注意
本文档适用于 Ceph 开发版本。
架构
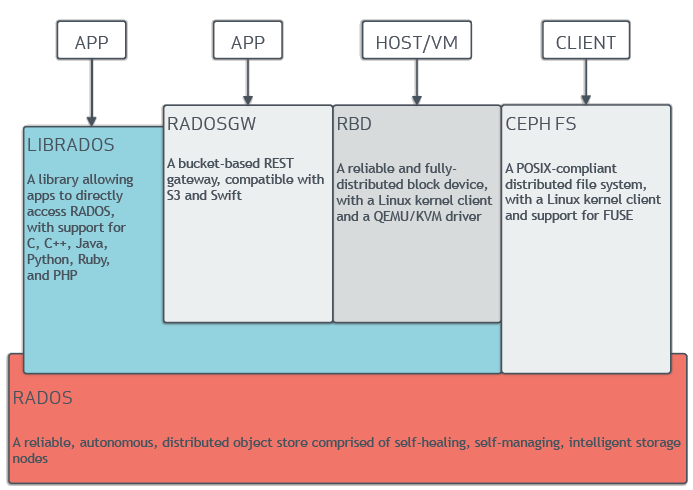
Ceph独特地交付对象、块和文件存储在一个Ceph 节点利用商用硬件和Ceph 存储集群适应大量节点,这些节点相互通信以动态复制和重新分配数据。
Ceph 存储集群
Ceph 提供了一个无限可扩展的Ceph 存储集群基于RADOS,这是一个可靠的,客户端提供数据。有关 RADOS 的简要解释,请参阅The RADOS Object Store”博客文章,有关RADOS - 可扩展的、可靠的的详尽解释。RADOS.
Ceph 存储集群由多种类型的守护进程组成:
Ceph 监视器维护集群地图的主副本,并将它们提供给 Ceph 客户端。Ceph 集群中存在多个监视器,这确保了如果监视器守护进程或其主机发生故障,则可用性。
Ceph OSD 守护进程检查自己的状态和其他 OSD 的状态,并向监视器报告。
Ceph 管理员充当监控、编排和插件模块的端点。
Ceph 元数据服务器 (MDS) 在使用 CephFS 提供文件服务时管理文件元数据。
存储集群客户端和Ceph OSD 守护进程使用 CRUSH 算法计算有关数据位置的信息。通过使用 CRUSH 算法,客户端和 OSD 避免被中央查找表瓶颈化。CRUSH 比较旧方法提供更好的数据管理机制,CRUSH 通过将工作分配到集群中的所有 OSD 守护进程和所有与之通信的客户端来实现大规模扩展。CRUSH 使用智能数据复制来确保弹性,这更适合超大规模存储。librados and a number of service interfaces built on top of
librados.
存储数据
The Ceph Storage Cluster receives data from Ceph Clients--whether it
comes through a Ceph 块设备, Ceph对象存储,Ceph 文件系统, or a custom implementation that you create by using
librados. The data received by the Ceph Storage Cluster is stored as RADOS
objects. Each object is stored on an Object Storage Device (this is
also called an “OSD”). Ceph OSDs control read, write, and replication
operations on storage drives. The default BlueStore back end stores objects
in a monolithic, database-like fashion.
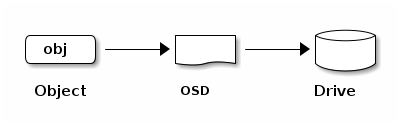
Ceph OSD Daemons store data as objects in a flat namespace. This means that objects are not stored in a hierarchy of directories. An object has an identifier, binary data, and metadata consisting of name/value pairs. Ceph Clients determine the semantics of the object data. For example, CephFS uses metadata to store file attributes such as the file owner, the created date, and the last modified date.

Note
An object ID is unique across the entire cluster, not just the local filesystem.
可扩展性和高可用性
In traditional architectures, clients talk to a centralized component. This centralized component might be a gateway, a broker, an API, or a facade. A centralized component of this kind acts as a single point of entry to a complex subsystem. Architectures that rely upon such a centralized component have a single point of failure and incur limits to performance and scalability. If the centralized component goes down, the whole system becomes unavailable.
Ceph eliminates this centralized component. This enables clients to interact with Ceph OSDs directly. Ceph OSDs create object replicas on other Ceph Nodes to ensure data safety and high availability. Ceph also uses a cluster of monitors to ensure high availability. To eliminate centralization, Ceph uses an algorithm called CRUSH.
CRUSH 简介
Ceph Clients and Ceph OSD Daemons both use the CRUSH algorithm to compute information about object location instead of relying upon a central lookup table. CRUSH provides a better data management mechanism than do older approaches, and CRUSH enables massive scale by distributing the work to all the OSD daemons in the cluster and all the clients that communicate with them. CRUSH uses intelligent data replication to ensure resiliency, which is better suited to hyper-scale storage. The following sections provide additional details on how CRUSH works. For an in-depth, academic discussion of CRUSH, see CRUSH - 受控的、可扩展的、去中心化的复制数据放置.
集群地图
为了使 Ceph 集群能够正常运行,Ceph 客户端和 Ceph OSD 必须拥有有关集群拓扑的当前信息。当前信息存储在“集群地图”中,实际上是一个包含五个地图的集合。构成集群地图的五个地图是:
监视器地图:包含集群
fsid,每个监视器的位置、名称、地址和 TCP 端口。监视器地图指定了当前时代,监视器地图的创建时间和监视器地图的最后修改时间。要查看监视器地图,请运行ceph mon dump.OSD 地图:包含集群
fsid,OSD 地图的创建时间、OSD 地图的最后修改时间、池列表、副本大小列表、PG 列表和 OSD 列表及其状态(例如,up,in)。要查看 OSD 地图,请运行ceph osd dump.PG 地图:包含 PG 版本、时间戳、最后 OSD 地图时代、完整比率以及每个放置组的位置详细信息。这包括 PG ID、上集,行动集,PG 的状态(例如,
active + clean)以及每个池的数据使用统计信息。CRUSH 地图:包含存储设备列表、故障域层次结构(例如,
device,host,rack,row,room)以及存储数据时遍历层次结构的规则。要查看 CRUSH 地图,请运行ceph osd getcrushmap -o {filename}然后通过运行crushtool -d {comp-crushmap-filename} -o {decomp-crushmap-filename}进行反编译。cat查看反编译的地图。MDS 地图:包含当前 MDS 地图时代、地图创建时间以及最后更改时间。它还包含用于存储元数据的池、元数据服务器列表以及哪些元数据服务器是
up和in。要查看 MDS 地图,请执行ceph fs dump.
每个地图维护其操作状态的历史记录。Ceph 监视器维护集群地图的主副本。此主副本包括集群成员、集群状态、集群更改以及记录 Ceph 存储集群整体健康状况的信息。
高可用性监视器
Ceph 客户端必须联系 Ceph 监视器并获取集群地图的当前副本,以便从 Ceph 集群读取数据或向 Ceph 集群写入数据。
Ceph 集群可以仅使用单个监视器正常运行,但仅使用单个监视器的 Ceph 集群有一个单点故障:如果监视器发生故障,Ceph 客户端将无法从集群读取数据或向集群写入数据。
Ceph 利用一组监视器来提高可靠性和容错能力。然而,当使用一组监视器时,集群中的一个或多个监视器可能会由于延迟或其他故障而落后。Ceph 通过要求多个监视器实例就集群状态达成一致来减轻这些负面影响。为了在监视器之间就集群状态达成共识,Ceph 使用Paxos算法和多数监视器(例如,在仅包含一个监视器的集群中有一个,包含三个监视器的集群中有两个,包含五个监视器的集群中有三个,包含六个监视器的集群中有四个,等等)。
请参阅监视器配置参考了解如何配置监视器。
高可用性认证
The cephxCeph 使用认证系统来认证用户和守护进程,并防止中间人攻击。
Note
The cephx协议不解决传输中的数据加密(例如,SSL/TLS)或静态加密。
cephx使用共享密钥进行认证。这意味着客户端和监视器集群都保存客户端的密钥副本。2315a9: 协议使每一方都能向对方证明它拥有密钥副本而无需泄露它。这提供了相互认证,并允许集群确认(1)用户拥有密钥,(2)用户可以确信集群拥有密钥副本。
The cephx protocol makes it possible for each party to prove to the other
that it has a copy of the key without revealing it. This provides mutual
authentication and allows the cluster to confirm (1) that the user has the
secret key and (2) that the user can be confident that the cluster has a copy
of the secret key.
如在可扩展性和高可用性中所述,Ceph 在客户端和 Ceph 对象存储之间没有任何中央界面。通过避免这种中央界面,Ceph 避免了这种中央界面带来的瓶颈。但是,这意味着客户端必须直接与 OSD 交互。Ceph 客户端和 OSD 之间的直接交互需要认证连接。该cephx认证系统建立并维持这些认证连接。
The cephx协议的操作方式类似于Kerberos.
用户调用 Ceph 客户端联系监视器。与 Kerberos 不同,每个监视器都可以认证用户并分发密钥,这意味着在使用cephx时没有单点故障,也没有瓶颈。监视器返回一个类似于 Kerberos 门票的认证数据结构。此认证数据结构包含用于获取 Ceph 服务的会话密钥。会话密钥本身使用用户的永久密钥加密,这意味着只有用户才能请求 Ceph 监视器的服务。然后,客户端使用会话密钥向监视器请求服务,监视器向客户端提供针对实际处理数据的 OSD 的认证门票。Ceph 监视器和 OSD 共享一个密钥,这意味着客户端可以使用监视器提供的门票来认证集群中的任何 OSD 或元数据服务器。a7e7dd: 门票像 Kerberos 门票一样
Like Kerberos tickets, cephx tickets expire. An attacker cannot use an
expired ticket or session key that has been obtained surreptitiously. This form
of authentication prevents attackers who have access to the communications
medium from creating bogus messages under another user’s identity and prevents
attackers from altering another user’s legitimate messages, as long as the
user’s secret key is not divulged before it expires.
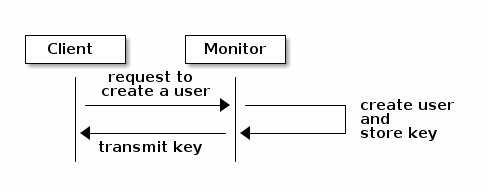
管理员在使用cephx之前必须设置用户。在以下图中,client.admin用户从命令行调用ceph auth get-or-create-key生成用户名和密钥。Ceph 的auth子系统生成用户名和密钥,将副本保存在监视器(s)上,并将用户的密钥传回给client.admin用户。这意味着客户端和监视器共享一个密钥。
Note
The client.admin用户必须以安全的方式向用户提供用户 ID 和密钥。
客户端如何向监视器进行认证的方法如下。客户端将用户名传递给监视器。监视器生成一个使用与username关联的密钥加密的会话密钥。监视器将加密的门票传输到客户端。客户端使用共享密钥解密有效负载。会话密钥标识用户,此标识操作将持续整个会话。客户端请求用户的门票,门票使用会话密钥签名。监视器生成门票,并使用用户的密钥对其进行加密。加密的门票传输到客户端。客户端解密门票并使用它来签名对 OSD 和集群中的元数据服务器的请求。
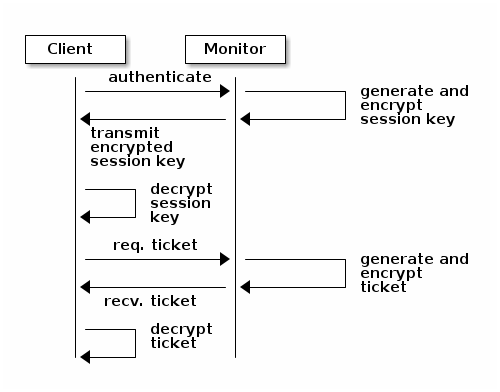
The cephx协议认证客户端和 Ceph 守护进程之间正在进行的通信。初始认证后,客户端和守护进程之间发送的每条消息都使用可由监视器、OSD 和元数据守护进程验证的门票进行签名。此门票是使用客户端和守护进程之间共享的密钥进行验证的。
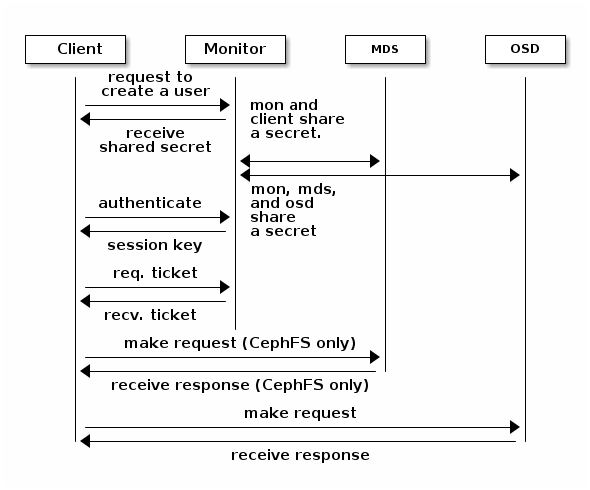
这种认证仅保护 Ceph 客户端和 Ceph 守护进程之间的连接。认证没有扩展到 Ceph 客户端。如果用户从远程主机访问 Ceph 客户端,cephx 认证不会应用于用户主机和客户端主机之间的连接。
请参阅CephX 配置参考了解更多配置细节。
请参阅User Management了解更多关于用户管理的信息。
请参阅Cephx 认证协议的详细描述了解授权和认证之间的区别,以及cephx门票和会话密钥设置的逐步说明。
Smart Daemons Enable Hyperscale
许多存储集群的一个功能是集中界面,它跟踪客户端被允许访问的节点。这种集中式架构通过双重调度向客户端提供服务。在 petabyte 到 exabyte 的规模下,这种双重调度是一个显著的瓶颈。
Ceph 消除了这个瓶颈:Ceph 的 OSD 守护进程和 Ceph 客户端都是集群感知的。像 Ceph 客户端一样,每个 Ceph OSD 守护进程都意识到集群中的其他 Ceph OSD 守护进程。这使得 Ceph OSD 守护进程能够直接与其他 Ceph OSD 守护进程和 Ceph 监视器直接交互。集群感知使得 Ceph 客户端能够直接与 Ceph OSD 守护进程交互。
由于 Ceph 客户端、Ceph 监视器和 Ceph OSD 守护进程直接交互,Ceph OSD 守护进程可以利用 Ceph 集群中节点的聚合 CPU 和 RAM 资源。这意味着 Ceph 集群可以轻松执行中央界面会难以执行的任务。Ceph 节点利用更大集群的计算能力提供了几个好处:
OSDs 直接服务客户端:网络设备只能支持有限数量的并发连接。因为 Ceph 客户端直接联系 Ceph OSD 守护进程而不首先连接到中央界面,所以相对于包含中央界面的存储冗余策略,Ceph 享有改进的性能和增加的系统容量。Ceph 客户端仅在需要时维护会话,并且只与特定的 Ceph OSD 守护进程维护这些会话,而不是与中央界面。
OSD 成员资格和状态: 当 Ceph OSD 守护进程加入集群时,它们报告其状态。在最底层,Ceph OSD 守护进程的状态是
up或down:这反映了 Ceph OSD 守护进程是否正在运行并能够服务 Ceph 客户端请求。如果 Ceph OSD 守护进程是down和inCeph 存储集群,则此状态可能表示 Ceph OSD 守护进程发生故障。如果 Ceph OSD 守护进程由于崩溃而未运行,则 Ceph OSD 守护进程无法通知 Ceph 监视器它down。OSDs 定期向 Ceph 监视器发送消息(在 Luminous 之前的版本中,这是通过MPGStats完成的,从 Luminous 版本开始,这是通过MOSDBeacon完成的)。如果 Ceph 监视器在可配置的时间段后没有收到此类消息,则它们会标记 OSDdown。这种机制是一种安全机制。通常,Ceph OSD 守护进程确定相邻 OSD 是否down并向 Ceph 监视器报告。这有助于使 Ceph 监视器成为轻量级进程。请参阅监控 OSDs和心跳以获取更多详细信息。数据擦拭:为了维护数据一致性和清洁,Ceph OSD 守护进程擦拭 RADOS 对象。Ceph OSD 守护进程将自己的本地对象的元数据与其存储在其他 OSD 上的对象的副本的元数据进行比较。擦拭(通常每天执行)捕获 OSD 错误或文件系统错误,通常是由于硬件问题。OSDs 还通过将对象中的数据逐位与它们的校验和进行比较执行更深入的擦拭。更深入的擦拭(默认每周执行)找到硬盘上的坏块,这些坏块在轻量级擦拭中无法检测到。Data Scrubbing了解有关配置擦拭的详细信息。
复制:数据复制涉及 Ceph 客户端和 Ceph OSD 守护进程之间的协作。Ceph OSD 守护进程使用 CRUSH 算法来确定对象副本的存储位置。Ceph 客户端使用 CRUSH 算法来确定对象的存储位置,然后对象映射到池,然后客户端咨询 CRUSH 地图以识别放置组的主 OSD。da7d08: 在识别目标放置组后,客户端将对象写入识别的放置组的主 OSD。主 OSD 然后咨询其自己的 CRUSH 地图副本以识别次级 OSD,将对象复制到次级 OSD 的放置组中,确认对象已成功存储在次级 OSD 中,并向客户端报告对象已成功存储。我们称这些复制操作为
After identifying the target placement group, the client writes the object to the identified placement group’s primary OSD. The primary OSD then consults its own copy of the CRUSH map to identify secondary OSDS, replicates the object to the placement groups in those secondary OSDs, confirms that the object was stored successfully in the secondary OSDs, and reports to the client that the object was stored successfully. We call these replication operations
subops.
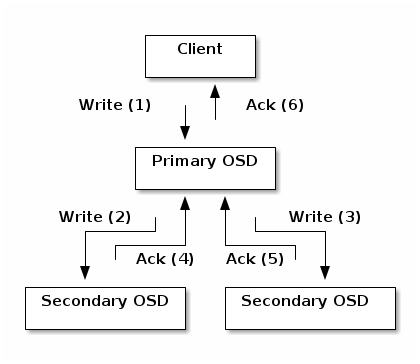
通过执行此数据复制,Ceph OSD 守护进程减轻了 Ceph 客户端及其网络接口复制数据的负担。
动态集群管理
在可扩展性和高可用性部分,我们解释了 Ceph 如何使用 CRUSH、集群拓扑和智能守护进程来扩展并维护高可用性。Ceph 设计的关键是自主的、自我修复的、智能的 Ceph OSD 守护进程。让我们更深入地了解 CRUSH 如何工作以使现代云存储基础设施能够放置数据、再平衡集群、自适应放置和平衡数据以及从故障中恢复。
关于池
Ceph 存储系统支持“池”的概念,它们是存储对象的逻辑分区。
Ceph 客户端从 Ceph 监视器检索集群地图,并将 RADOS 对象写入池。Ceph 将数据放置在池中的方式由池的size或副本数量、CRUSH 规则和池中的放置组数量决定。
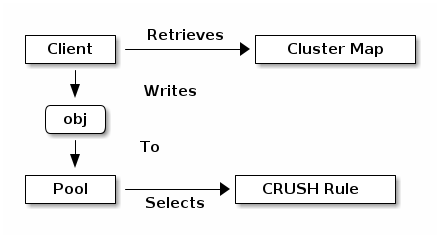
池设置以下至少一个参数:
对象的所有权/访问
放置组的数量,以及
要使用的 CRUSH 规则。
请参阅设置池值 for details.
将 PG 映射到 OSD
每个池都有其内部的放置组 (PG) 数量。CRUSH 动态地将 PG 映射到 OSD。当 Ceph 客户端存储对象时,CRUSH 将每个 RADOS 对象映射到 PG。
RADOS 对象到 PG 的映射在 Ceph OSD 守护进程和 Ceph 客户端之间实现了一个抽象和间接层。Ceph 存储集群必须能够在内部拓扑发生变化时(或缩小)自适应地增长(或缩小)并重新分配数据。
如果 Ceph 客户端“知道”哪些 Ceph OSD 守护进程正在存储哪些对象,则 Ceph 客户端和 Ceph OSD 守护进程之间存在紧密耦合。但是,Ceph 避免了任何这种紧密耦合。相反,CRUSH 算法将每个 RADOS 对象映射到放置组,然后将每个放置组映射到一个或多个 Ceph OSD 守护进程。这种“间接层”允许 Ceph 在新的 Ceph OSD 守护进程及其底层 OSD 设备上线时动态再平衡。
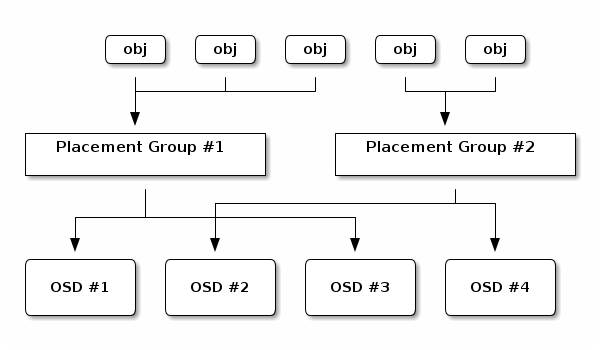
客户端使用其集群地图副本和 CRUSH 算法来计算读取或写入特定对象时将使用的 OSD。
计算 PG ID
当 Ceph 客户端绑定到 Ceph 监视器时,它检索集群地图的最新版本。当客户端配备了集群地图副本时,它知道集群中的所有监视器、OSD 和元数据服务器。然而,即使配备了最新版本的集群地图副本,客户端也不知道对象的位置。对象位置必须计算。
Object locations must be computed.
客户端只需要对象 ID 和池的名称即可计算对象位置。
Ceph 将数据存储在命名的池(例如,“liverpool”)中。当客户端存储命名对象(例如,“john”,“paul”,“george”或“ringo”)时,它使用对象名称、哈希码、池中的 PG 数量和池名称计算放置组。Ceph 客户端使用以下步骤计算 PG ID。
客户端输入池名称和对象 ID。(例如:pool = “liverpool” 和 object-id = “john”)
Ceph 哈希对象 ID。
Ceph 计算哈希,模 PG 数量(例如:
58),以获得 PG ID。Ceph 使用池名称检索池 ID:(例如:“liverpool” = adb56d: Ceph 将池 ID 前置到 PG ID(例如:
4)Ceph prepends the pool ID to the PG ID (for example:
4.58).
它比通过聊天会话执行对象位置查询更快地计算对象位置。60b651: 算法允许客户端计算对象预期存储的位置,并使客户端能够联系主 OSD 以存储或检索对象。CRUSH algorithm allows a client to compute where objects are expected to be stored, and enables the client to contact the primary OSD to store or retrieve the objects.
对等和集合
在前面的部分中,我们提到 Ceph OSD 守护进程检查每个其他 OSD 的心跳并向 Ceph 监视器报告。Ceph OSD 守护进程也进行“对等”,这是将存储放置组 (PG) 的所有 OSD 都带入关于该 PG 中所有 RADOS 对象(及其元数据)的状态达成一致的过程。Ceph OSD 守护进程向 Ceph 监视器报告对等失败。对等问题通常自行解决;但是,如果问题仍然存在,您可能需要参考故障排除对等失败部分。
Note
同意集群状态的 PG 不一定拥有当前数据。
Ceph 存储集群的设计是为了至少存储对象的两份副本(即,size = 2),这是数据安全的最小要求。为了高可用性,Ceph 存储集群应存储对象的多于两份副本(即,size = 3和min size = 2),以便它可以在维护数据安全的情况下继续运行。degraded state while maintaining data safety.
警告
虽然我们在这里说 R2(具有两份副本的复制)是数据安全的最小要求,但 R3(具有三份副本的复制)是推荐的。在足够长的时间线内,使用 R2 策略存储的数据将会丢失。
如在Smart Daemons Enable Hyperscale图中解释的那样,我们不具体命名 Ceph OSD 守护进程(例如,osd.0, osd.1,主要, Secondary,等等。按惯例,主要是行动集中的第一个 OSD,负责为每个放置组(它作为主要一起使用。该主要是唯一OSD,则它接受客户端发起的对象写入。
负责放置组的 OSD 集合称为行动集。术语“行动集”可以指当前负责放置组的 Ceph OSD 守护进程,也可以指自某个时代起负责特定放置组的 Ceph OSD 守护进程。
作为行动集的一部分的 Ceph OSD 守护进程可能不总是up。当行动集是up中的 OSD 发生故障时,它属于上集。上集上集是一个重要的区别,因为当 OSD 发生故障时,Ceph 可以将 PG 重新映射到其他 Ceph OSD 守护进程。
Note
考虑一个假设行动集对于包含osd.25, osd.32和osd.61的 PG。第一个 OSD (osd.25) 是主要。如果该 OSD 发生故障,则次要 (osd.32) 成为主要, and osd.25是移除的上集.
再平衡
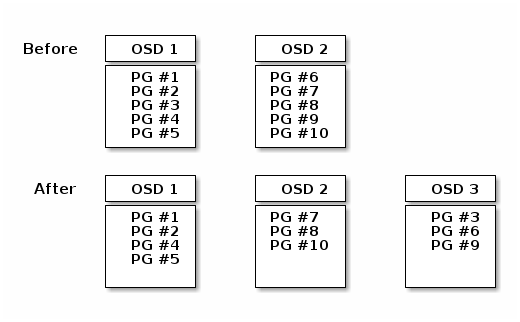
当您向 Ceph 存储集群添加 Ceph OSD 守护进程时,集群地图会更新新的 OSD。回到计算 PG ID,这会改变集群地图。因此,它会改变对象放置,因为它改变了计算的输入。以下图描绘了再平衡过程(尽管它相当粗糙,因为对于大型集群来说影响要小得多),其中一些但不是所有 PG 都从现有的 OSD(OSD 1 和 OSD 5)迁移到新的 OSD(OSD 3)。即使再平衡,CRUSH 也是稳定的。许多放置组保留其原始配置,每个 OSD 都获得一些额外的容量,因此再平衡完成后,新 OSD 上没有负载尖峰。
数据一致性
作为维护数据一致性和清洁的一部分,Ceph OSD 也擦拭放置组内的对象。也就是说,Ceph OSD 比较自己本地对象的元数据与其他 OSD 上存储的对象副本的元数据。擦拭(通常每天执行)捕获 OSD 错误或文件系统错误,通常是由于硬件问题。OSDs 还通过将对象中的数据逐位与它们的校验和进行比较执行更深入的擦拭。更深入的擦拭(默认每周执行)找到硬盘上的坏块,这些坏块在轻量级擦拭中无法检测到。
请参阅Data Scrubbing了解有关配置擦拭的详细信息。
消息编码
An erasure coded pool stores each object as K+M chunks. It is divided into
K data chunks and M coding chunks. The pool is configured to have a size
of K+M so that each chunk is stored in an OSD in the acting set. The rank of
the chunk is stored as an attribute of the object.
For instance an erasure coded pool can be created to use five OSDs (K+M = 5) and
sustain the loss of two of them (M = 2). Data may be unavailable until (K+1)
shards are restored.
读取和写入编码块
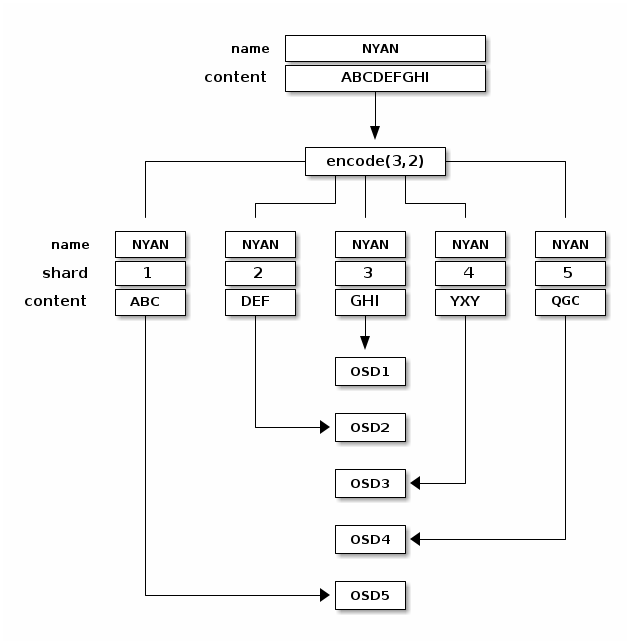
When the object NYAN containing ABCDEFGHI is written to the pool, the erasure
encoding function splits the content into three data chunks simply by dividing
the content in three: the first contains ABC, the second DEF and the
last GHI. The content will be padded if the content length is not a multiple
of K. The function also creates two coding chunks: the fourth with YXY
and the fifth with QGC. Each chunk is stored in an OSD in the acting set.
The chunks are stored in objects that have the same name (NYAN) but reside
on different OSDs. The order in which the chunks were created must be preserved
and is stored as an attribute of the object (shard_t), in addition to its
name. Chunk 1 contains ABC and is stored on OSD5 while chunk 4 contains
YXY and is stored on OSD3.
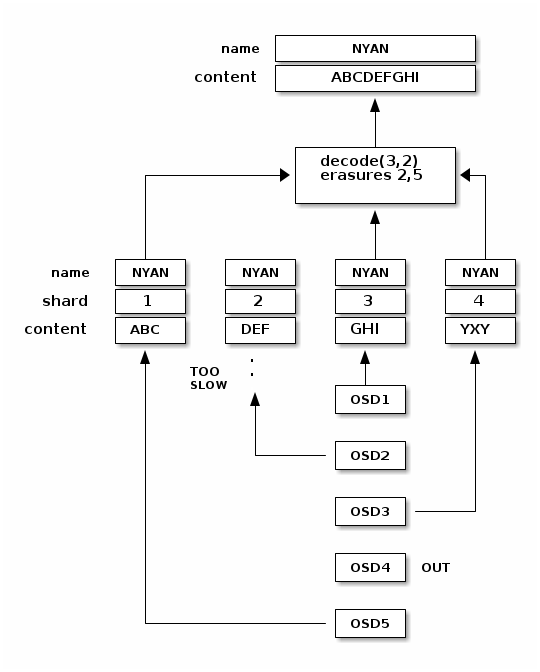
When the object NYAN is read from the erasure coded pool, the decoding
function reads three chunks: chunk 1 containing ABC, chunk 3 containing
GHI and chunk 4 containing YXY. Then, it rebuilds the original content
of the object ABCDEFGHI. The decoding function is informed that the chunks 2
and 5 are missing (they are called ‘erasures’). The chunk 5 could not be read
because the OSD4 is out. The decoding function can be called as soon as
three chunks are read: OSD2 was the slowest and its chunk was not taken into
account.
中断的完整写入
In an erasure coded pool, the primary OSD in the up set receives all write
operations. It is responsible for encoding the payload into K+M chunks and
sends them to the other OSDs. It is also responsible for maintaining an
authoritative version of the placement group logs.
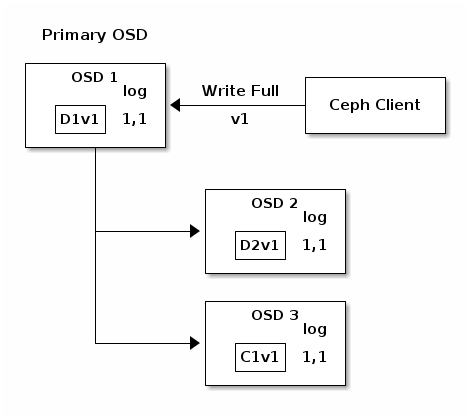
In the following diagram, an erasure coded placement group has been created with
K = 2, M = 1 and is supported by three OSDs, two for K and one for
M. The acting set of the placement group is made of OSD 1, OSD 2和OSD 3. An object has been encoded and stored in the OSDs : the chunk
D1v1 (i.e. Data chunk number 1, version 1) is on OSD 1, D2v1onOSD 2和C1v1 (i.e. Coding chunk number 1, version 1) on OSD 3. The
placement group logs on each OSD are identical (i.e. 1,1 for epoch 1,
version 1).
OSD 1 is the primary and receives a WRITE FULL from a client, which
means the payload is to replace the object entirely instead of overwriting a
portion of it. Version 2 (v2) of the object is created to override version 1
(v1). OSD 1 encodes the payload into three chunks: D1v2 (i.e. Data
chunk number 1 version 2) will be on OSD 1, D2v2onOSD 2和C1v2 (i.e. Coding chunk number 1 version 2) on OSD 3. Each chunk is sent
to the target OSD, including the primary OSD which is responsible for storing
chunks in addition to handling write operations and maintaining an authoritative
version of the placement group logs. When an OSD receives the message
instructing it to write the chunk, it also creates a new entry in the placement
group logs to reflect the change. For instance, as soon as OSD 3 stores
C1v2, it adds the entry 1,2 ( i.e. epoch 1, version 2 ) to its logs.
Because the OSDs work asynchronously, some chunks may still be in flight ( such
as D2v2 ) while others are acknowledged and persisted to storage drives
(such as C1v1和D1v1).
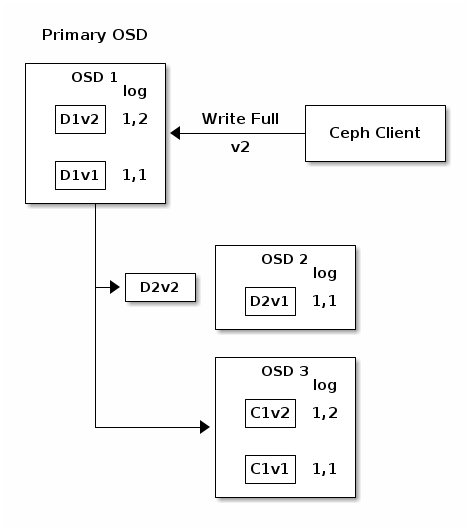
If all goes well, the chunks are acknowledged on each OSD in the acting set and
the logs’ last_complete pointer can move from 1,1to1,2.
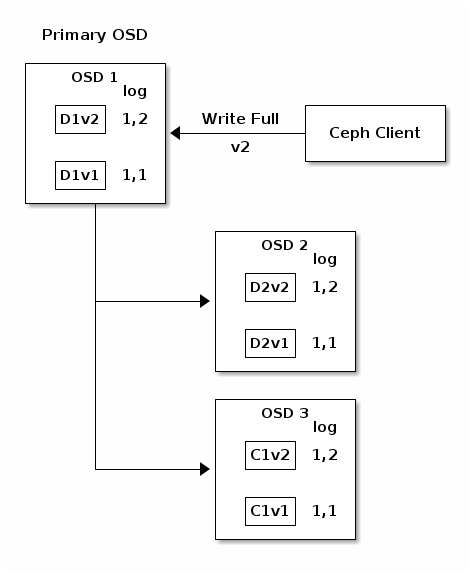
Finally, the files used to store the chunks of the previous version of the
object can be removed: D1v1onOSD 1, D2v1onOSD 2和C1v1onOSD 3.
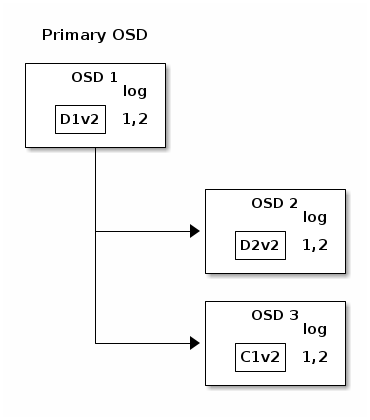
But accidents happen. If OSD 1 goes down while D2v2 is still in flight,
the object’s version 2 is partially written: OSD 3 has one chunk but that is
not enough to recover. It lost two chunks: D1v2和D2v2 and the
erasure coding parameters K = 2, M = 1 require that at least two chunks are
available to rebuild the third. OSD 4 becomes the new primary and finds that
the last_complete log entry (i.e., all objects before this entry were known
to be available on all OSDs in the previous acting set ) is 1,1 and that
will be the head of the new authoritative log.
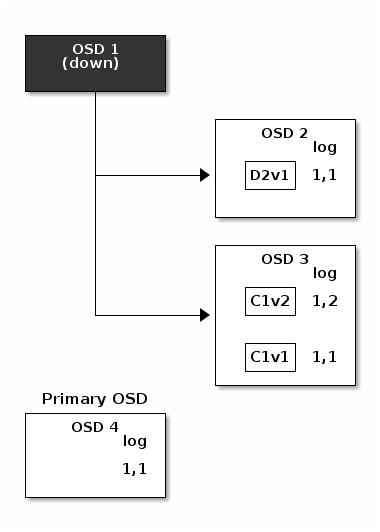
The log entry 1,2 found on OSD 3 is divergent from the new authoritative log
provided by OSD 4: it is discarded and the file containing the C1v2
chunk is removed. The D1v1 chunk is rebuilt with the decode function of
the erasure coding library during scrubbing and stored on the new primary
OSD 4.
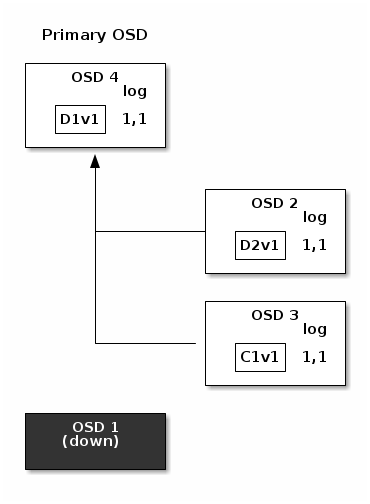
请参阅Erasure Code Notes以获取更多详细信息。
缓存分层
Note
Cache tiering is deprecated in Reef.
A cache tier provides Ceph Clients with better I/O performance for a subset of the data stored in a backing storage tier. Cache tiering involves creating a pool of relatively fast/expensive storage devices (e.g., solid state drives) configured to act as a cache tier, and a backing pool of either erasure-coded or relatively slower/cheaper devices configured to act as an economical storage tier. The Ceph objecter handles where to place the objects and the tiering agent determines when to flush objects from the cache to the backing storage tier. So the cache tier and the backing storage tier are completely transparent to Ceph clients.
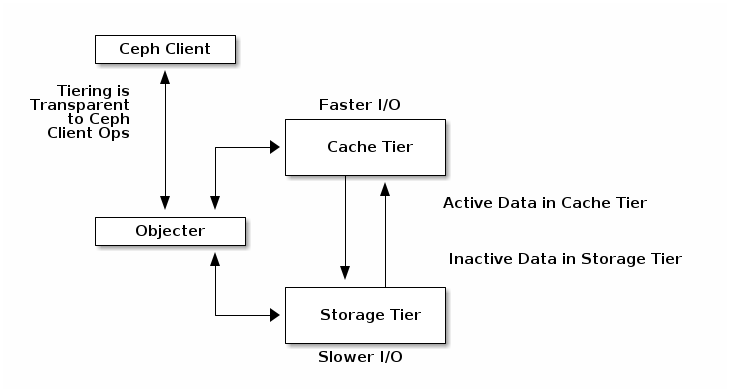
请参阅缓存分层 for additional details. Note that Cache Tiers can be tricky and their use is now discouraged.
扩展 Ceph
You can extend Ceph by creating shared object classes called ‘Ceph Classes’.
Ceph loads .so classes stored in the osd class dir directory dynamically
(i.e., $libdir/rados-classes by default). When you implement a class, you
can create new object methods that have the ability to call the native methods
in the Ceph Object Store, or other class methods you incorporate via libraries
or create yourself.
On writes, Ceph Classes can call native or class methods, perform any series of operations on the inbound data and generate a resulting write transaction that Ceph will apply atomically.
On reads, Ceph Classes can call native or class methods, perform any series of operations on the outbound data and return the data to the client.
请参阅src/objclass/objclass.h, src/fooclass.cc和src/barclass for
exemplary implementations.
总结
Ceph Storage Clusters are dynamic--like a living organism. Although many storage appliances do not fully utilize the CPU and RAM of a typical commodity server, Ceph does. From heartbeats, to peering, to rebalancing the cluster or recovering from faults, Ceph offloads work from clients (and from a centralized gateway which doesn’t exist in the Ceph architecture) and uses the computing power of the OSDs to perform the work. When referring to 硬件推荐和Network Config Reference, be cognizant of the foregoing concepts to understand how Ceph utilizes computing resources.
Ceph 协议
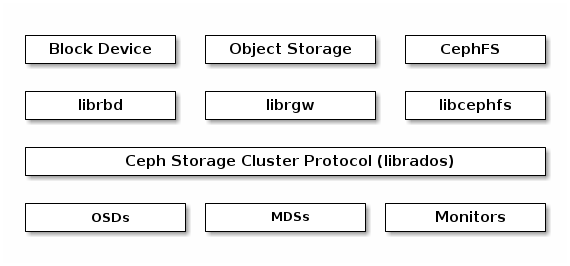
Ceph Clients use the native protocol for interacting with the Ceph Storage
Cluster. Ceph packages this functionality into the librados library so that
you can create your own custom Ceph Clients. The following diagram depicts the
basic architecture.
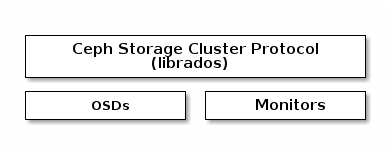
本地协议和librados
Modern applications need a simple object storage interface with asynchronous communication capability. The Ceph Storage Cluster provides a simple object storage interface with asynchronous communication capability. The interface provides direct, parallel access to objects throughout the cluster.
Pool Operations
Snapshots and Copy-on-write Cloning
Read/Write Objects - Create or Remove - Entire Object or Byte Range - Append or Truncate
Create/Set/Get/Remove XATTRs
Create/Set/Get/Remove Key/Value Pairs
Compound operations and dual-ack semantics
Object Classes
对象监视/通知
A client can register a persistent interest with an object and keep a session to the primary OSD open. The client can send a notification message and a payload to all watchers and receive notification when the watchers receive the notification. This enables a client to use any object as a synchronization/communication channel.
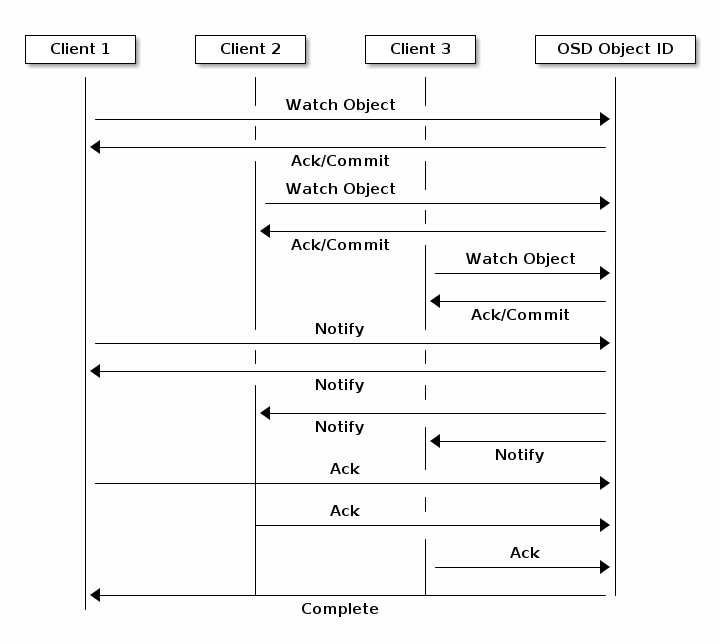
数据条带化
Storage devices have throughput limitations, which impact performance and scalability. So storage systems often support striping--storing sequential pieces of information across multiple storage devices--to increase throughput and performance. The most common form of data striping comes from RAID. The RAID type most similar to Ceph’s striping is RAID 0, or a ‘striped volume’. Ceph’s striping offers the throughput of RAID 0 striping, the reliability of n-way RAID mirroring and faster recovery.
Ceph provides three types of clients: Ceph Block Device, Ceph File System, and Ceph Object Storage. A Ceph Client converts its data from the representation format it provides to its users (a block device image, RESTful objects, CephFS filesystem directories) into objects for storage in the Ceph Storage Cluster.
提示
The objects Ceph stores in the Ceph Storage Cluster are not striped.
Ceph Object Storage, Ceph Block Device, and the Ceph File System stripe their
data over multiple Ceph Storage Cluster objects. Ceph Clients that write
directly to the Ceph Storage Cluster via librados must perform the
striping (and parallel I/O) for themselves to obtain these benefits.
The simplest Ceph striping format involves a stripe count of 1 object. Ceph Clients write stripe units to a Ceph Storage Cluster object until the object is at its maximum capacity, and then create another object for additional stripes of data. The simplest form of striping may be sufficient for small block device images, S3 or Swift objects and CephFS files. However, this simple form doesn’t take maximum advantage of Ceph’s ability to distribute data across placement groups, and consequently doesn’t improve performance very much. The following diagram depicts the simplest form of striping:
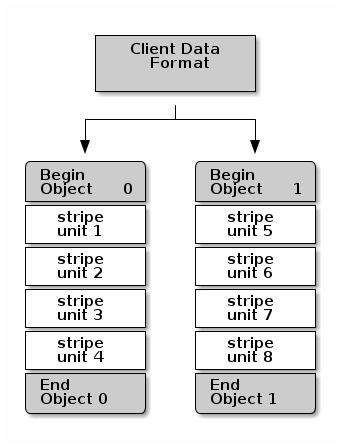
If you anticipate large images sizes, large S3 or Swift objects (e.g., video), or large CephFS directories, you may see considerable read/write performance improvements by striping client data over multiple objects within an object set. Significant write performance occurs when the client writes the stripe units to their corresponding objects in parallel. Since objects get mapped to different placement groups and further mapped to different OSDs, each write occurs in parallel at the maximum write speed. A write to a single drive would be limited by the head movement (e.g. 6ms per seek) and bandwidth of that one device (e.g. 100MB/s). By spreading that write over multiple objects (which map to different placement groups and OSDs) Ceph can reduce the number of seeks per drive and combine the throughput of multiple drives to achieve much faster write (or read) speeds.
Note
Striping is independent of object replicas. Since CRUSH replicates objects across OSDs, stripes get replicated automatically.
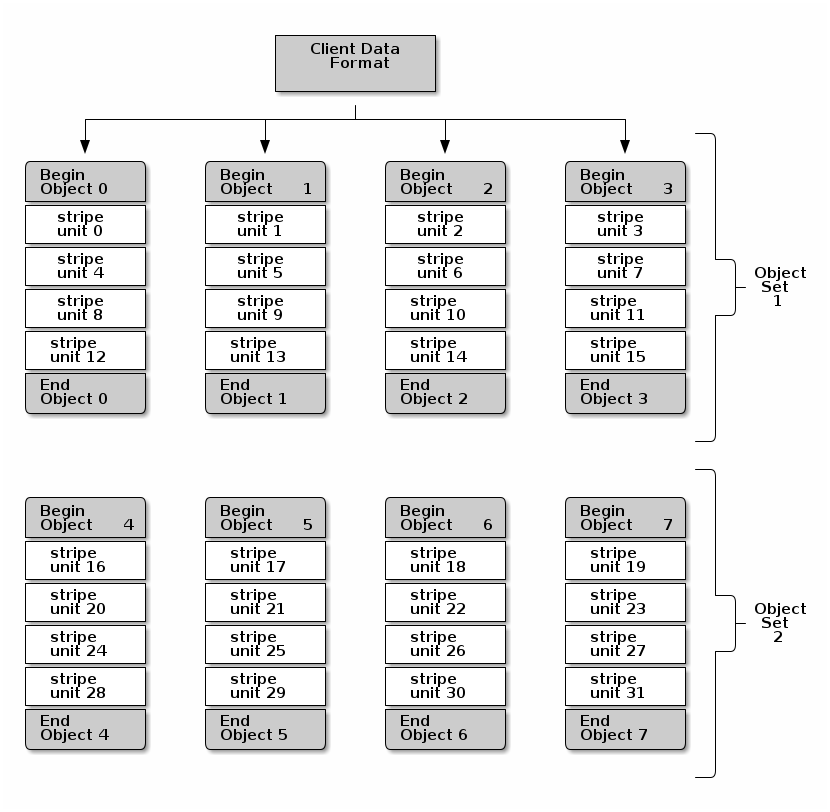
In the following diagram, client data gets striped across an object set
(object set 1 in the following diagram) consisting of 4 objects, where the
first stripe unit is stripe unit 0 in object 0, and the fourth stripe
unit is stripe unit 3 in object 3. After writing the fourth stripe, the
client determines if the object set is full. If the object set is not full, the
client begins writing a stripe to the first object again (object 0 in the
following diagram). If the object set is full, the client creates a new object
set (object set 2 in the following diagram), and begins writing to the first
stripe (stripe unit 16) in the first object in the new object set (object
4 in the diagram below).
Three important variables determine how Ceph stripes data:
Object Size: Objects in the Ceph Storage Cluster have a maximum configurable size (e.g., 2MB, 4MB, etc.). The object size should be large enough to accommodate many stripe units, and should be a multiple of the stripe unit.
Stripe Width: Stripes have a configurable unit size (e.g., 64kb). The Ceph Client divides the data it will write to objects into equally sized stripe units, except for the last stripe unit. A stripe width, should be a fraction of the Object Size so that an object may contain many stripe units.
Stripe Count: The Ceph Client writes a sequence of stripe units over a series of objects determined by the stripe count. The series of objects is called an object set. After the Ceph Client writes to the last object in the object set, it returns to the first object in the object set.
重要
Test the performance of your striping configuration before putting your cluster into production. You CANNOT change these striping parameters after you stripe the data and write it to objects.
Once the Ceph Client has striped data to stripe units and mapped the stripe units to objects, Ceph’s CRUSH algorithm maps the objects to placement groups, and the placement groups to Ceph OSD Daemons before the objects are stored as files on a storage drive.
Note
Since a client writes to a single pool, all data striped into objects get mapped to placement groups in the same pool. So they use the same CRUSH map and the same access controls.
Ceph 客户端
Ceph Clients include a number of service interfaces. These include:
Block Devices: The Ceph 块设备 (a.k.a., RBD) service provides resizable, thin-provisioned block devices that can be snapshotted and cloned. Ceph stripes a block device across the cluster for high performance. Ceph supports both kernel objects (KO) and a QEMU hypervisor that uses
librbddirectly--avoiding the kernel object overhead for virtualized systems.Object Storage: The Ceph对象存储 (a.k.a., RGW) service provides RESTful APIs with interfaces that are compatible with Amazon S3 and OpenStack Swift.
Filesystem: The Ceph 文件系统 (CephFS) service provides a POSIX compliant filesystem usable with
mountor as a filesystem in user space (FUSE).
Ceph can run additional instances of OSDs, MDSs, and monitors for scalability and high availability. The following diagram depicts the high-level architecture.
Ceph对象存储
The Ceph Object Storage daemon, radosgw, is a FastCGI service that provides
a RESTful HTTP API to store objects and metadata. It layers on top of the Ceph
Storage Cluster with its own data formats, and maintains its own user database,
authentication, and access control. The RADOS Gateway uses a unified namespace,
which means you can use either the OpenStack Swift-compatible API or the Amazon
S3-compatible API. For example, you can write data using the S3-compatible API
with one application and then read data using the Swift-compatible API with
another application.
请参阅Ceph 对象网关 for details.
Ceph 块设备
A Ceph Block Device stripes a block device image over multiple objects in the
Ceph Storage Cluster, where each object gets mapped to a placement group and
distributed, and the placement groups are spread across separate ceph-osd
daemons throughout the cluster.
重要
Striping allows RBD block devices to perform better than a single server could!
Thin-provisioned snapshottable Ceph Block Devices are an attractive option for
virtualization and cloud computing. In virtual machine scenarios, people
typically deploy a Ceph Block Device with the rbd network storage driver in
QEMU/KVM, where the host machine uses librbd to provide a block device
service to the guest. Many cloud computing stacks use libvirt to integrate
with hypervisors. You can use thin-provisioned Ceph Block Devices with QEMU and
libvirt to support OpenStack, OpenNebula and CloudStack
among other solutions.
While we do not provide librbd support with other hypervisors at this time,
you may also use Ceph Block Device kernel objects to provide a block device to a
client. Other virtualization technologies such as Xen can access the Ceph Block
Device kernel object(s). This is done with the command-line tool rbd.
Ceph 文件系统
The Ceph File System (CephFS) provides a POSIX-compliant filesystem as a service that is layered on top of the object-based Ceph Storage Cluster. CephFS files get mapped to objects that Ceph stores in the Ceph Storage Cluster. Ceph Clients mount a CephFS filesystem as a kernel object or as a Filesystem in User Space (FUSE).
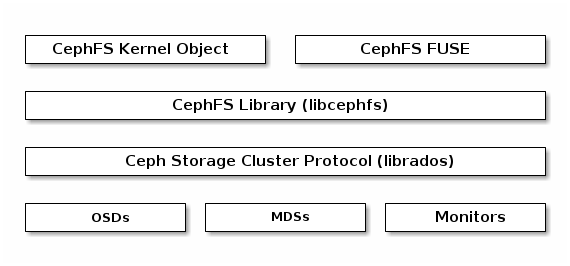
The Ceph File System service includes the Ceph Metadata Server (MDS) deployed
with the Ceph Storage cluster. The purpose of the MDS is to store all the
filesystem metadata (directories, file ownership, access modes, etc) in
high-availability Ceph Metadata Servers where the metadata resides in memory.
The reason for the MDS (a daemon called ceph-mds) is that simple filesystem
operations like listing a directory or changing a directory (ls, cd)
would tax the Ceph OSD Daemons unnecessarily. So separating the metadata from
the data means that the Ceph File System can provide high performance services
without taxing the Ceph Storage Cluster.
CephFS separates the metadata from the data, storing the metadata in the MDS,
and storing the file data in one or more objects in the Ceph Storage Cluster.
The Ceph filesystem aims for POSIX compatibility. ceph-mds can run as a
single process, or it can be distributed out to multiple physical machines,
either for high availability or for scalability.
High Availability: The extra
ceph-mdsinstances can be standby, ready to take over the duties of any failedceph-mdsthat was active. This is easy because all the data, including the journal, is stored on RADOS. The transition is triggered automatically byceph-mon.Scalability: Multiple
ceph-mdsinstances can be active, and they will split the directory tree into subtrees (and shards of a single busy directory), effectively balancing the load amongst all active servers.
Combinations of standby和active etc are possible, for example
running 3 active ceph-mds instances for scaling, and one standby
instance for high availability.
由 Ceph 基金会带给您
Ceph 文档是一个社区资源,由非盈利的 Ceph 基金会资助和托管Ceph Foundation. 如果您想支持这一点和我们的其他工作,请考虑加入现在加入.