
Beancount Vnext:目标与设计
Martin Blais,2020 年 7 月
http://furius.ca/beancount/doc/Vnext
动机
是时候为 Beancount 进行一次全面更新,并制定一个明确的计划,以确定其下一版本应具备的功能。这些想法在我脑海中酝酿已久——至少有一年了。我将它们写下来,一方面是为了分享我们所有人用来管理财务的工具未来可能成为的样子,另一方面是为了征求反馈,同时也为了梳理我的思路,更好地优先处理真正重要的事项。
当前状态。 目前 Beancount 的开发已停滞一段时间,原因众多。该软件的状态远非完美(我将在本文中列举主要问题),但我一直抵制做出过多改动,以确保自己和他人拥有一个真正稳定的基线。更重要的是,虽然我过去能花大量周末时间进行开发,但生活变化以及近期对职业的专注,使我难以再抽出额外时间(毕竟已经过去十年了)。大量想法已积累在这个待办文件中,但该文件过于详细,难以理解,且像是一堆杂乱的记录,而本文应更具实用性。
为何需要重写。 当我编写 Beancount 的第二个版本(对第一个版本的完全重写)时,是因为一系列改进最初版本的想法汇聚在一起;我曾一度抵制,但最终这些想法对我而言如此合理,以至于不写出来反而变得不可能。当时推动重新设计的许多理念,如今仍是设计的核心原则:消除顺序依赖、使用 BNF 语法规范语法、将自定义处理转换为基于简单指令流的插件序列、当前的记账选择机制和成本基础实现方式,以及所有超越“交易”的指令。这些理念很大程度上塑造了今天许多人喜爱 Beancount 的原因。
目标。 现在是 Beancount 迎来新一轮演化的时机,我将在本文中提出一套全新的理念,其变革力度将不亚于从 v1 到 v2 的转变。我对 Vnext 的愿景是通过将系统分解为更简单、更独立、更可复用、定义更清晰的组件来简化 Beancount,而非仅仅在现有基础上堆砌新功能。在许多方面,Vnext 将是对当前系统的提炼。它还将为实现用户最常期待的核心功能腾出空间。这些改动还将改善组织结构:促进更多贡献,并减少我亲自维护的代码量,使我能够更有效地专注于核心功能。
当前问题
性能
我的个人账本,以及我知道许多用户的账本,都大到无法即时处理。我目前的文件在我家用于桌面的高性能NUC上需要 6 秒才能处理完毕——但这实在太久了。我非常坚持每次运行时都完整处理所有输入文件的理念,而不是强迫用户将账本切割成多个文件,并在一年中的任意时间点设置“结转”标记,但我确实希望获得像运行两个字母的 UNIX 命令那样的“即时”体验,即运行时间远低于半秒。这将使使用过程更具互动性和趣味性。
C++ 重写。 目前性能缓慢的原因之一是 Beancount 完全使用 Python 实现,甚至解析器层面也是 C 代码回调到 Python 驱动程序。一个明显的解决方案是将软件的核心部分重写为更接近底层的语言,即 C++。我选择 C++ 是因为它提供了更好的控制力,且其周边工具链成熟且广泛普及,大多数人构建时不会遇到太多问题,同时我还能利用所需的 C 库。使用函数式语言或许很有趣,但许多我需要的库根本无法获得,或者普通用户难以构建。
简洁、可移植的 C++。 需要强调的是,我设想的 C++ 代码并非类似 Boost 中那种模板泛滥的现代 C++ 风格,而是更接近 Google 使用的保守型 “无异常的几乎 C 语言子集”,并以 Abseil-Cpp 为基础(示例与风格参见 技巧)。这样做的原因是稳定性和可移植性。虽然此次重写旨在提升性能,但我认为无需借助模板技巧即可达到足够快的速度——仅通过直接移植以避开 Python 运行时就很可能足够了。最重要的是,我希望新代码尽可能保持简单和“类函数式”(能避免类就避免),依赖一组经过验证的 稳定依赖项,并通过 Bazel 构建工具进行封闭式构建。
Python API。 同样重要的是,Python API 需要保留,以便支持插件和脚本,并且完整的单元测试套件也必须迁移到新版代码中。毕竟,使用这些个人财务数据编写自定义脚本的能力,正是基于文本方式最吸引人的特性之一。新核心实现之外的代码仍将使用 Python 编写,基于现有 Python API 构建的代码应能非常轻松地移植到 Vnext 版本。这可以通过使用 pybind11 编写包装器暴露指令来实现。
其他语言。 Beancount 核心的输出结果将是一系列协议缓冲区对象,因此其他语言(如 Go)将获得第一类支持。
处理模型。 如果有必要进一步提升性能,另一个算法改进是将插件处理定义为迭代器函数,这些函数可以级联并交错处理指令流,而无需对整个指令列表进行完全独立的多次遍历。虽然允许每个插件独立处理所有指令,有助于避免同步应用状态,并使插件行为彼此隔离,但仍有机会将多个转换合并到单次遍历中。遍历次数越少,速度越快。
中间解析数据与最终指令列表
在 Beancount v2 中,我从未仔细区分过
-
从解析器输出的指令列表,尚未进行插值和记账,使用
position.CostSpec而非每笔仓位的position.Cost,以及 -
经过解析和记账的指令列表,已应用记账算法选择匹配的仓位,填充插值值,并由各个插件完成转换。
这两组指令在用途上确实截然不同,尽管它们共享许多相同的数据结构,且第一组指令主要出现在解析器模块中。即使是我自己,也曾因混淆了正在操作的是哪一组而感到困扰。部分原因在于,我几乎对两者都使用了相同的 Python 数据结构,这让我可以灵活地绕过类型约束。
更重要的是,由于插件在记账和插值之后运行,且必须输出完全插值和记账后的交易,因此,若一个插件希望扩展那些在输入语法中本应无效的交易,就会变得十分困难。请参见#541以了解示例。
下一版本将把中间解析产物和最终解析后的指令列表都实现为协议缓冲区消息,并使用严格区分的数据类型。这将取代beancount.core.data。这两个数据流之间的区别将变得非常清晰,我会尽量隐藏前者。目标是让插件编写者根本无需接触中间列表——它应成为核心实现中的一个隐藏细节。
此外,可能存在两种类型的插件:一种在解析器输出的未插值、未记账数据上运行,另一种在已解析并完成记账的数据流上运行。这将允许更灵活地使用部分输入数据,即使这些数据在插值和记账的限制下本应无效。
更新:
-
我们可以将插件系统改为在记账/插值阶段运行。
-
我们应尝试使记账/插值过程具有原子性,即用户可以编写一个包含累加器的 Python 循环,并独立调用它,从而理论上允许在导入器中使用记账功能(如我为 Ameritrade 所做的那样)。
将输入重写设为一级功能
于 2020 年 12 月根据反馈和#586添加。
许多常见问题都涉及如何处理输入数据本身。通常,新用户会尝试加载账本内容、修改数据结构,然后打印以更新文件,却未意识到打印功能会包含所有插值、记账数据和插件修改,因此这种方法行不通。
然而,由于我们正在重写解析器,并确保中间的类 ASI 数据与已处理并最终确定的指令之间有清晰的分离,我们可以为 AST 中间数据实现一个专用的打印器,使用户能够仅运行解析器,修改中间指令,再将其打印回文件,仅可能丢失部分格式和空白字符。这种格式损失可被利用,以更自然的方式重新实现 bean-format:该打印器的输出应始终整齐格式化。这将避免用户不得不编写临时解析器、类似 sed 的转换等操作,他们可以改为直接修改数据结构来实现目标。
更重要的是,为了使这一功能准确运行,我们必须推迟解析后算术运算的处理,以便能够重新渲染它们。这带来了另一个优势:如果我们延迟计算处理,就可以提供一个选项,让用户指定用于 mpdecimal 的精度配置。我非常欣赏这个想法,因为它避免了硬编码计算精度,更清晰地定义了这些选项的结果,从而可能为更合理地去除通常被渲染出的多余数字打开大门。
最后,如果能够编写一个优秀的库函数,直接在原地处理交易并输出,同时保留所有周围的注释,这将成为我们清理收款人等数据的另一种方式——也许是更优选的方式。目前,解决方案是编写一个插件来清理数据,但输入文件仍然显得杂乱无章。让输入文件能够自动清理,是一个极具吸引力的替代方案,也可能为 Beancount 工作流增添一个重要新维度。
我希望做出所有必要的更改,以实现并充分支持这一功能(我现在想象着我的记账文件已被彻底清理,这非常诱人)。我认为这并不需要太多工作,主要包括:
-
为所有内容存储起始和结束行信息。
-
添加用于表示算术运算的 AST 结构。
-
在渲染器中增加注释解析功能。
-
实现一个新的渲染器,能够重现 AST,包括处理缺失数据。
-
实现一个库,使原地修改文件变得像编写插件一样简单,同时完整保留文件中所有非指令性数据。
贡献
在 Beancount 的大部分开发过程中,我一直对接受外部贡献持谨慎态度。由于该项目对我个人财务安排影响重大,我非常担心意外的破坏。我对贡献的主要顾虑有两点:
-
测试不足。 一些提议的更改没有包含足够的测试,甚至完全没有测试,连防止基本破坏的最基础测试都没有。当我接受某些提议并亲自编写测试时,有时会陷入无尽的调试中,耗时数小时甚至数天。这并不现实。
-
设计影响的连锁反应。 一些提议没有考虑到更广泛的设计考量,可能会影响代码的其他部分,而这些考量我可能没有充分传达或记录清楚。为了保持代码的连贯性和紧凑性,我不得不拒绝了一些想法。
这部分责任在我:对贡献设置过高门槛,导致潜在贡献者难以获得足够的上下文和对代码库的熟悉度,从而无法做出与设计兼容的修改。
允许更多贡献。 从 Vnext 版本开始,我希望重构项目,让更多人能够直接参与,并与某些贡献者就特定功能进行一对一紧密协作。显然,Beancount 从更多人的直接参与中获益良多。最近迁移到 GitHub 更凸显了让这一过程变得更容易的紧迫性。
为此,我计划实施以下几种策略:
-
将代码拆分为模块。 这是许多其他项目自然演进的趋势;我并非 Linus 或 Guido,但正如他们的项目随着流行度增长,原始作者逐渐聚焦核心功能,而让他人扩展周边但同样重要的功能一样,我也希望将更多时间集中在核心功能上,例如支持结算日期、货币账户、拆分交易、交易报告等。让其他人负责添加或更新价格源、改进导入框架、以及制作美观的数据渲染和展示,将是理想的状态。随着时间推移,我可能会将这些库拆分为独立的仓库,采用更宽松的贡献规范,或为他人添加直接推送至这些仓库的访问权限。
-
招募“副手”。 我需要为值得信赖且频繁贡献的参与者留出更多空间,让他们更自由地参与贡献。例如,Martin Michlmayr 现在已获得大多数文档的直接编辑权限,并持续为文档做出大量有益的修改和更新。Kirill Goncharov 将文档从 Google Docs 迁移出来的成果堪称完美。RedStreet 及许多其他人定期在邮件列表中提供解答。Stefano Zacchiroli 和 Martin 已开发出一个独立的 Ledger 转换工具。Daniele Nicolodi 正在提议对扫描器和解析器进行一些底层改进。当然,Dominik Aumayr 和 Jakob Schnitzer 仍在持续开发与 Beancount 相关的 Fava 项目。还有更多人参与其中,熟悉且持续出现的名字正缓慢但稳定地增加。
我心中疑问是:我们是否能与这些常驻贡献者建立沟通渠道,以确保在设计方向上保持一致,并协同推进工作?新冠疫情带来的视频会议经验,是否为我们提供了一个此前不存在的新协作渠道?Python 社区之所以蓬勃发展,很大程度上得益于参与者每年面对面的交流,以及核心开发者长时间聚集在同一地点。作为规模更小的社区,我们能否在线上实现类似效果?如果可以,更好的协调或许能降低接受新提案的难度。我是否应该提议每月举行一次“团队”会议?
-
20% 项目。 我应列出一组与项目发展方向高度契合的“20% 项目”,供他人自愿认领,并为这些提议功能提供详尽的指导和下游影响说明。目的是让新手能够贡献那些易于被接受并顺利集成到代码库中的修改。
-
提案机制。 Beancount 对应于 Python 的“PEPs”的机制,本质上是我从多个讨论帖中发起的 Google Docs 提案文档,其他人可在其中评论和补充建议。这些提案应集中存放在一个文件夹中,并明确标识,以便他人也能撰写类似的提案。或许为这些提案增加一些结构和规范会更有帮助。
重构代码
从宏观层面看,Vnext 版本的代码重构大致如下:
-
C++ 核心、解析器和内置插件。 Beancount 的核心、解析器、记账算法及插件将重写为简洁的 C++ 代码,并以 protobuf 对象流的形式输出解析和记账后的结果。
-
查询引擎。 Beancount 的查询/SQL 功能将被分离为一个独立项目,支持任意数据结构,其应用范围远超 Beancount。详见下文。
-
其余部分。 其余大部分代码将被拆分为独立项目,或至少首先在代码库中划出独立区域(直至核心部分重写完成)。
请注意,由于核心输出的是 protobuf 对象流,任何支持 protobuf 的语言都能读取这些数据,从而扩展了 Beancount 的适用范围。以下是一个简化的示意图,展示其可能的结构:
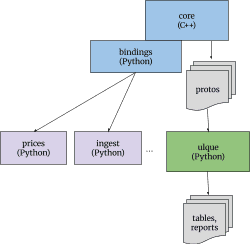
以下是当前代码库各部分的详细分解,以及我对它们未来走向的设想:
-
核心。 这是 Beancount 代码中将被重写为 C++ 的部分,输出一系列指令消息到流中。我将继续专注于这一部分,以保守的态度确保稳定性,但在 Vnext 版本中,将添加本文下一节所述的此前缺失的所需新功能。核心将包含以下包:
-
beancount/core
-
beancount/ops
-
beancount/parser
-
beancount/utils
-
beancount/loader.py
-
beancount/plugins(部分,见下文)
-
beancount/utils(大部分)
-
-
查询。 查询语言将被拆分为一个完全独立的仓库,具有更广泛的应用领域(并提供用于 Beancount 定制的扩展接口)。我预计随着时间推移,该项目将吸引大量贡献者,其中许多人甚至不是 Beancount 用户。这包括来自以下包的代码:
-
beancount/query
-
beancount/tools
-
-
价格。 这是一个简单的库和工具,帮助用户从外部来源获取价格。它应 definitely 移至另一个仓库,我欢迎新的维护者构建一个竞争性解决方案。人们不断向我提交新增价格来源的补丁,但由于上游来源频繁变更甚至消失,我已没有足够时间长期维护。从理论上讲,该工具几乎不需要 Beancount 本身的支持(你甚至可以直接用 print() 输出指令,无需加载任何库代码),但我认为 Beancount 核心应包含用于从特定账本中枚举指定日期所需日期/工具对的函数(我很乐意提供支持)。请注意,内部价格数据库的核心仍保留在核心中,因为其是必需的。受影响的包包括:
- beancount/prices
该库移出 Beancount 仓库后应进行改进:我们应将 Beancount 相关代码隔离到少数几个模块中,并将项目范围扩展到超越 Beancount 本身:它实际上包含三个部分:
a) 一个由社区维护、包含单元测试的最新 Python 价格获取库(即当数据源失效时,我们更新库),并提供统一的 API 接口(目前的 API 实际上需要大幅改进,应支持单次调用获取时间序列数据);
b) 一个配套的命令行工具(currency "bean-price"),用于从命令行获取这些价格。这需要将“从特定来源获取特定货币的价格”表示为字符串。我希望改进该规范,使 USD: 前缀变为可选,并可能完全移除价格链(该功能在实践中极少被使用,应将此逻辑上移);
c) 将获取账本相关信息的接口(例如缺失/所需价格列表、工具列表)封装为模块:支持 beancount v2、beancount Vnext、ledger、hledger,并能输出至任意这些格式。换句话说,该库即使在未安装 Beancount 的情况下也应能独立运行。目标是将此项目转变为一个可脱离 Beancount 独立运行的工具。
-
数据导入。 导入器库可能会迁移到另一个仓库,最终甚至可能找到新的维护者。我认为其中最有趣的部分是确立了清晰的阶段:识别、提取和文件处理任务,以及一个基于真实输入文件、对比预期转换输出的回归测试框架,这套机制有效减少了导入器升级时因故障带来的困扰(它们确实经常出问题,真是个麻烦事)。过去,我曾不得不使用一些技巧,使项目提供的命令行工具既能支持以 Python 代码形式输入配置,又能集成到脚本中;现在我将移除这些通用程序,要求用户将配置本身改写为一个脚本,运行时仅提供子命令;这一改动对现有用户来说非常简单:只需在现有文件底部添加一行代码即可。Bazel 构建系统在从机器全局的 Python 安装中加载位于 Bazel 工作区内部构建的 Python 扩展模块时,可能会带来一些小困难,但我相信我们能解决。我也很乐意有人最终接手这个框架,只要基本功能和 API 保持稳定即可。
示例的 CSV 和 OFX 导入器应从本库中移除,并独立存放于各自的仓库中,例如:-
OFX。 OFX 导入器应替换为基于 ofxtools 的实现(我之前写的那个相当糟糕),而 CSV 导入器则亟需彻底重写,并为它目前支持的大量选项添加充分的单元测试(这些测试目前严重缺失)。
-
CSV。 此外,我认为 CSV 导入器可以增强,变得更智能、更灵活,能够根据列标题和文件中推断出的数据类型,自动判断各列应映射到哪个字段。我不会做这件事(我没时间)。如果有谁想打造终极的自动 CSV 解析器,应该为此创建一个独立的仓库。
-
The affected packages are:
-
beancount/ingest:未来可能迁移到其他仓库。
-
beancount/ingest/importers:有人可以复兴一个导入器实现的仓库,类似于当年 LedgerHub 的目标,并吸纳这些代码。
有关导入代码后续安排的详细信息,请参阅此文档。
-
自定义报表和 bean-web 应被移除:底层的bottle 库目前似乎已无人维护,Fava 已取代 bean-web,而我从来就不喜欢自定义报表的代码(修改起来很麻烦)。我自己早已不再使用它们(除了通过 bean-web 间接使用)。我相信完全可以使用增强的 SQL 查询结果加上过滤器来替代它们。从 Beancount 转换为 Ledger 和 HLedger 的功能现在看来基本无用,我不确定是否还有人使用。我可能会将这些功能移至另一个仓库,任其逐渐废弃;或者,如果有人关心,可以接手并继续维护或演进它们。
-
beancount/web:将被删除或移至其他仓库。
-
beancount/reports:将被删除或移至其他仓库。
-
请注意,这包括弃用
beancount/scripts/bake,它严重依赖 bean-web。我目前没有 bean-bake 的替代方案,但我希望未来能开发一个更好的工具,直接将用户提供的特定 SQL 查询结果渲染为 PDF 文件并整合输出,便于打印。
Jupyter notebook support. A replacement for the lightweight interface bean-web used to provide could be Jupyter Notebook integration of the query engine, so that users can run SQL queries from cells and have them rendered as tables, or perhaps a super light web application which only supports rendering general SQL queries to tables.
- 内置插件。 Beancount 在
beancount/plugins下提供了一组内部插件。虽然未明确说明,但其中已演化出两类插件:一类是核心使用的稳定插件,另一类是展示新想法的实验性插件,这些插件通常是邮件列表中某条提议的不完整实现。前者将被移植到 C++,而后者应迁至另一个位置,并采用更宽松的接受标准。
First, there are "meta-plugins" which only include groups of other plugins: Only one of those should remain, and maybe be enabled by default (making Beancount pedantic by default):
-
auto
-
pedantic
The following plugins should remain in the core and be ported to C++:
-
auto_accounts
-
check_closing
-
check_commodity
-
close_tree
-
commodity_attr
-
check_average_cost
-
coherent_cost
-
currency_accounts
-
implicit_prices
-
leafonly
-
noduplicates
-
nounused
-
onecommodity
-
sellgains
-
unique_prices
The following are the experimental implementations of ideas that should move to a dedicated repo where other people can chip in other plugin implementations:
-
book_conversions
-
divert_expenses
-
exclude_tag
-
fill_account
-
fix_payees
-
forecast
-
ira_contribs
-
mark_unverified
-
merge_meta
-
split_expenses
-
tag_pending
-
unrealized
Because it's a really common occurrence, the new transfer_lots plugin should be part of the built-in ones.
-
项目。beancount/projects 目录包含一个导出脚本和一个用于生成遗嘱数据的项目。遗嘱脚本将被移出 Beancount 的核心部分,我不确定是否有人在使用它。也许新的外部插件仓库可以包含该脚本以及我在 /experimental 下共享的其他脚本。导出脚本应与 beancount/scripts/sql 及其他将数据导出/共享出账本的方法归为一类;这些脚本可以保留在核心中(我经常使用导出脚本将我的汇总数据和股票敞口同步到 Google Sheets 文档,以反映盘中变化)。
-
脚本。 一些脚本与 Beancount 完全无关,它们是配套工具。例如:网页抓取验证器、上传到 Sheets 的脚本、treeify 工具。这些应被移至其他位置。
将所有代码放在同一个仓库中的优势之一是,可以通过一次提交同步整个代码库的 API 变更。因此,在新的 C++ 核心稳定之前,我可能会保留部分代码在同一个仓库中,仅在 Vnext 发布时再正式分离。
通用轻量级查询引擎 (ulque)
Beancount 的 SQL 查询引擎最初只是一个原型,但已发展成为提取数据的主要方式。我在需要时已相当自由地为其添加了诸多功能,现在是时候整理并考虑一个更完善的解决方案了。
在 Vnext 中,查询/SQL 代码最终将被分离为一个独立项目(及独立仓库),该系统支持任意数据模式(通过 protobuf 作为各种数据源的通用描述),并具备 Beancount 集成支持。想象一下,你可以自动从任意 CSV 文件推断出模式,并在其上执行操作——无论是作为 Python 库函数,还是作为独立工具。此外,该工具将支持与 Google Sheets、XLS 电子表格、序列化 protobuf 二进制流容器、HTML 网页表格、PDF 文件、文件目录等多种数据源/目标进行交互。这将是一个数据处理工具,其范围更接近 Pandas 库,而非专注于会计的项目,同时也是一个通用转换工具,将包含 upload-to-sheets 脚本的功能(该脚本将被移除)。Beancount 的 SQL 查询引擎的一个经验是,只需少量后处理(例如 treeify),我们就能通过带过滤和聚合的查询完成 Beancount 中的大部分操作(如日记账、资产负债表和损益表)。
该工具将根据 Beancount 所需的某些特殊需求进行扩展,具体包括:
-
对 Decimal 类型 的原生支持。
-
添加具有
beancount.core.Inventory/Position/Amount语义的 自定义聚合器类型。 -
能够自动生成动态列,逐行聚合另一列(或其集合),即一个 “余额”列。
-
能够在结果表末尾渲染聚合的“总计行”。
-
用于拆分聚合列的功能,将金额和库存拆分为多个列(例如,"123.00 USD" 变为两列:(123.00, "USD"),以便在电子表格中处理;同时将借方和贷方拆分为独立的列。特别是,应通过 SQL 查询自然地打印账户中累积的多个批次,用更标准的数组类型拆分替代现有的 "flatten" 功能。
此外,通过新的项目定义扩大关注范围,将促使我们彻底测试该功能(当前版本仍处于原型阶段,所需测试数量远远不足),并引入数据类型验证(不再出现运行时异常),通过实现类型化的 SQL 转换器来实现。我将在其他地方记录这些内容。这是一个更大的项目,但我相信,随着范围的扩大,它将更容易测试,并具备独立发展的潜力。
我正在准备一份关于此的设计文档。
API 重构
我编写了大量自定义脚本,当前 Beancount API 存在若干令我困扰的问题,我希望对其进行彻底改进:
- 将符号统一归入 "bn" 命名空间。 内部 API 目前需要分别从每个包中导入符号,但既然我已将数据导入和报告代码分离,所有公共 API,或至少核心中常用的主要对象,都应从单一包中提供,类似于 numpy:
import beancount as bn
…
bn.Inventory(...)
bn.Amount(...)
bn.Transaction(...)
# etc.
我希望 "bn" 成为我们编写所有脚本时默认使用的两字母导入名称。
-
构造函数中提供默认值。 namedtuple 容器非常出色,但其构造函数从未支持可选参数,创建这些容器时总是需要传入大量 "None" 值,这让我很不习惯。我们将在下一版本中使其更简洁。
-
缺乏 API 文档。 尽管项目周围已有大量文档,但缺少指导用户如何使用 Python API 的说明,例如:如何累积余额、如何创建和使用实现树、如何从累积库存对象中提取信息等。我认为,记录一些最常用的操作将极大帮助用户充分挖掘 Beancount 的潜力。这些操作包括:
-
累积库存中的多个批次并打印它们。
-
转换为市场价值,并进行相应的账户调整。
-
…. 添加更多 …
-
-
公开且可用的记账功能。 记账将是一个简单的循环,可通过 Python 调用,传入一条记录和累积状态。此外,Inventory 对象应开始实现记账所需的部分底层操作,使得遍历一组分录并执行如平均记账等操作时,可通过 Inventory 对象的方法调用来完成。Inventory 应在 API 中占据更核心的地位。
-
数据类型。 所有对象都应提供明确的数据类型,以便在所有新代码中广泛使用 typing 模块。或许可创建一个名为 "bn.types" 的模块,但这些类型应直接从 "bn.*" 导入,以确保仅需一个简短的导入名称。
-
术语统一。 我希望在 Vnext 版本中停止使用 "entries",统一采用 "directives" 这一名称。
-
实现。 我一直将
collections.defaultdict(Inventory)和“实现”这两个术语混用。它们都是从账户名称(或其他键)到 Inventory 状态对象的映射。我希望将这两个结构统一为“实现”,并将其打造成一个常用对象,附带一些辅助方法。
解析器重写
由于我们将依赖 C++,解析器将被重写。无需担心:输入语法将保持不变,或至少与现有的 v2 解析器兼容。变化如下:
-
Unicode UTF-8 支持。 词法分析器将使用 RE/flex 代替 GNU flex 重写。此扫描器生成器原生支持 Unicode,所有输入标记都将支持 UTF-8 语法。这应包括账户名称——这是一个长期被请求的功能。
-
标志。 当前的扫描器限制了我们支持标志的能力,仅支持一小部分标志。我认为目前的列表已足够使用,但由于我将投入精力开发新的扫描器,我希望清理这一设计,支持更广泛、定义更清晰的单字母标志集,用于交易。
-
时间。 解析器将解析并提供时间字段,而不仅仅是日期。时间可作为排序指令的额外键使用。具体细节尚未确定,但鉴于该功能被频繁请求,至少解析器会将其作为元数据输出,最佳情况下,它可能成为一级功能。
-
缓存。 将移除 pickle 缓存。直到最近,禁用缓存的选项(环境变量)非常有限,我更愿意移除 Beancount 作为副作用所支持的仅有的两个环境变量。由于 C++ 代码应足够快速,缓存可能不再需要。
-
标签与链接。 实际上,这两个功能与元数据(用于过滤交易)的作用非常相似。我正在考虑取消标签和链接的特殊地位,转而将它们合并为元数据;输入语法不会被移除,但其值将被合并到元数据字段中。我尚未完全确定是否这样做,欢迎讨论。此外,解析器应允许在当前声明元数据的位置使用 #tag 和 ^link,这将提供更便捷的语法。最后,用户表达了对交易条目添加标签的需求,我们也应考虑这一点。
-
插件配置作为 Protobuf。 各插件的选项目前被松散地定义为可执行的 Python 代码。这种方式过于松散,不利于插件进行验证或记录预期输入。我希望通过在输入语法中支持文本格式的 Protobuf(由插件自身提供消息类型)来规范化插件配置语法。
-
C++ 解析器。 解析器将被重写为 C++。在开发 Vnext 的过程中,我将尽可能长时间地保持两个版本使用同一语法,通过调用一个 C++ 驱动接口实现:一个用于 V2 版本,调用 Python;另一个用于 Vnext 解析器,生成 Protobuf。在此过程中,我可能会将词法分析器和语法的 Python 实现移植为 C,如此工单中所述。
-
改进包含机制。 当前的包含机制无法识别不在顶层文件中的选项,这在过去引发了诸多意外,必须加以修复。至少应抛出错误。
代码质量改进
-
将所有地方的“augmentation”和“reduction”重命名为“opening”和“closing”。 这是更通用的术语,对外部用户而言更熟悉、更易理解。
-
类型注解。 在 Python 3 中使用 mypy 或 pytype 进行类型注解如今已非常普遍,且效果良好。作为 Vnext 的一部分,所有核心库都将添加类型注解,并在构建过程中自动运行 pytype。我需要将此功能添加到我们的 Bazel 规则中(目前 Google 尚未提供外部支持)。在此过程中,我可能会放宽部分 Args/Returns 文档规范,因为在许多情况下(但并非全部),类型注解已足以清晰表达函数的 API。
-
在构建中集成 PyLint。 同样,代码检查工具应作为构建流程的组成部分运行。我希望找到一种方法,使开发期间可以有选择性且明确地禁用它,但默认情况下,代码检查错误应等同于构建失败。
-
Python API 的灵活构造函数。 collections.namedtuple() 或 typing.NamedTuple 生成的类型不支持带命名参数的灵活构造函数。我认为当前所有创建交易对象的代码都将受益于带有默认值的构造函数,我将为此提供相应的 proto 对象构造方法。
容差与精度
关于精度和容差的处理方式一直不尽如人意,原因有二:
-
显式容差选项。 我曾尝试将容差(用于平衡交易)设计为自动推断,依据输入数字的统计信息自动确定。但效果不佳。在 Vnext 中,我计划为每种货币提供显式设置容差的选项。
-
精度。 在 v2 中,数字在多个地方被渲染:报表代码、SQL 查询和调试脚本,但精度的设置方式并未保持一致。用户还应能显式设置精度。
-
四舍五入。 在插值过程中还会使用另一个量:用于对计算结果进行四舍五入的精度。
此外,当数字用作价格与用作单位时,其精度和容差需要区分(参见 此处)。一种方法是按货币对(currency pair)而非单个货币存储显示上下文。
这些量之间的区别尚未得到充分记录;我将在 Vnext 中明确标注相关代码,并补充相应文档。大多数情况下,精度属于渲染层面的问题,也是新通用 SQL 查询工具的关键参数。
一些先前的设计文档请参见 此处。
核心改进
以下讨论了新功能的一些期望目标。这些均与核心功能相关。请注意,这些改动不应显著影响当前的使用方式,甚至完全不影响。我预计 v2 用户将基本不受影响,无需修改其账本文件。
预订规则重设计
当前预订系统的一个问题是,增加仓位和减少仓位在本质上必须采用不同的方式。增加仓位必须通过 {...} 语法提供成本基础,而减少仓位则必须在注释中输入价格,而非成本基础。例如:
2021-02-24 * "BOT +1 /NQH21:XCME 1/20 FEB 21 (EOM) /QNEG21:XCME 13100 CALL @143.75"
Assets:US:Ameritrade:Futures:Options 1 QNEG21C13100 {2875.00 USD}
contract: 143.75 USD
...
2021-02-24 * "SOLD -1 /NQH21:XCME 1/20 FEB 21 (EOM) /QNEG21:XCME 13100 CALL @149.00"
Assets:US:Ameritrade:Futures:Options -1 QNEG21C13100 {} @ 2980.00 USD
contract: 149.00 USD
...
请注意,从用户的角度来看,卖出交易的写法必须与常规不同。这使得导入器编写者难以处理,同时也把所需的语法与所应用的库存状态绑定在一起,因为它对库存做了一些假设。
此外,这使得编写能够处理绝对仓位交叉的导入器变得困难,例如:
2021-02-19 * "BOT +1 /NQH21:XCME @13593.00"
Assets:US:Ameritrade:Futures:Contracts 1 NQH21 {271860.00 USD}
contract: 13593.00 USD
Assets:US:Ameritrade:Futures:Margin -271860.00 USD
Expenses:Financial:Commissions 2.25 USD
Expenses:Financial:Fees 1.25 USD
Assets:US:Ameritrade:Futures:Cash -3.50 USD
2021-02-19 * "SOLD -2 /NQH21:XCME @13590.75"
Assets:US:Ameritrade:Futures:Contracts -2 NQH21 {271815.00 USD}
contract: 13590.75 USD
Assets:US:Ameritrade:Futures:Margin 543630.00 USD
Income:US:Ameritrade:Futures:PnL 45.00 USD
Expenses:Financial:Commissions 4.50 USD
Expenses:Financial:Fees 2.50 USD
Assets:US:Ameritrade:Futures:Cash -52.00 USD
这里的问题是我们正在穿越平仓线,换句话说,我们从持有多头一个单位变为持有空头一个单位。目前只有两种正确实现的方法:
-
禁用预订,仅使用成本,如上所述。这并不理想——预订功能非常有用。
-
在导入器中跟踪仓位,并将减少和增加的分录分开:
2021-02-19 * "SOLD -2 /NQH21:XCME @13590.75"
Assets:US:Ameritrade:Futures:Contracts -1 NQH21 {} @ 271815.00 USD
Assets:US:Ameritrade:Futures:Contracts -1 NQH21 {271815.00 USD}
这两种方案都不理想。因此,我提出了一种新方案:彻底重新评估语法的解释方式。实际上,这是一种简化。
What we can do is the following: use only the price annotation syntax for both augmentation and reduction and currency conversions, with a new booking rule —
-
优先匹配无成本基础的批次。如果批次没有成本基础,则该分录的权重仍为转换后的金额,与之前一致。
-
如果匹配到了具有成本基础的批次,则该分录的权重由所匹配批次所隐含的权重决定。
-
将 {...} 仅用于消除批次匹配的歧义,除此之外不做其他用途。如果你的匹配是明确的,或采用灵活的预订策略(如先进先出法),你几乎永远不需要使用成本匹配减少功能。
有了这一改动,上述期货交易将对两种分录都仅使用 @ 价格注释语法。它将
-
显著简化导入器的编写
-
原生支持期货交易
-
与现有货币兑换和投资输入完全向后兼容。
它在保持 Beancount 提供的严格约束的同时,对 Ledger 用户而言也更具一致性与友好性。我认为这种设计甚至更易于理解。
此外,这一写法:
Assets:US:Ameritrade:Futures:Contracts -1 NQH21 {} @ 271815.00 USD
将被解释为:"匹配此批次,但仅限那些附有成本基础的批次。"
一个遗留问题是:现在仅用 @ 价格注释书写的增加分录,是否应将成本基础存储到库存中?我认为我们可以按商品或按账户来决定这一点。这将引入一项新约束:某个商品(或“在某个账户中”)必须始终带有成本基础,或始终不带成本基础。
分录日期与结算日期
当您在单一账本内导入多个账户之间的交易时,例如从支票账户支付信用卡账单,交易在各账户中的记账日期可能不同。一方称为“交易日期”或“记账日期”,另一方称为“结算日期”。在此期间资金实际处于一种模糊状态(实际上并无资金流动,只是机构间会计记录存在差异,信息不会立即同步)。
当前核心代码的主要缺陷之一是,无法插入具有不同记账日期的单笔交易。建议用户选择一个日期,并人为调整另一个日期。关于此话题此前已有讨论此处。然而,这种方法使得至少在一个账户中无法准确反映真实的记账历史。
Vnext 版本中必须提供一个良好的解决方案,因为这是一个非常普遍的问题,我希望提供一个系统,能够精确还原您实际的账户历史。自动插入转移账户以暂存商品的功能可以作为一项特性实现,并应纳入核心功能中。
一种可能的思路是允许可选的记账日期,如下所示:
2020-01-19 * "ONLINE PAYMENT - THANK YOU" ""
Assets:US:BofA:Checking -2397.72 USD
2020-01-21 Liabilities:US:Amex:BlueCash 2397.72 USD
这将在后台生成两笔交易,如下所示:
2020-01-19 * "ONLINE PAYMENT - THANK YOU" ""
Assets:US:BofA:Checking -2397.72 USD
Equity:Transfer
2020-01-21 * "ONLINE PAYMENT - THANK YOU" ""
Liabilities:US:Amex:BlueCash 2397.72 USD
Equity:Transfer
这种不对称性引发了一个问题:我们是否应允许无日期的交易?
* "ONLINE PAYMENT - THANK YOU" ""
2020-01-19 Assets:US:BofA:Checking -2397.72 USD
2020-01-21 Liabilities:US:Amex:BlueCash 2397.72 USD
我认为我们可以解决这个问题,第一种方案是完全可行的。
输入拆分交易
一些用户喜欢将输入组织在不同文件中,或在不同章节中严格按顺序包含某个账户的所有交易。这与记账日期和结算日期问题精神相通:目前用户必须选择其中一个位置来插入交易。
这并非必要。我们应该提供一种机制,允许用户将一笔交易的两部分分别插入文件中的两个不同位置,并提供一个稳健的合并机制,确保这两笔相关交易已被正确匹配和合并(避免残留未合并的部分),否则应清晰报告错误。
这两部分可以如下所示:
2020-01-19 * "ONLINE PAYMENT - THANK YOU" ""
Assets:US:BofA:Checking -2397.72 USD
…
2020-01-21 * "AMEX EPAYMENT ACH PMT; DEBIT"
Liabilities:US:Amex:BlueCash 2397.72 USD
匹配可通过显式插入特殊链接实现,或通过启发式方法匹配所有相关交易(例如声明有效的账户对、基于日期差异设定阈值、精确匹配金额)。若无法匹配,应抛出错误。这些合并后的交易应进行平衡性检查。
请注意,每笔交易的日期均不同;这将与上一节提出的转移账户解决方案集成。
我尚未设计具体方案,但这一功能应易于实现,并作为核心功能提供,因为它与输入语法密切相关。
货币账户而非单一兑换
当前的多币种交易实现依赖于一种特殊的“兑换交易”,该交易在报告时(即年末结账时)自动插入,以核算不同币种之间的不平衡总额。此交易的目标是确保:如果你将账簿中的所有分录相加,结果将仅为一个空的库存(而不是因不同汇率兑换而产生的残余利润或亏损——请注意,我们仅讨论 @price 语法,而非投资)。这有点像是一个临时方案(该交易本身并不平衡,它通过转换为一种虚构货币的零金额来悄悄通过平衡检查)。此外,其实际数值依赖于对一组过滤后的交易进行求和,因此它是一个报告层面的构造,详见 此处。
存在一种无需牺牲单笔交易封闭性的多币种处理方法,该方法在 在线此处 有描述。使用该方法,你可以筛选任意一组交易,求和后将干净地抵消所有批次。你无需插入额外的调整项来修复平衡。此外,你可以明确地将利润记入货币账户的累计收益中,并将其清零,以便在报告时(以及长期追踪时)利用这一机制。缺点是,任何货币兑换都会导致额外的分录被插入等。
2020-06-02 * "Bought document camera"
Expenses:Work:Conference 59.98 EUR @ USD
Liabilities:CreditCard -87.54 USD
Equity:CurrencyAccounts:EUR -59.98 EUR
Equity:CurrencyAccounts:USD 87.54 USD
问题是,手动使用这种方法非常繁琐,需要过多的额外输入。我们完全可以由 Beancount 在后台自动完成这些操作。我已编写了一个概念验证实现,详见 此处,但 它尚未完成。
在 Vnext 中:
-
应移除这种临时性的兑换交易的插入机制。
-
货币账户应成为标准做法。由于两类指令将被清晰分离,这有助于更明确地区分解析表示与完全记账后的表示,后者会在交易中显示这些额外的分录。
-
应完成该原型并彻底修复所有问题(工作量并不大)。
严格收款方
我不确定这是否合理,但我希望清理当前收款方字符串的混乱状态。收款方是自由格式的,如果用户不主动清理它们——而我正是其中之一——那么从导入源获取的备注就会变得杂乱无章。
可以创建一个新的指令,预先声明收款方名称,并可选地要求所有收款方必须存在于已声明的收款方列表中。收款方应具有起止日期,用于定义与该收款方关系的有效期限(从而增强错误验证能力)。
从数据库推断价格
从价格数据库插值。 一个经常被请求的功能是能够自动从内部价格数据库的历史记录中插值价格。我认为这可以清晰且确定地实现,并集成到插值算法中。
价格验证。 由于许多基于价格的兑换(即使用 "@")是通过省略其中一个数值推断出来的,我们应验证实际价格是否在临近日期的预存价格点的容差范围内。这将提供另一层校验机制。
量化运算符
语法中另一个有用的补充是能够自动将其结果量化为依赖于特定目标货币精度的运算符。例如,
1970-01-01 * "coffee"
Expenses:Food:Net 2.13 / 1.19 EUR
Expenses:Food:Taxes 2.13 / 1.19 * 0.19 EUR ; for example to calculate tax
Assets:Cash
这将变为:
1970-01-01 * "coffee"
Expenses:Food:Net 1.789915966386555 EUR
Expenses:Food:Taxes 0.340084033613445 EUR
Assets:Cash
如果提供类似这样的运算符,就能解决这个问题:
1970-01-01 * "coffee"
Expenses:Food:Net 2.13 /. 1.19 EUR
Expenses:Food:Taxes (2.13 / 1.19 * 0.19). EUR
Assets:Cash
或者类似的方式。或者我们或许希望添加一个选项,使每个算术表达式的求值都自动进行此类量化。
约束系统与预算
Beancount 并未显式支持预算约束,但我认为可以通过扩展余额断言语义来实现这一功能。
当前的余额断言检查(a)单一商品,以及(b)金额是否精确等于预期值。余额断言应扩展以支持不等式,例如:
2020-06-02 balance Liabilities:CreditCard > 1000.00 USD
也许我们还可以像这样检查总资产库存:
2020-06-02 balanceall Assets:Cash 200.00 USD, 300.00 CAD
我很想知道从事预算工作的用户认为哪种方案最有效,并设计一个极简的表达式语言来支持这一用例(尽管我会尽量保持简单,以避免功能膨胀)。此外,如果语法需要修改,增加一种可以同时检查多种货币的语法,甚至一个完整的断言来检查账户中是否存在其他商品,也可能很有意义。
平均成本记账
平均成本记账方式早已被讨论过,并且很久以前就已勾勒出良好的解决方案。Vnext 应原生支持该方法;许多用户希望使用此功能来处理其税收递延账户。正确处理各种自动转换的精度需要一些工作。
其工作方式是在减少时自动合并同一商品的所有相关批次,也可选择在增加时合并。可能需要一些约束条件(例如,该账户中仅允许一种商品)。
交易匹配与报告
与损益和交易相关的一些核心任务仍需实现。
- 交易列表。 我长期以来一直想解决但始终未能抽出时间的一个问题是:在记账过程中保留一些线索,以便能轻松从指令列表中提取出正确的交易对列表。我很久以前在这里和这里写过一些笔记。本质上,对于每个已记账的减少项,插入一条指向对应增加项的引用。我已将其作为元数据进行了原型设计,但应使其成为更正式的功能。通过一次线性扫描即可收集这些引用,构建映射关系,并恢复(买入、卖出)交易对,从而生成交易表。我曾在一个插件中实现过类似功能。
Needless to say, producing a list of trades is a pretty basic function that Beancount does not provide out of the box today; it really should. Right now users write their own scripts. This needs to be supported out-of-the-box.
-
统一余额与收益验证。 检查交易是否平衡以及收益是否与交易价格匹配(sellgains 插件)这两项功能目前在完全独立的代码中实现。这两部分功能职责相似,应并排实现。
-
佣金计入损益。 目前无法通过扣除原始批次的买入佣金和卖出佣金来准确计算利润与亏损。我认为可以通过一个插件实现:将部分(计算出的)收益科目转移至一个独立的负收益科目,以便在报告中正确处理此事。
自减操作
目前,减量操作作用于交易前的库存。这阻止了常见的自减情况,而我与一些用户此前都遇到过这个问题,例如这个最近的讨论(工单)。对某些用户而言,这种行为显得不合直觉,应当有更好的解决方案,而非强制拆分交易。
由于我们将在 Vnext 中完全重写记账代码,因此应重新考虑一种新的定义,以在该情况下提供明确的行为。我记得之前尝试实现此功能时,发现定义起来并不简单。请重新审视。这将是一个不错的改进。
股票分割
在 Vnext 中,应制定一些讨论和处理股票分割的策略。目前,Beancount 忽略了这一问题。至少,可以将相关信息添加到价格数据库中。更多详情请参见此文档。
乘数
期权的标准合约规模为 100。期货的合约规模则因具体工具而异(例如,/NQ 的乘数为 20)。
我目前通过将期权的单位乘以 100,以及将期货的合约规模乘以每份合约的乘数(期权期货同理)来处理这个问题。我在导入器中完成这些操作。对于期权,这种方法可行且不算太糟(例如,持仓为 -300 而非 -3);但对于期货,结果显得很不直观,无法真实反映实际交易情况。
我希望添加每种货币的乘数,以及一个全局的正则表达式到乘数的映射字典,并在所有地方一致应用。一个挑战在于,所有涉及成本或价格计算的地方都必须应用此规则。在当前版本中,这些只是简单的乘法运算,因此代码库中许多部分尚未封装成可轻松修改的函数。这需要在一次大规模重写中完成——这正是实现它的绝佳机会。
收益计算
如果你查看现有的投资经纪商,没有一家能正确计算收益。经纪商通常提供以下两种功能之一:
- 不考虑现金转账。 当前账户总价值与过去某个时间点(如账户开立日或年初)的总价值之比。这并不可靠,因为它们从未考虑账户现金的存入或取出。例如,假设你用 100,000 美元开设账户并进行投资,年中又存入 20,000 美元,若原始投资现值为 95,000 美元,报告会显示盈利 15,000 美元,而实际上你已亏损。更好的经纪商(如 Vanguard)会显示叠加的柱状图,其中一条代表存入的现金,另一条代表利润,如下所示:
- 忽略利息或股息。 其他经纪商会报告投资的盈亏变化,但未计入实际收到的利息或股息(仅关注底层资产价格),因此对债券、高股息股票或随时间新增头寸的组合而言,这种计算方式毫无意义。
反事实表现。 最后,所有这些方法都未能将您的实际年化收益与具有同等现金流入的基准投资组合进行比较。例如,与其比较您实际进行的投资,不如根据这些工具的历史价格,比较如果您在该特定时期内投资于某个标准化投资组合会获得的收益。理想情况下,应能通过指定的现金转账定义任何可对比的替代投资组合。
更复杂的分析甚至未被考虑,例如,如果我改变再平衡策略(或实施更严格的策略),会产生什么影响?
对于基于时间或基于价值的收益报告,已有成熟的方法。正确做法是提取现金流的时间序列,并计算年化收益率或内部收益率(IRR),或采用价值加权法。
我曾在某个时候开始这项工作,但遇到了一些困难,最终将其移除了。相关结果仍保留在这里。我非常希望重新实现这一功能,未来或许它能发展为一个独立项目,并在 Beancount 核心中集成配套的支持函数。这可能成为一个独立项目,但需要类似获取价格所需的工具来枚举工具和价格源,以及用于隔离特定账户子集现金流的函数;这些功能应归属于核心模块。
UPDATE September 2020: This has mostly been implemented. See this document for details.
无符号的借方与贷方
一个有用且几乎无需额外工作即可实现的想法是:允许用户输入所有正数单位,并自动在输入时翻转符号,同时在输出时统一显示为正数,并将其分别分配到借方和贷方列中。这将使 Beancount 的界面更容易被有会计背景的用户理解。该功能不会引入任何复杂性,可免费轻松添加。参见 此处待办。
持仓
我曾开发过一个名为“持仓”的库,见此处。当时我不确定这种数据是否比记账条目包含更多内容,但后来发现,仅用记账条目表示持仓已足够,您只需要市场价值,从单位计算总价值非常简单。事实上,我已多年未使用那段代码,而是改用导出脚本,它会输出一个表格并上传至 Google Sheets 文档。这让我确信,在实践中,对 Inventory 中的持仓进行聚合,再结合最新的市场价格映射,已完全足够。
我将删除这段代码。它仅在报告代码中被使用,而报告代码本身也将被移除;此外,它还被用于实验性的“未实现收益”插件,该插件仅为概念验证,已让我确认将此类收益作为交易记录是不可取的,因此它也将被移除,并独立存放在一个实验性仓库中。
调试工具
上下文应能恢复错误交易。 错误恢复的一大困扰是:若某笔交易包含某些类型的错误,其记账条目将不会出现在指令流中。此问题源于解析后的数据结构与完全解析后的数据结构之间缺乏清晰区分。具体而言,这意味着“bean-doctor context”调试命令通常无法为失败的交易提供有用的上下文信息。这一点亟需修复,以提升可调试性。
文档调试工具。 一般来说,我应该更详细地说明如何使用各种交易调试工具;如果用户能更好地利用这些工具,邮件列表中的大量问题都会消失。
Emacs 中的交互式上下文。 如果性能允许,我们可以开发一个 Emacs 模式,它能在另一个缓冲区中实时渲染部分编写的交易周围的上下文,包括交易前后受影响账户的库存情况以及插值后的值。这将使数据输入更加有趣,并能即时反馈新插入交易的信息。
文档改进
移除对 furius.ca 的依赖。 当前基于 Google Docs 的文档通过全局重定向链接到其他文档(定义见此处)。虽然我的服务器每年宕机次数不多(可能只有几次),但一旦发生,修复需要数天时间。该服务器由我一些朋友慷慨托管。
Kirill 已证明,可以将所有重定向链接替换为 GitHub 上的链接,形式如下:beancount.github.io/<document>,而非 furius.ca/beancount/doc/<document>。为此,我需要使用Docs API编写脚本,自动修改所有 Google Docs 中的链接。
结论
更多内容见TODO 文件。以上只是我认为最重要、希望在 Vnext 重写中优先解决的主要问题。
开发分支将如下所示:
-
v2:当前的 master 将被分支为 "v2",用于跟踪稳定版本。
-
该分支将同时支持当前的 setup.py 系统和 Bazel 构建。
-
修复将在该分支上尽可能实现,并合并到 Vnext。
-
-
master:当前的 master 将成为 Vnext。
- 该分支仅支持 Bazel 构建。
欢迎提出任何意见。
附录
在后续讨论中产生的更多 Vnext 核心想法。
可定制的匹配
对于带有成本基础的转账批次……一个想法是创建一种新的钩子,由插件注册,例如由匹配代码本身调用的回调函数,其对交易的结果会立即反映在受影响库存的状态中。也许这是提供自定义算法的理想位置,以确保其影响能正确且即时地作用于后续库存。进一步推广这一思路,可将当前内置于核心的所有匹配机制都替换为可配置的实现,称之为“可定制匹配”。(线程)
琐碎的小问题
-
print_entry() 使用了缓冲机制,导致无法在不指定 file= 参数的情况下,将常规的 print() 与标准输出混用。请修复此问题,改为直接输出到标准输出,这样才更自然,当前行为令人困扰。
-
库存的 __str__ 默认格式在渲染结果外添加了括号 ()。当仅有一个持仓时,这看起来像一个负数,非常不合理。请改用 {} 或其他符号。
-
为 bean-check 添加一个标志,使其默认运行 --auto 插件。这对于导入的文件非常有用,因为这些文件可能没有完整的账本可供输入。
增量记账 / Beancount 服务器 / Emacs 配套工具
为了使重新计算更快,创建一个独立的“Beancount 服务器”的想法变得合理。在大型文件上进行 Beancount 计算时,最耗时的部分是记账和插值。提高速度的关键在于将所有原始未处理的交易连同已记账和插值后的交易保留在内存中;当文件发生更改时,重新解析修改的文件并扫描所有交易,仅更新受影响账户的交易。
理论上这可能存在问题:某些插件可能依赖于非局部效应,从而影响其输出。但我相信在实践中它 99% 的时间都能正常工作。不过,我认为值得做一个原型。另一方面,Vnext 可能已经足够快,能够每次都从头开始重新计算(我自己的文件在最大文件的解析阶段从 4 秒缩短到了 0.3 毫秒),因此这整体上可能无关紧要。
这样的服务器将与正在运行的 Emacs 完美配合。我们可以开发一个 Emacs 模式,与该服务器通信。
标签与链接合并到元数据中
TODO(blais): 添加冒号语法