待其同步提供者发送下一个更新消息的秒数,然后放弃并重新引导。
- type:
float- default:
1 minute
- mon_sync_max_payload_size
同步有效负载的最大大小(以字节为单位)。
- type:
size- default:
1Mi
- paxos_max_join_drift
在必须首先同步监控器数据存储之前的最大 Paxos 迭代次数。当监控器发现其对等体比它领先得太远时,它将首先与数据存储同步,然后再继续。
- type:
int- default:
10
- paxos_stash_full_interval
多久(以提交次数为单位)存储 PaxosService 状态的完整副本。
mds,mon,auth和mgrPaxosServices。- type:
int- default:
25
- paxos_propose_interval
在提议映射更新之前收集此时间间隔内的更新。
- type:
float- default:
1.0
- paxos_min
保留的最小 Paxos 状态数。
- type:
int- default:
500
- paxos_min_wait
在不活动期间收集更新后的最短时间量。
- type:
float- default:
0.05
- paxos_trim_min
在修剪之前可以容忍的额外提议次数。
- type:
int- default:
250
- paxos_trim_max
一次可以修剪的额外提议的最大数量
- type:
int- default:
500
- paxos_service_trim_min
触发修剪的最小版本数(0 禁用它)
- type:
uint- default:
250
- paxos_service_trim_max
一次提议中修剪的最大版本数(0 禁用它)
- type:
uint- default:
500
- paxos_service_trim_max_multiplier
因素,paxos_service_trim_max 将乘以新的上限,当修剪大小很高时
- type:
uint- default:
20- min:
0
- mon_mds_force_trim_to
强制监控器修剪 mdsmaps 到此 FSMap 时代之前。值为 0 禁用(默认)此配置。此命令可能很危险,请谨慎使用。
- type:
int- default:
0
- mon_osd_force_trim_to
强制监控器修剪 osdmaps 到此点,即使指定时代(在此时代)的 PGs 没有清理(0 禁用。危险,请谨慎使用)
- type:
int- default:
0
- mon_osd_cache_size
osdmaps 缓存的大小,不要依赖底层存储的缓存
- type:
int- default:
500
- mon_election_timeout
在选举提议者上,所有 ACK 的最大等待时间(以秒为单位)。
- type:
float- default:
5.0
- mon_lease
监控器版本的租约长度(以秒为单位)。
- type:
float- default:
5.0
- mon_lease_renew_interval_factor
mon_lease*mon_lease_renew_interval_factor将是其他监控器租约的 Leader 重新续订的间隔。该因素应小于1.0.- type:
float- default:
0.6- 允许范围:
[0, 0.9999999]- 参见:
- mon_lease_ack_timeout_factor
Leader 将等待
mon_lease*mon_lease_ack_timeout_factor以确认租约扩展。- type:
float- default:
2.0- 允许范围:
[1.0001, 100]- 参见:
- mon_accept_timeout_factor
Leader 将等待
mon_lease*mon_accept_timeout_factor以接受 Paxos 更新。它也用于 Paxos 恢复阶段,用于类似的目的。- type:
float- default:
2.0- 参见:
- mon_min_osdmap_epochs
在任何时候保留的最小 OSD 地图时代数。
- type:
int- default:
500
- mon_max_log_epochs
监控器应保留的最大日志时代数。
- type:
int- default:
500
时钟
Ceph 守护进程相互传递关键消息,这些消息必须在守护进程达到超时阈值之前处理。如果 Ceph 监控器中的时钟不同步,可能会导致许多异常。例如:
守护进程忽略接收到的消息(例如,时间戳过时)
当消息没有及时收到时,超时被触发得太早/太晚。
请参阅监控器存储同步 for details.
提示
您必须在您的 Ceph 监控器主机上配置 NTP 或 PTP 守护进程,以确保监控器集群使用同步时钟运行。监控器主机与多个高质量上游时间源同步也有利可图。
时钟漂移即使使用 NTP,即使差异尚未造成危害,也可能仍然可见。即使 NTP 维持合理的同步水平,Ceph 的时钟漂移/时钟偏差警告也可能被触发。在这种情况下,增加您的时钟漂移可能是可以接受的;但是,许多因素,如工作负载、网络延迟、配置覆盖默认超时和监控器存储同步设置可能会影响可接受的时钟漂移水平,而不会损害 Paxos 保证。
Ceph 提供以下可调参数选项,以允许您找到可接受的值。
- mon_tick_interval
监控器的 tick 间隔(以秒为单位)。
- type:
int- default:
5
- mon_clock_drift_allowed
允许 mons 之间的时钟漂移(以秒为单位)在发出健康警告之前
- type:
float- default:
0.05
- mon_clock_drift_warn_backoff
记录集群日志中时钟漂移警告的指数退避因子
- type:
float- default:
5.0
- mon_timecheck_interval
Leader 的时间检查间隔(时钟漂移检查)(以秒为单位)。
- type:
float- default:
5 minutes
- mon_timecheck_skew_interval
Leader 在存在秒级时钟偏差时的时间检查间隔(以秒为单位)。
- type:
float- default:
30.0- 参见:
客户端 f69981: 仅被授权用于一个文件系统:
- mon_client_hunt_interval
客户端每隔
N秒尝试一个新的监控器,直到它建立连接。- type:
float- default:
3.0
- mon_client_ping_interval
客户端每隔
Nseconds.- type:
float- default:
10.0
- mon_client_max_log_entries_per_message
监控器每条客户端消息生成的最大日志条目数。
- type:
int- default:
1000
- mon_client_bytes
允许的客户端消息数据量(以字节为单位)在内存中。
- type:
size- default:
100Mi
存储池设置
自版本 v0.94 起,支持池标志,允许或禁止对池进行更改。监控器还可以通过适当配置来禁止删除池。这种安全防护措施带来的不便远远被它防止了大量的意外池(以及因此)数据删除所抵消。
- mon_allow_pool_delete
监控器是否允许删除池,而不管池标志说什么?
- type:
bool- default:
false
- osd_pool_default_ec_fast_read
是否在池上打开快速读取。如果没有在创建时指定,它将用作新创建的纠删码池的默认设置。
fast_readis not specified at create time.- type:
bool- default:
false
- osd_pool_default_flag_hashpspool
在新池上设置 hashpspool(更好的哈希方案)标志
- type:
bool- default:
true
- osd_pool_default_flag_nodelete
Set the
nodelete在新池上设置此标志,这可以防止删除池。- type:
bool- default:
false
- osd_pool_default_flag_nopgchange
Set the
nopgchange在新池上设置此标志。不允许更改 PG 的数量。- type:
bool- default:
false
- osd_pool_default_flag_nosizechange
Set the
nosizechange在新池上设置此标志。不允许更改size大小。- type:
bool- default:
false
更多关于池标志的信息,请参见池值.
Miscellaneous
- mon_max_osd
允许集群中的最大 OSD 数量。
- type:
int- default:
10000
- mon_globalid_prealloc
为集群中的客户端和守护进程预分配的全球 ID 数量。
- type:
uint- default:
10000
- mon_subscribe_interval
订阅的刷新间隔(以秒为单位)。订阅机制可以获取集群映射和日志信息。
- type:
float- default:
1 day
- mon_stat_smooth_intervals
Ceph 将在最后
NPG 地图上平滑统计数据。- type:
uint- default:
6- min:
1
- mon_probe_timeout
监控器等待找到对等体以进行引导的秒数。
- type:
float- default:
2.0
- mon_daemon_bytes
元数据服务器和 OSD 消息的消息内存上限(以字节为单位)。
- type:
size- default:
400Mi
- mon_max_log_entries_per_event
每个事件的最大日志条目数。
- type:
int- default:
4096
- mon_osd_prime_pg_temp
启用或禁用当 OSD 回到集群时用以前的 OSD 初始化 PGMap。
outOSD comes back into the cluster. With thetrue设置此选项后,客户端将继续使用以前的 OSD,直到新的inOSDs 为 PG 配对。- type:
bool- default:
true
- mon_osd_prime_pg_temp_max_time
当 OSD 回到集群时,监控器应花费多少秒尝试初始化 PGMap。
- type:
float- default:
0.5
- mon_osd_prime_pg_temp_max_estimate
在并行初始化所有 PG 之前,每个 PG 上花费时间的最大估计。
- type:
float- default:
0.25
- mon_mds_skip_sanity
在 FSMap 上跳过安全断言(在存在 bug 的情况下我们仍然想继续)。如果 FSMap 脚本检查失败,监控器将终止,但我们可以通过启用此选项来禁用它。
- type:
bool- default:
false
- mon_max_mdsmap_epochs
一次提议中修剪的最大 mdsmap 时代数。
- type:
int- default:
500
- mon_config_key_max_entry_size
配置键条目的最大大小(以字节为单位)
- type:
size- default:
64Ki
- mon_scrub_interval
监控器多久通过比较存储的校验和与所有存储键的计算校验和来清理其存储(0 禁用。危险,请谨慎使用)。
- type:
secs- default:
1 day
- mon_scrub_max_keys
每次清理的最大键数。
- type:
int- default:
100
- mon_compact_on_start
在启动时压缩用作 Ceph 监控器存储的数据库。手动压缩有助于缩小监控器数据库并提高其性能,如果定期压缩不起作用。
ceph-monstart. A manual compaction helps to shrink the monitor database and improve the performance of it if the regular compaction fails to work.- type:
bool- default:
false
- mon_compact_on_bootstrap
在引导时压缩用作 Ceph 监控器存储的数据库。引导后,监控器相互探测以建立多数。如果监控器在加入多数之前超时,它将重新开始并再次引导。
- type:
bool- default:
false
- mon_compact_on_trim
在修剪其旧状态时压缩某个前缀(包括 paxos)。
- type:
bool- default:
true
- mon_cpu_threads
执行监控器 CPU 密集型工作的线程数。
- type:
int- default:
4
- mon_osd_mapping_pgs_per_chunk
我们按块计算从放置组到 OSD 的映射。此选项指定每个块中的放置组数量。
- type:
int- default:
4096
- mon_session_timeout
监控器将终止不活跃的会话,使其闲置超过此时间限制。
- type:
int- default:
5 minutes
- mon_osd_cache_size_min
osd 监控器缓存保留在内存中的最小字节数。
- type:
size- default:
128Mi
- mon_memory_target
OSD 监控器缓存和 KV 缓存的相关字节数,在启用缓存自动调整时保留在内存中。
- type:
size- default:
2Gi
- mon_memory_autotune
自动调整用于 OSD 监控器和 KV 数据库的缓存内存。
- type:
bool- default:
true
由 Ceph 基金会带给您
Ceph 文档是一个社区资源,由非盈利的 Ceph 基金会资助和托管Ceph Foundation. 如果您想支持这一点和我们的其他工作,请考虑加入现在加入.