
运行 FreqAI¶
有两种方式来训练和部署自适应机器学习模型——实盘部署和历史回测。在这两种情况下,FreqAI 都会如以下图示所示,周期性地重新训练模型。
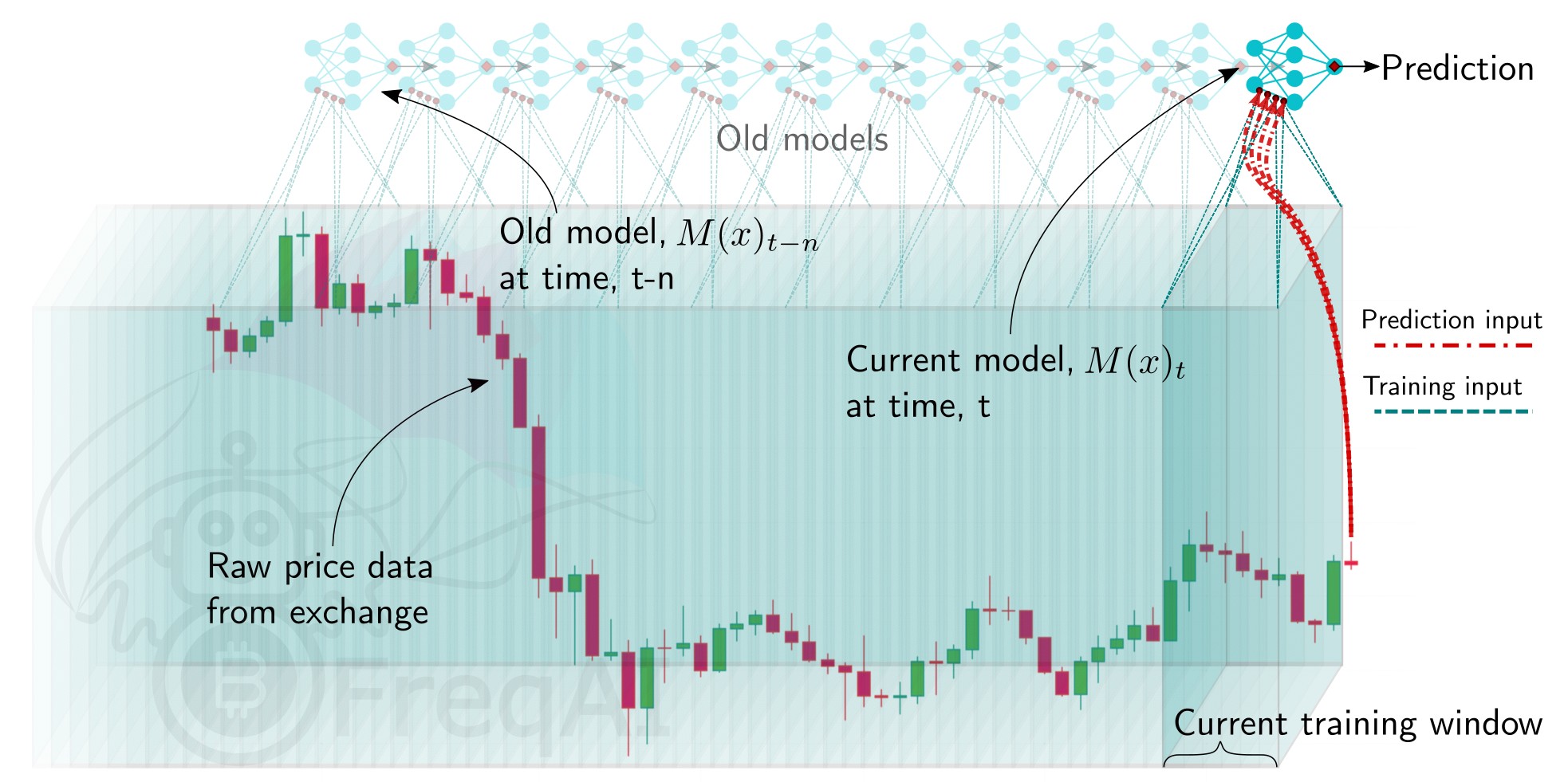
实盘部署¶
可以使用以下命令以模拟或实盘模式运行 FreqAI:
freqtrade trade --strategy FreqaiExampleStrategy --config config_freqai.example.json --freqaimodel LightGBMRegressor
启动后,FreqAI 将根据配置设置开始训练一个具有新 identifier 的新模型。训练完成后,该模型将用于对新到达的 K 线进行预测,直到有新的模型可用为止。通常情况下,新模型会尽可能频繁地生成,FreqAI 内部会管理一个交易对队列,以尽量保持所有模型的更新程度一致。FreqAI 始终使用最新训练好的模型对实时数据进行预测。如果你不希望 FreqAI 尽可能频繁地重新训练模型,可以设置 live_retrain_hours 参数,使 FreqAI 至少等待指定小时数后再训练新模型。此外,你还可以设置 expired_hours 参数,让 FreqAI 避免使用超过指定小时数的旧模型进行预测。
默认情况下,训练好的模型会被保存到磁盘,以便在回测期间或崩溃后重复使用。你可以通过在配置中设置 "purge_old_models": true 来选择清理旧模型,从而节省磁盘空间。
若要从已保存的回测模型(或之前因崩溃而中断的模拟/实盘会话)启动模拟或实盘运行,只需指定对应模型的 identifier 即可:
"freqai": {
"identifier": "example",
"live_retrain_hours": 0.5
}
在这种情况下,尽管 FreqAI 会使用预训练模型启动,但仍会检查自模型训练以来经过的时间。如果自加载模型结束训练后已经过去完整的 live_retrain_hours 时间,FreqAI 将开始训练一个新模型。
自动数据下载¶
FreqAI 会自动下载所需数量的数据,以确保模型能够基于设定的 train_period_days 和 startup_candle_count 完成训练(有关这些参数的详细说明,请参见参数表)。
保存预测数据¶
在特定 identifier 模型生命周期内所做的所有预测都会被存储在 historic_predictions.pkl 文件中,以便在程序崩溃或配置更改后重新加载。
清理旧模型数据¶
FreqAI 每次成功训练后都会保存新的模型文件。随着为适应新市场条件而生成的新模型不断出现,这些旧文件将变得过时。如果你计划长时间运行 FreqAI 并频繁重新训练模型,建议在配置中启用 purge_old_models:
"freqai": {
"purge_old_models": 4,
}
此设置将自动清除最近四个最新模型之外的所有旧模型,以节省磁盘空间。输入 "0" 表示永不清理任何模型。
回测¶
可以通过以下命令执行 FreqAI 回测模块:
freqtrade backtesting --strategy FreqaiExampleStrategy --strategy-path freqtrade/templates --config config_examples/config_freqai.example.json --freqaimodel LightGBMRegressor --timerange 20210501-20210701
如果此前从未使用现有配置文件执行过该命令,FreqAI 将为每个交易对在扩展的 --timerange 内的每个回测窗口训练一个新模型。
回测模式需要在部署前下载必要的数据(与实盘/模拟交易模式不同,在后者中 FreqAI 会自动处理数据下载)。请注意,下载的数据时间范围应比回测时间范围更长,因为 FreqAI 需要在目标回测时间段之前的数据来训练模型,以便能够对回测时间段的第一根 K 线做出预测。有关如何计算所需下载数据的更多细节,请参见此处。
模型复用
一旦训练完成,你可以使用相同的配置文件再次运行回测,FreqAI 将找到已训练好的模型并加载它们,而无需重新训练。当你希望调整(甚至进行超参数优化)策略中的买入和卖出条件时,这一点非常有用。如果你希望使用相同的配置文件重新训练新模型,只需更改identifier即可。通过这种方式,你可以随时通过指定identifier来重新使用任意一个之前训练的模型。
注意
回测会针对每个回测窗口调用一次set_freqai_targets()(回测窗口数量等于整个回测时间范围除以backtest_period_days参数)。这样做可以确保目标值的生成模拟了实盘行为,且避免了未来数据偏差。然而,feature_engineering_*() 中特征的定义是在整个训练时间范围内仅执行一次的。这意味着你必须确保特征不会引入未来数据。有关未来数据偏差的更多细节,请参见常见错误。
保存回测预测数据¶
为了便于调整你的策略(而不是特征),FreqAI 会在回测期间自动保存预测结果,以便在将来使用相同identifier模型的回测或实盘运行中重复使用。这一功能旨在提升性能,特别适用于对进出仓条件进行高层级超参数优化。
在unique-id文件夹中,将创建一个名为backtesting_predictions的新目录,其中包含以feather格式存储的所有预测数据。
如果你想更改特征,则必须在配置中设置一个新的identifier,以通知 FreqAI 需要训练新的模型。
若要保存特定回测过程中生成的模型,以便后续可以直接用于实盘部署而无需重新训练,你必须在配置中将save_backtest_models设置为True。
注意
为了确保模型可被复用,freqAI 会使用长度为 1 的数据框调用你的策略。如果你的策略需要更多历史数据才能生成相同的特征,则无法将回测预测结果用于实盘部署,此时你需要为每次新的回测更新identifier。
回测实盘历史预测¶
FreqAI 允许你通过回测参数--freqai-backtest-live-models复用实盘历史预测结果。当你希望复用模拟/实盘运行期间生成的预测结果进行对比或其他分析时,此功能非常有用。
--timerange 参数不得手动指定,因为它将通过历史预测文件中的数据自动计算。
正在下载数据以覆盖完整的回测周期¶
对于实盘/模拟交易部署,FreqAI 会自动下载所需数据。然而,若要使用回测功能,你需要使用 download-data 手动下载必要数据(详情见此处)。你必须仔细考虑需要额外下载多少数据,以确保在回测时间段开始之前有足够数量的训练数据。所需的额外数据量大致可通过将时间范围的起始日期向前推移train_period_days以及startup_candle_count(参见参数表了解这些参数的详细说明)来估算。
例如,若要使用--timerange 20210501-20210701进行回测,并采用示例配置中设置的train_period_days为 30 天,以及startup_candle_count: 40,且最大include_timeframes为 1 小时,则下载数据的起始日期应为20210501减去 30 天再减去 40 × 1 小时 ÷ 24 小时 = 20210330(比期望回测时间段早约 31.7 天)。
确定滑动训练窗口大小和回测持续时间¶
回测时间范围通过配置文件中的标准参数--timerange定义。train_period_days设置滑动训练窗口的持续时间,而backtest_period_days则表示滑动回测窗口的长度,两者均以天数表示(在实盘/模拟模式下,backtest_period_days可使用浮点数表示亚日级的重新训练频率)。在提供的示例配置(位于config_examples/config_freqai.example.json)中,用户要求 FreqAI 使用 30 天的训练期,并在接下来的 7 天进行回测。模型训练完成后,FreqAI 将对接下来的 7 天进行回测。随后,“滑动窗口”向前移动一周(模拟实盘模式下每周重新训练一次),新模型使用前 30 天的数据(包括前一个模型用于回测的 7 天)进行训练。此过程将持续到--timerange结束。这意味着,如果你设置了--timerange 20210501-20210701,在--timerange结束时,FreqAI 将总共训练 8 个独立模型(因为整个时间段共包含 8 周)。
注意
虽然允许使用小数形式的backtest_period_days,但需注意,--timerange会除以该值以确定 FreqAI 完成完整回测所需训练的模型数量。例如,若设置--timerange为 10 天,backtest_period_days为 0.1,则 FreqAI 每个交易对需训练 100 个模型才能完成完整回测。正因如此,对 FreqAI 自适应训练机制进行完整回测将耗时非常长。全面测试模型的最佳方式是运行模拟交易并让其持续训练。在这种情况下,回测所需时间将与模拟运行完全相同。
定义模型过期机制¶
在干燥/实盘模式下,FreqAI 会依次训练每个币种交易对(在与主 Freqtrade 机器人分离的线程/GPU 上)。这意味着各个模型之间始终存在时间上的差异。如果你正在训练 50 个交易对,而每个交易对需要 5 分钟完成训练,那么最旧的模型将超过 4 小时。如果某个策略的特征时间尺度(即目标交易周期)小于 4 小时,这可能是不可接受的。你可以通过在配置文件中设置 expiration_hours 来决定仅在模型年龄小于特定小时数时才允许交易:
"freqai": {
"expiration_hours": 0.5,
}
在提供的示例配置中,用户仅允许使用年龄小于 ½ 小时的模型进行预测。
控制模型学习过程¶
模型训练参数取决于所选的机器学习库。FreqAI 允许你通过配置文件中的 model_training_parameters 字典为任意库设置任何参数。示例配置(位于 config_examples/config_freqai.example.json)展示了与 Catboost 和 LightGBM 相关的一些示例参数,但你也可以添加这些库或其他你选择实现的机器学习库中的任意可用参数。
数据划分参数在 data_split_parameters 中定义,其可包含与 scikit-learn 的 train_test_split() 函数相关的任意参数。train_test_split() 包含一个名为 shuffle 的参数,用于决定是否打乱数据或保持原始顺序。这对于避免因时间上自相关的数据而引入偏差特别有用。有关这些参数的更多细节,请参阅 scikit-learn 官网(外部网站)。
FreqAI 特有的参数 label_period_candles 定义了用于生成 标签 的偏移量(即未来多少根 K 线)。在提供的 示例配置 中,用户要求使用未来 24 根 K 线的数据来生成 标签。
持续学习¶
你可以在配置中设置 "continual_learning": true 来启用持续学习方案。启用 continual_learning 后,初始模型将从零开始训练,之后的每次训练都将以上一次训练结束时的模型状态为起点。这使得新模型能够“记住”之前的状态。默认情况下,该选项设置为 False,意味着所有新模型都从头开始训练,不继承先前模型的信息。
持续学习强制使用固定的参数空间
由于 continual_learning 意味着模型的参数空间在训练之间 不能 发生变化,因此当启用 continual_learning 时,principal_component_analysis 会自动被禁用。提示:PCA 会改变参数空间和特征数量,了解更多关于 PCA 的信息请参见 此处。
实验性功能
请注意,目前这种增量学习方法较为简单,在市场变化导致模型偏离实际时,极有可能出现过拟合或陷入局部最优的问题。FreqAI 提供这些机制主要是出于实验目的,并为将来在加密货币市场等复杂系统中应用更成熟的持续学习方法做好准备。
超参数优化¶
你可以使用与 常规 Freqtrade 超参数优化 相同的命令来进行超参数优化:
freqtrade hyperopt --hyperopt-loss SharpeHyperOptLoss --strategy FreqaiExampleStrategy --freqaimodel LightGBMRegressor --strategy-path freqtrade/templates --config config_examples/config_freqai.example.json --timerange 20220428-20220507
hyperopt 要求你以与进行回测相同的方式预先下载好数据。此外,在对 FreqAI 策略进行超参数优化时,你还必须考虑一些限制条件:
--analyze-per-epoch超参数优化选项与 FreqAI 不兼容。- 无法对
feature_engineering_*()和set_freqai_targets()函数中的指标进行超参数优化。这意味着你不能使用 hyperopt 来优化模型参数。除这一例外情况外,其他所有空间都可以进行优化。 - 回测的相关说明同样适用于超参数优化(hyperopt)。
结合 hyperopt 与 FreqAI 的最佳方法是专注于优化入场/出场的阈值或条件。你应该将重点放在那些未用于特征工程的参数上。例如,你不应尝试对特征生成过程中使用的滑动窗口长度,或任何会影响预测结果的 FreqAI 配置部分进行超参数优化。为了高效地执行 FreqAI 策略的超参数优化,FreqAI 会将预测结果以数据框(dataframe)形式存储并重复使用,因此只能对入场/出场阈值或条件进行优化。
FreqAI 中一个典型的可超参数优化的例子是差异指数(DI)DI_values的阈值,超过该阈值的数据点将被视为异常值:
di_max = IntParameter(low=1, high=20, default=10, space='buy', optimize=True, load=True)
dataframe['outlier'] = np.where(dataframe['DI_values'] > self.di_max.value/10, 1, 0)
这种特定的超参数优化有助于你了解在特定参数空间下合适的DI_values值。
使用 Tensorboard¶
可用性
FreqAI 为多种模型提供了 TensorBoard 支持,包括 XGBoost、所有 PyTorch 模型、强化学习模型以及 Catboost。如果你希望将 TensorBoard 集成到其他类型的模型中,请在Freqtrade GitHub上提交问题。
要求
TensorBoard 日志记录需要使用 FreqAI 的 Torch 安装包或 Docker 镜像。
使用 TensorBoard 最简单的方法是确保配置文件中 freqai.activate_tensorboard 设置为 True(默认设置),运行 FreqAI 后,在另一个终端窗口中执行以下命令:
cd freqtrade
tensorboard --logdir user_data/models/unique-id
其中 unique-id 是你在 freqai 配置文件中设置的 identifier。如果你想在浏览器中通过 127.0.0.1:6060 查看输出结果(6060 是 TensorBoard 的默认端口),则必须在单独的终端中运行此命令。
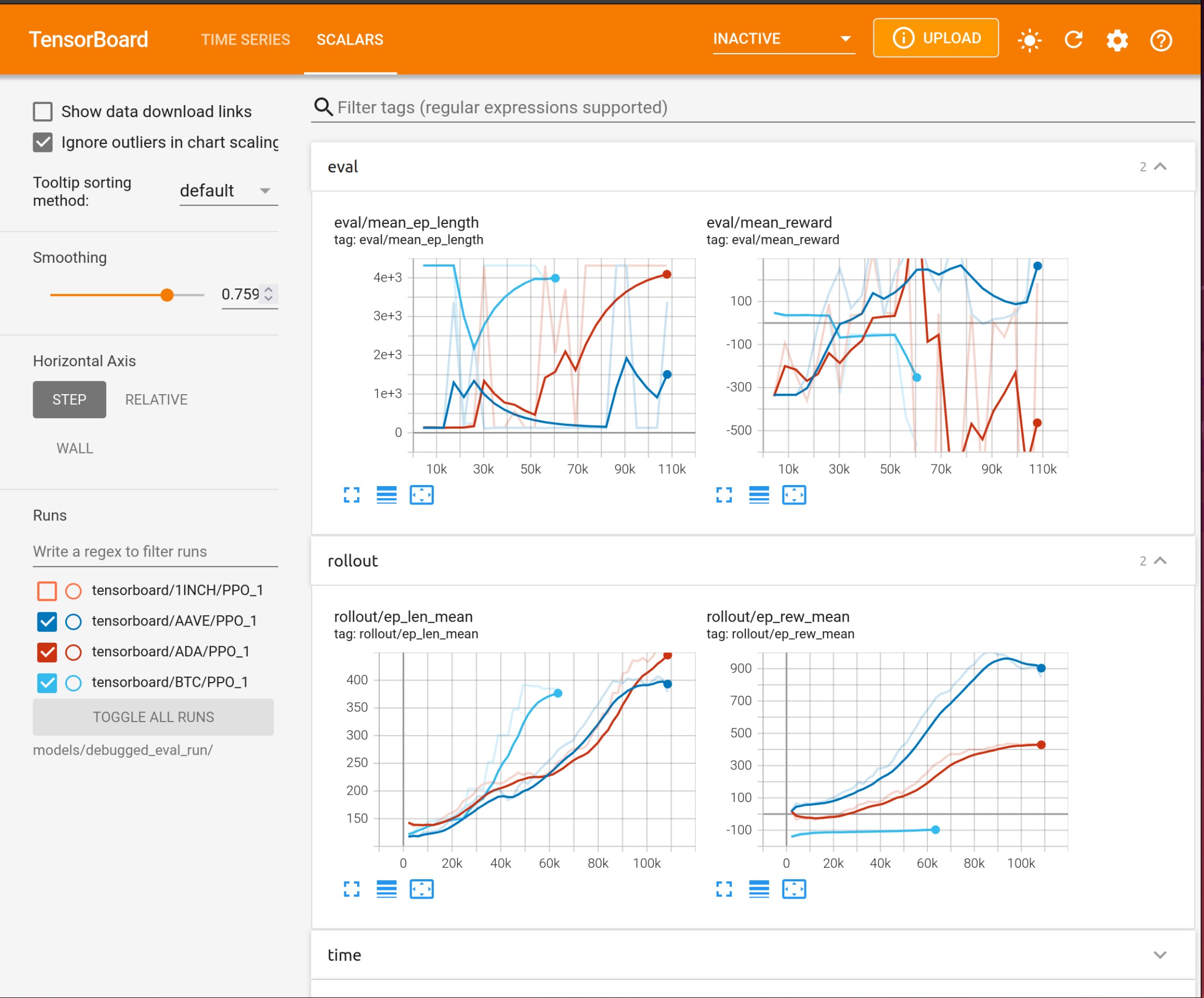
停用以提升性能
TensorBoard 日志记录可能会减慢训练速度,因此在生产环境中应将其关闭。