注意
本文档适用于 Ceph 开发版本。
CephFS 和 RGW 导出 over NFS
CephFS 命名空间和 RGW 容器可以通过 NFS 协议导出NFS-Ganesha NFS 服务器.
The nfs管理器模块为管理 CephFS 目录或 RGW 容器的 NFS 导出提供了一个通用接口。导出可以通过 CLIceph nfs export ...命令
如果启用Cephadm或Rook协调器,则 nfs-ganesha 守护进程的部署也可以自动管理。如果既不使用协调器(例如,Ceph 通过 Ansible 或 Puppet 等外部协调器部署),则必须手动部署 nfs-ganesha 守护进程;有关更多信息,请参阅手动 Ganesha 部署.
Note
自 Ceph Pacific 开始,nfs mgr module must be enabled.
NFS 集群管理
创建NFS Ganesha集群
$ ceph nfs cluster create <cluster_id> [<placement>] [--ingress] [--virtual_ip <value>] [--ingress-mode {default|keepalive-only|haproxy-standard|haproxy-protocol}] [--port <int>]
这会为所有 NFS Ganesha 守护进程创建一个公共恢复池,基于cluster_id,以及一个公共 NFS Ganesha 配置 RADOS 对象。
Note
由于此命令还使用 ceph-mgr 协调器模块(见Orchestrator CLI)启动 NFS Ganesha 守护进程,因此至少必须启用一个此类模块才能使其工作。
目前,cephadm 部署的 NFS Ganesha 守护进程监听标准端口。因此,每个主机上只部署一个守护进程。
<cluster_id>是此 NFS Ganesha 集群将知的任意字符串(例如,mynfs).
<placement>是一个可选字符串,表示哪些主机应该在其上运行 NFS Ganesha 守护进程容器,并且可选地,集群中 NFS Ganesha 守护进程的总数(如果您希望每个节点运行多个 NFS Ganesha 守护进程)。例如,以下放置字符串意味着“在节点 host1 和 host2 上部署 NFS Ganesha 守护进程(每个主机一个守护进程):
"host1,host2"
,而此放置规范指示在每个节点 host1 和 host2 上部署单个 NFS Ganesha 守护进程(集群中总共两个 NFS Ganesha 守护进程):
"2 host1,host2"
NFS 可以部署在 2049(默认值)以外的端口上--port <port>.
要使用高可用性前端(虚拟 IP 和负载均衡器)部署 NFS,请添加--ingress标志并指定虚拟 IP 地址。这将部署 keepalived 和 haproxy 的组合,为 NFS 服务提供高可用性 NFS 前端。
Note
入口实现尚未完成。启用入口将部署多个 ganesha 实例并在它们之间平衡负载,但主机故障不会立即导致 cephadm 在 NFS 优雅期到期之前部署替换守护进程。此高可用性功能预计在 Quincy 版本(2022 年 3 月)完成。
更多详情,请参阅守护进程放置但请记住,通过 YAML 文件指定放置不支持。
NFS 守护进程和入口服务的部署是异步的:命令可能在服务完全启动之前返回。您可能希望检查这些服务是否成功启动并保持运行。在使用 cephadm 协调时,这些命令检查服务状态:
$ ceph orch ls --service_name=nfs.<cluster_id>
$ ceph orch ls --service_name=ingress.nfs.<cluster_id>
入口
核心服务将部署一个或多个 nfs-ganesha 守护进程,每个守护进程都将提供一个可用的 NFS 端点。每个 NFS 端点的 IP 取决于 nfs-ganesha 守护进程部署的主机。默认情况下,守护进程是半随机放置的,但用户也可以显式控制守护进程的放置位置;请参阅nfs service will deploy one or more nfs-ganesha daemons, each of which will provide a working NFS endpoint. The IP for each NFS endpoint will depend on which host the nfs-ganesha daemons are deployed. By default, daemons are placed semi-randomly, but users can also explicitly control where daemons are placed; see 守护进程放置.
当使用--ingress创建集群时,ingress服务将额外部署以提供 NFS 服务器的负载均衡和高可用性。使用虚拟 IP 提供一个所有客户端都可以用来挂载的已知、稳定的 NFS 端点。Ceph 将负责处理将虚拟 IP 上的 NFS 流量重定向到适当的后端 NFS 服务器以及在它们失败时重新部署 NFS 服务器。
可提供一个可选的--ingress-mode参数来选择ingress服务的配置方式:
设置
--ingress-mode keepalive-only部署一个简化的ingress服务,该服务提供直接绑定到该虚拟 IP 的 nfs 服务器,并省略任何类型的负载均衡或流量重定向。此设置将限制用户只能部署一个 nfs 守护进程,因为多个守护进程不能绑定到虚拟 IP 的同一端口上。设置
--ingress-mode haproxy-standard部署一个完整的ingress服务,使用 HAProxy 和 keepalived 提供负载均衡和高可用性。客户端 IP 地址对后端 NFS 服务器不可见,NFS 导出的 IP 级限制将不起作用。设置
--ingress-mode haproxy-protocol部署一个完整的ingress服务,使用 HAProxy 和 keepalived 提供负载均衡和高可用性。客户端 IP 地址对后端 NFS 服务器可见,NFS 导出的 IP 级限制可用。此模式需要 NFS Ganesha 版本 5.0 或更高版本。设置
--ingress-mode default等同于不通过名称提供任何其他入口模式。当未通过名称指定其他入口模式时,使用的默认入口模式是haproxy-standard.
入口可以添加到现有的 NFS 服务(例如,最初创建时不带--ingress标志的服务),并且基本 NFS 服务也可以事后修改以包含非默认选项,方法是直接修改服务。有关更多信息,请参阅高可用性NFS.
显示 NFS 集群 IP(s)
要检查 NFS 集群的 IP 端点,包括单个 NFS 守护进程的 IP,以及入口服务的虚拟 IP(如果有),
$ ceph nfs cluster info [<cluster_id>]
Note
这将无法与 rook 后端一起使用。相反,请使用 kubectl patch 命令暴露端口,并使用 kubectl get services 命令获取端口详细信息:
$ kubectl patch service -n rook-ceph -p '{"spec":{"type": "NodePort"}}' rook-ceph-nfs-<cluster-name>-<node-id>
$ kubectl get services -n rook-ceph rook-ceph-nfs-<cluster-name>-<node-id>
删除 NFS Ganesha 集群
$ ceph nfs cluster rm <cluster_id>
这会删除部署的集群。
NFS 守护进程和入口服务的移除是异步的:命令可能在服务完全删除之前返回。您可能希望检查这些服务不再报告。在使用 cephadm 协调时,这些命令检查服务状态:
$ ceph orch ls --service_name=nfs.<cluster_id>
$ ceph orch ls --service_name=ingress.nfs.<cluster_id>
更新 NFS 集群
要修改集群参数(如端口或放置),您需要使用协调器接口来更新 NFS 服务规范。最安全的方法是导出当前规范,修改它,然后重新应用它。例如,要修改nfs.foo服务,
$ ceph orch ls --service-name nfs.foo --export > nfs.foo.yaml
$ vi nfs.foo.yaml
$ ceph orch apply -i nfs.foo.yaml
更多关于 NFS 服务规范的详细信息,请参阅NFS 服务.
列出 NFS Ganesha 集群
$ ceph nfs cluster ls
这会列出部署的集群。
设置自定义 NFS Ganesha 配置
$ ceph nfs cluster config set <cluster_id> -i <config_file>
通过此配置,nfs 集群将使用指定的配置,并且它将优先于默认配置块。
示例用例包括:
更改日志级别。可以使用以下配置片段调整日志级别:
LOG { COMPONENTS { ALL = FULL_DEBUG; } }
添加自定义导出块。
以下示例块创建单个导出。此导出将不会由ceph nfs export接口管理:
EXPORT { Export_Id = 100; Transports = TCP; Path = /; Pseudo = /ceph/; Protocols = 4; Access_Type = RW; Attr_Expiration_Time = 0; Squash = None; FSAL { Name = CEPH; Filesystem = "filesystem name"; User_Id = "user id"; Secret_Access_Key = "secret key"; } }
Note
在 FSAL 块中指定的用户应具有适当的权限,以便 NFS-Ganesha 守护进程可以访问 ceph 集群。用户可以使用以下方式创建:auth get-or-create:
# ceph auth get-or-create client.<user_id> mon 'allow r' osd 'allow rw pool=.nfs namespace=<nfs_cluster_name>, allow rw tag cephfs data=<fs_name>' mds 'allow rw path=<export_path>'
查看自定义 NFS Ganesha 配置
$ ceph nfs cluster config get <cluster_id>
这将输出用户定义的配置(如果有)。
重置 NFS Ganesha 配置
$ ceph nfs cluster config reset <cluster_id>
这将移除用户定义的配置。
Note
对于 rook 部署,必须显式重启 ganesha pods,以便新的配置块生效。
导出管理
警告
目前,nfs 接口未与仪表板集成。仪表板和 nfs 接口具有不同的导出要求,并且以不同的方式创建导出。不支持管理仪表板创建的导出。
创建 CephFS 导出
$ ceph nfs export create cephfs --cluster-id <cluster_id> --pseudo-path <pseudo_path> --fsname <fsname> [--readonly] [--path=/path/in/cephfs] [--client_addr <value>...] [--squash <value>] [--sectype <value>...] [--cmount_path <value>]
这会创建包含导出块的导出 RADOS 对象,其中
<cluster_id>是 NFS Ganesha 集群 ID。
<pseudo_path>是 NFS v4 伪文件系统中导出的位置,导出将在服务器上可用。它必须是绝对路径且唯一。
<fsname>是 NFS Ganesha 集群使用的 FS 卷的名称,该卷将提供此导出。
<path>是 cephfs 中的路径。应给出有效路径,默认路径是‘/’。它不必唯一。可以使用以下方式获取子卷路径:
$ ceph fs subvolume getpath <vol_name> <subvol_name> [--group_name <subvol_group_name>]
<client_addr>是适用这些导出权限的客户端地址列表。默认情况下,所有客户端都可以根据指定的导出权限访问导出。有关允许值的详细信息,请参阅NFS-Ganesha 导出示例定义要执行的用户 ID 压缩类型。默认值是
<squash> defines the kind of user id squashing to be performed. The default
value is no_root_squash。有关允许值的详细信息,请参阅NFS-Ganesha 导出示例定义要执行的用户 ID 压缩类型。默认值是
<sectype>指定连接到导出时将使用的身份验证方法。有效值包括“krb5p”、“krb5i”、“krb5”、“sys”和“none”。可以提供多个值。该标志可以多次指定(示例:--sectype=krb5p --sectype=krb5i)或多个值可以由逗号分隔(示例:--sectype krb5p,krb5i)。服务器将与客户端协商支持的安全类型,优先考虑提供的左侧方法。
<cmount_path>指定在 CephFS 中挂载此导出的路径。它允许是/和EXPORT {path}之间的任何完整路径层次结构(即,如果EXPORT { Path }参数是/foo/bar,则 cmount_path 可以是/, /foo或/foo/bar).
Note
如果此参数和其他EXPORT { FSAL {} }选项在多个导出之间相同,则这些导出将共享单个 CephFS 客户端。如果未指定,默认值是/.
Note
指定 sectype 的值,这些值需要 Kerberos,仅在服务器配置为支持 Kerberos 时才有效。设置 NFS-Ganesha 以支持 Kerberos 的方法可以在这里找到Kerberos setup for NFS Ganesha in Ceph.
Note
仅支持使用 nfs 接口部署的 NFS Ganesha 集群创建导出。
创建 RGW 导出
RGW 导出有两种类型:
a user导出将导出属于 RGW 用户的所有桶,其中导出的顶层目录是桶的列表。
a 桶导出将导出单个桶,其中顶层目录包含桶中的对象。
RGW 桶导出
要导出桶:
$ ceph nfs export create rgw --cluster-id <cluster_id> --pseudo-path <pseudo_path> --bucket <bucket_name> [--user-id <user-id>] [--readonly] [--client_addr <value>...] [--squash <value>] [--sectype <value>...]
例如,要通过 NFS 集群mybucket到mynfs在伪路径/bucketdata导出192.168.10.0/24网络中的任何主机
$ ceph nfs export create rgw --cluster-id mynfs --pseudo-path /bucketdata --bucket mybucket --client_addr 192.168.10.0/24
Note
仅支持使用 nfs 接口部署的 NFS Ganesha 集群创建导出。
<cluster_id>是 NFS Ganesha 集群 ID。
<pseudo_path>是 NFS v4 伪文件系统中导出的位置,导出将在服务器上可用。它必须是绝对路径且唯一。
<bucket_name>是将要导出的桶的名称。
<user_id>是可选的,指定用于对桶进行读写操作的 RGW 用户。如果未指定,则将使用拥有桶的用户。
Note
目前,如果启用了多站点 RGW,Ceph 只能导出默认域中的 RGW 桶。
<client_addr>是适用这些导出权限的客户端地址列表。默认情况下,所有客户端都可以根据指定的导出权限访问导出。有关允许值的详细信息,请参阅NFS-Ganesha 导出示例定义要执行的用户 ID 压缩类型。默认值是
<squash> defines the kind of user id squashing to be performed. The default
value is no_root_squash。有关允许值的详细信息,请参阅NFS-Ganesha 导出示例定义要执行的用户 ID 压缩类型。默认值是
<sectype>指定连接到导出时将使用的身份验证方法。有效值包括“krb5p”、“krb5i”、“krb5”、“sys”和“none”。可以提供多个值。该标志可以多次指定(示例:--sectype=krb5p --sectype=krb5i)或多个值可以由逗号分隔(示例:--sectype krb5p,krb5i)。服务器将与客户端协商支持的安全类型,优先考虑提供的左侧方法。
Note
指定 sectype 的值,这些值需要 Kerberos,仅在服务器配置为支持 Kerberos 时才有效。设置 NFS-Ganesha 以支持 Kerberos 的方法不在本文档的范围内。
RGW 用户导出
要导出 RGWuser:
$ ceph nfs export create rgw --cluster-id <cluster_id> --pseudo-path <pseudo_path> --user-id <user-id> [--readonly] [--client_addr <value>...] [--squash <value>]
例如,要通过 NFS 集群myuser到mynfs在伪路径/myuser导出192.168.10.0/24网络中的任何主机
$ ceph nfs export create rgw --cluster-id mynfs --pseudo-path /bucketdata --user-id myuser --client_addr 192.168.10.0/24
删除导出
$ ceph nfs export rm <cluster_id> <pseudo_path>
这会删除 NFS Ganesha 集群中的一个导出,其中:
<cluster_id>是 NFS Ganesha 集群 ID。
<pseudo_path>是伪根路径(必须是绝对路径)。
列出导出
$ ceph nfs export ls <cluster_id> [--detailed]
它会列出集群的导出,其中:
<cluster_id>是 NFS Ganesha 集群 ID。
使用--detailed选项时,它会显示整个导出块。
获取导出
$ ceph nfs export info <cluster_id> <pseudo_path>
这会根据伪根名称显示导出块,其中:
<cluster_id>是 NFS Ganesha 集群 ID。
<pseudo_path>是伪根路径(必须是绝对路径)。
通过 JSON 规范创建或更新导出
现有导出可以以 JSON 格式导出:
ceph nfs export info *<cluster_id>* *<pseudo_path>*
导出可以导入 JSON 描述以进行创建或修改:
ceph nfs export apply *<cluster_id>* -i <json_file>
例如:
$ ceph nfs export info mynfs /cephfs > update_cephfs_export.json
$ cat update_cephfs_export.json
{
"export_id": 1,
"path": "/",
"cluster_id": "mynfs",
"pseudo": "/cephfs",
"access_type": "RW",
"squash": "no_root_squash",
"security_label": true,
"protocols": [
4
],
"transports": [
"TCP"
],
"fsal": {
"name": "CEPH",
"fs_name": "a",
"sec_label_xattr": "",
"cmount_path": "/"
},
"clients": []
}
导入的 JSON 可以是一个描述单个导出的单个字典,或者是一个包含多个导出字典的 JSON 列表。
导出的 JSON 可以被修改然后重新应用。以下,pseudo和access_type被修改。在修改导出时,提供的 JSON 应该完全描述导出的新状态(就像创建新导出时一样),例外是身份验证凭据,这些凭据将从导出的先前状态中继承。
!! 注意:应user_id。Cephadm 还支持使用fsal块不应在 JSON 文件中修改或提及,因为它是为 CephFS 导出自动生成的。nfs.<cluster_id>.<fs_name>.<hash_id>.
$ ceph nfs export apply mynfs -i update_cephfs_export.json
$ cat update_cephfs_export.json
{
"export_id": 1,
"path": "/",
"cluster_id": "mynfs",
"pseudo": "/cephfs_testing",
"access_type": "RO",
"squash": "no_root_squash",
"security_label": true,
"protocols": [
4
],
"transports": [
"TCP"
],
"fsal": {
"name": "CEPH",
"fs_name": "a",
"sec_label_xattr": "",
"cmount_path": "/"
},
"clients": []
}
格式自动生成。
$ ceph nfs export apply mynfs -i update_cephfs_export.conf
$ cat update_cephfs_export.conf
EXPORT {
FSAL {
name = "CEPH";
filesystem = "a";
}
export_id = 1;
path = "/";
pseudo = "/a";
access_type = "RW";
squash = "none";
attr_expiration_time = 0;
security_label = true;
protocols = 4;
transports = "TCP";
}
挂载
导出成功创建并且 NFS Ganesha 守护进程部署后,可以挂载导出:
$ mount -t nfs <ganesha-host-name>:<pseudo_path> <mount-point>
例如,如果 NFS 集群是使用--ingress --virtual-ip 192.168.10.10创建的,并且导出的伪路径是/foo,则可以在/mnt挂载导出:
$ mount -t nfs 192.168.10.10:/foo /mnt
如果 NFS 服务在非标准端口上运行:
$ mount -t nfs -o port=<ganesha-port> <ganesha-host-name>:<ganesha-pseudo_path> <mount-point>
Note
仅支持 NFS v4.0+。
Note
截至(2024 年 1 月 1 日),没有任何版本的 Microsoft Windows 本地支持挂载 NFS v4.x 导出。
故障排除
使用
cephadm检查 NFS-Ganesha 日志:NFS 守护进程可以列出:$ ceph orch ps --daemon-type nfs
可以通过相关主机上特定守护进程(例如,
nfs.mynfs.0.0.myhost.xkfzal)的日志来查看:# cephadm logs --fsid <fsid> --name nfs.mynfs.0.0.myhost.xkfzalrook:$ kubectl logs -n rook-ceph rook-ceph-nfs-<cluster_id>-<node_id> nfs-ganesha
可以使用nfs cluster config set命令(见设置自定义 NFS Ganesha 配置).
手动 Ganesha 部署
可能可以在没有 cephadm 或 rook 等协调框架的情况下部署和管理 NFS ganesha 守护进程。
Note
手动配置未经过测试或完全记录;您的体验可能会有所不同。如果您使它工作,请通过更新此文档来帮助我们。
限制
如果 Ceph 管理器未启用协调器模块,则 NFS 集群管理命令,如以ceph nfs cluster开头的命令,将无法工作。但是,只要必要的 RADOS 对象已经创建,管理 NFS 导出的命令,如以ceph nfs export开头的命令,应该可以正常工作。目前,所需的精确 RADOS 对象未记录,因为对该功能的支持不完整。好奇的读者可以通过阅读mgr/nfs模块的源代码(在 ceph 源树中的src/pybind/mgr/nfs).
要求
下找到)来了解一些关于对象的信息。
nfs-ganesha,nfs-ganesha-ceph,nfs-ganesha-rados-grace和nfs-ganesha-rados-urls包(版本 3.3 及以上)
Ganesha 配置层次结构
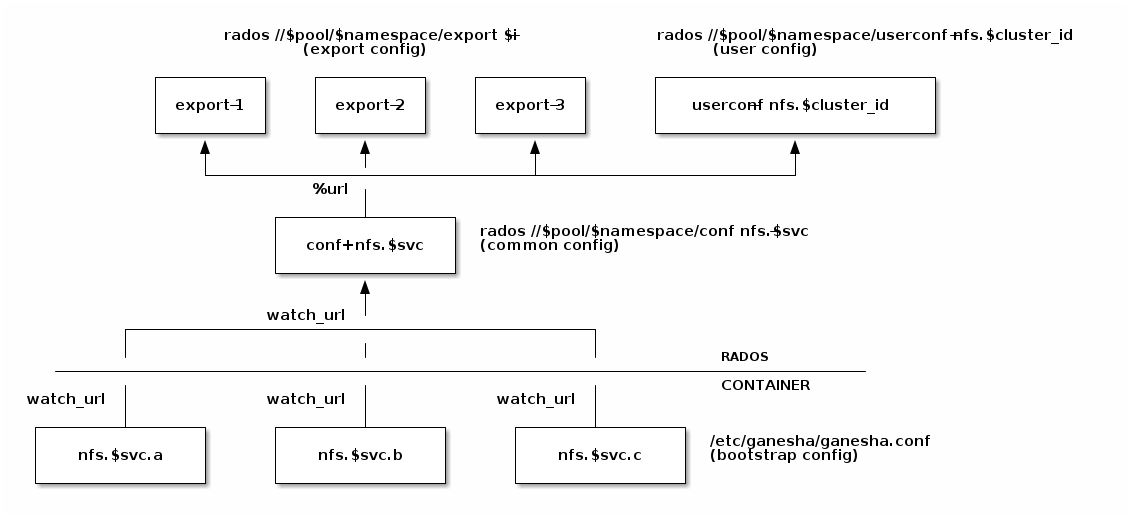
Cephadm 和 rook 为每个 nfs-ganesha 守护进程启动一个最小的bootstrap配置文件,该配置文件从存储在common配置中拉取,并监视公共配置的变化。每个导出都写入到一个单独的 RADOS 对象,该对象通过 URL 从公共配置中引用。.nfsRADOS 池中的共享
由 Ceph 基金会带给您
Ceph 文档是一个社区资源,由非盈利的 Ceph 基金会资助和托管Ceph Foundation. 如果您想支持这一点和我们的其他工作,请考虑加入现在加入.