
Beancount 查询语言
Martin Blais,2015 年 1 月
http://furius.ca/beancount/doc/query
引言
Beancount 的目标是让用户创建一个准确且无错误的财务交易表示,通常涉及用户或机构相关账户中发生的交易,然后从这些交易列表中提取各种报表。Beancount 提供了几种工具来从交易数据集中提取报表:自定义报表(使用 Beancount 的 bean-report 工具)、网页界面(使用 bean-web 工具),以及允许用户编写自己的脚本来输出任意所需内容。
财务交易的存储库始终从文本文件输入中读取,但一旦解析并加载到内存中,从 Beancount 中提取信息的方式就可以像操作其他数据库一样进行,也就是说,无需使用自定义代码从数据结构生成输出,而是可以编译并运行一个查询语言,对相对规整的交易列表进行查询。
实际上,你可以将交易明细扁平化并导入外部 SQL 数据库,然后使用该数据库的工具进行查询,但这种方法的效果相当令人失望,主要是因为缺乏对库存的操作,而库存正是 Beancount 中平衡规则的基础。通过提供一个专门针对复式记账结构优化的查询引擎,我们可以轻松生成符合会计目的的自定义报表。
本文档描述了我们专用的类 SQL 查询客户端。它假设您至少对 SQL 语法有一定了解。如果没有,请先阅读 一些 关于它的内容。
动机
因此,有人可能会问:为什么要创建另一个 SQL 客户端?为什么不将数据输出到 SQLite 数据库,然后让用户使用该 SQL 客户端呢?
我们确实已经这样做了(参见将 Beancount 账本转换为 SQLite 数据库的 bean-sql 脚本),但效果并不理想。编写查询很痛苦,对以成本持有批次的操作尤其困难。通过利用内存数据结构的几个特性,我们可以做得更好。因此,Beancount 自带了一个名为“bean-query”的类 SQL 查询客户端。
该客户端实现了以下对 Beancount 至关重要的“增强功能”:
-
它允许同时在两个层级上进行过滤:您可以过滤整个交易(这样能保持会计等式的完整性),然后通常为了展示目的,还可以在交易明细层级上进行过滤。
-
该客户端支持 Beancount 中实现的库存记账语义,并支持对库存对象进行聚合函数操作以及渲染函数(例如,使用 COST() 来显示库存的成本而非其内容)。
-
该客户端允许将多个批次扁平化为独立的交易明细,从而生成每项持仓及其关联成本基础的列表。
-
交易可以以有助于生成资产负债表和损益表的方式进行汇总。例如,我们的 SQL 变体明确支持一个“结账”操作,其效果类似于年度结账,即插入交易以将损益类账户清零并转入权益账户,同时清除历史记录。
另请参阅此帖子以获取类似答案。
警告与注意事项
在 2014 年底,原始设计文档中所期望的约 70% 功能已在查询语言中实现。要覆盖完整功能集仍需更多工作,但当前版本已支持 Ledger 和 Beancount 用户所涵盖的大多数用例。在继续之前,我们更希望收集关于当前版本的更多反馈,并计划在进一步完善查询语言之前,先改进 Beancount 的一些更基础的方面(特别是库存记账)。当前版本已具备可用性,但后续将根据用户反馈和长期使用经验进行第二轮修订。
因此,查询语言的第一个版本已合并至默认稳定分支。本文介绍了 Beancount 查询语言的这一初始版本。
编写查询
我们提供的自定义查询客户端称为 bean-query。您可以像这样在您的账本文件上运行它:
$ bean-query myfile.beancount
Input file: "My Ledger’s Title"
Ready with 13996 directives (21112 postings in 8833 transactions).
beancount> _
这将启动交互式查询工具,您可以在其中对加载到内存中的数据集输入多个命令。bean-query 会解析输入文件,输出账本的一些基本统计信息,并提供命令提示符供您输入查询命令。您可以在提示符下输入“help”查看可用命令列表。
如果您的账本中存在任何错误,它们将在提示符前显示。要抑制错误输出,请使用“no-errors”选项运行工具:
$ bean-query -q myfile.beancount
批处理模式查询
如果您希望直接从命令行运行查询而无需交互式提示符,可以在文件名后直接提供查询语句:
$ bean-query myfile.beancount 'balances from year = 2014'
account balance
----------------------------------------------------------------------
… <balances follow> …
所有交互式命令均受支持。
Shell 变量
交互式 Shell 提供了一些可自定义的“set”变量,用于调整 Shell 的部分行为。这些变量类似于环境变量。输入“set”命令可查看可用变量及其当前值。
可用变量包括:
-
format(字符串):输出格式。目前仅支持“text”。
-
boxed(布尔值):是否在输出表格周围绘制边框。
-
spaced(布尔值):是否在每一行结果之间插入空行。这仅在多笔分录可能需要多行显示时有意义,插入空行有助于清晰区分各条记录。
-
pager(字符串):当输出内容超过屏幕高度时,用于管道输出的分页程序名称。初始值从 PAGER 环境变量复制。
-
expand(布尔值):若为真,则展开在多行上渲染为列表的列。
交易与分录
交易和条目的结构可通过以下简化图示说明:
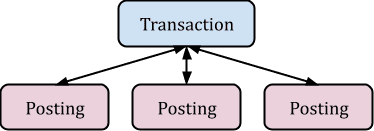
账本的内容被解析为一系列指令,其中大多数是包含两个或更多“记账项”对象的“交易”对象。记账项始终仅与单笔交易关联(它们不会在交易之间共享)。每个记账项都引用其父交易,但具有唯一的账户名称、金额、关联的批次(可能包含成本)、价格以及其他一些属性。父交易本身也包含一些有用属性,例如日期、收款人名称、说明文本、标记、链接、标签等。
如果我们忽略除交易之外的其他指令列表,可以将数据集视为所有记账项与其父交易连接后形成的一个单一表格。我们主要在此连接后的记账项表格上执行过滤和聚合操作。
然而,由于复式记账的约束——即附加到一笔交易的所有记账项金额之和为零——在交易级别执行过滤操作也非常有用。因为任何孤立的交易对全局余额的总影响为零,任何交易子集都会遵守会计等式(资产 + 负债 + 所有者权益 + 收入 + 费用 = 0),并对交易子集生成资产负债表和利润表具有实际意义,例如,可以通过标签选择“前往巴哈马旅行期间发生的所有资产变动和费用”。
因此,我们修改了 SQL SELECT 语法,提供两级过滤语法:由于我们只有一个数据表,我们将 FROM 子句中的表名替换为应用于交易的过滤表达式,而 WHERE 子句则作用于由此产生的记账项列表中的数据:
SELECT <target1>, <target2>, …
FROM <entry-filter-expression>
WHERE <posting-filter-expression>;
两个过滤表达式均为可选。若未提供任何过滤表达式,则会枚举所有记账项。请注意,由于交易始终按日期顺序过滤,结果默认将按此顺序处理和返回。
记账项数据列
目标列表指的是记账项或其父交易的属性。相同的“列”列表也适用于 <记账项过滤表达式>,用于按记账项属性进行过滤。例如,您可以编写如下查询:
SELECT date, narration, account, position
WHERE account ~ “.*:Vacation” AND year >= 2014;
此处,“date”、“year”和“narration”列指父交易的属性,“account”和“position”列指记账项本身的属性。
您可以使用熟悉的 AS 操作符显式命名目标:
SELECT last(date) as last_date, cost(sum(position)) as cost;
可用的完整记账项列及函数列表,最好通过在客户端中执行“help targets”或“help where”命令查看,该命令会打印出每个可用数据列及其数据类型。您也可以参考以下记账项对象结构图,了解列与数据结构属性之间的对应关系。
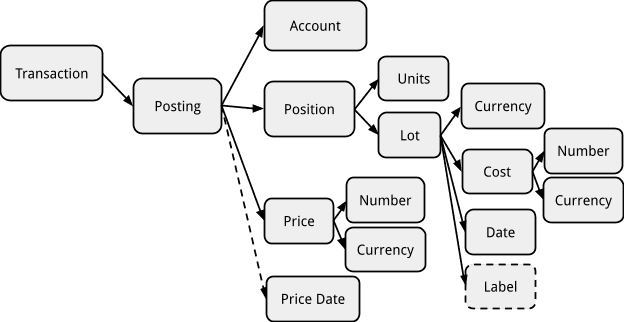
条目数据列
在 FROM 子句的 <条目过滤表达式> 中,提供了一组不同的列名。这些列指的是交易对象的属性。此子句旨在过滤整个交易(即全部记账项或一个都不选)。可用属性包括日期、交易标记、可选的收款人、说明、标签集合和链接。使用“help from”命令可查找此子句中可用的完整列和函数列表。
Beancount 输入文件由多种不同类型的条目组成,而不仅仅是交易。这些其他类型的条目(如 Open、Close、Balance 等)也可能提供可在 FROM 子句中访问的属性。目前这一功能尚处于初步阶段。(目前尚不清楚这些属性未来将如何使用,但我相信我们最终会发现一些有趣的用途。FROM 子句通过名为“type”的列提供对数据条目类型的访问。我们仍在探索如何更实际地利用 SQL 语言处理其他类型的指令。)
“id” 列
存在一个特殊列用于唯一标识每笔交易:“id”。它是由交易自动生成的唯一哈希值,在多次运行中保持稳定。
SELECT DISTINCT id;
此哈希值基于交易对象本身的内容派生(如果您更改了交易的任何内容,例如编辑了描述,id 也会随之改变)。
您可以使用此列进行打印和选择。它可用于调试,例如:
PRINT FROM id = '8e7c47250d040ae2b85de580dd4f5c2a';
“balance” 列
一种常见的期望输出是按时间顺序排列的条目日记(在 Ledger 中也称为“register”):
SELECT date, account, position WHERE account ~ "Chase:Slate";
对于此类报表,方便的是同时显示所选记账行的累计余额。访问前一行并非标准 SQL 功能,因此我们稍作创新,提供了一个名为“balance”的特殊列,该列根据之前所选行自动计算得出:
SELECT date, account, position, balance WHERE account ~ "Chase:Slate";
这使您能够生成典型的账户对账单,例如银行寄送给您的对账单。输出可能如下所示:
$ bean-query $T "select date, account, position, balance where account ~ 'Expenses:Food:Restaurant';"
date account position balance
---------- ------------------------ --------- ----------
2012-01-02 Expenses:Food:Restaurant 31.02 USD 31.02 USD
2012-01-04 Expenses:Food:Restaurant 25.33 USD 56.35 USD
2012-01-08 Expenses:Food:Restaurant 67.88 USD 124.23 USD
2012-01-09 Expenses:Food:Restaurant 35.28 USD 159.51 USD
2012-01-14 Expenses:Food:Restaurant 25.84 USD 185.35 USD
2012-01-17 Expenses:Food:Restaurant 36.73 USD 222.08 USD
2012-01-21 Expenses:Food:Restaurant 28.11 USD 250.19 USD
2012-01-22 Expenses:Food:Restaurant 21.12 USD 271.31 USD
通配符目标
使用通配符作为目标列表(“*”)将选择一组默认的列:
SELECT * FROM year = 2014;
要查看实际选择的列列表,可以使用 EXPLAIN 前缀:
EXPLAIN SELECT * FROM year = 2014;
数据类型
从记账行或交易中提取的数据属性具有特定类型。大多数数据类型是底层 Python 实现语言提供的常规类型,例如:
-
字符串(Python str)
-
日期(datetime.date 实例)。日期以
YYYY-MM-DD格式输入:SELECT * WHERE date < 2024-05-20。 -
整数(Python int)
-
布尔值(Python bool 对象),表示为
TRUE、FALSE -
数值(decimal.Decimal 对象)
-
字符串集合(Python str 对象的集合)
-
空值对象(
NULL)
头寸与库存
然而,我们之所以开发这个类 SQL 客户端,主要原因在于其能够对库存头寸(Beancount 核心数据结构,用于实现其平衡语义)执行聚合操作。Beancount 内部定义了 Position 和 Inventory 对象,并能将它们聚合为一个 Inventory 实例。在每个记账行上,“position” 列提取一个 Position 类型的对象,当对这些对象求和时,将生成一个 Inventory 实例。
Shell 能够正确显示这些对象。更具体地说,Inventory 对象可以包含多个不同的持仓批次,每个批次都会单独显示为一行。
头寸与库存数量
默认情况下,Position 类型的对象会以完整细节显示,不仅包括其数量和货币,还包括其批次的详细信息。库存由一批批次组成,因此默认也以类似方式显示为一个列表(每行一个头寸),每个头寸都显示完整细节。但通常这种细节过多。
命令行提供了若干函数,允许用户将头寸汇总为多种派生数量。派生数量的类型包括:
-
“
raw”:以完整细节显示头寸,包括成本和批次日期 -
“
units”:仅显示头寸的数量和货币 -
“
cost”:显示头寸的总成本,即单位数量 × 单位成本 -
“
weight”:显示用于平衡交易记账的金额。成本与权重的主要区别在于涉及价格转换的记账。 -
“
value”:显示基于最后一条记录的市场价值的金额
针对头寸或库存对象,提供了同名函数进行操作。例如,可以生成每个账户的最终余额表,如下所示:
SELECT account, units(sum(position)), cost(sum(position)) GROUP BY 1;
请参见下表,了解每种记账类型的明确示例及其转换和显示方式。
| 记账 | raw(完整细节) | units | cost | weight | market |
|---|---|---|---|---|---|
| 简单 | 50.00 USD | 50.00 USD | 50.00 USD | 50.00 USD | 50.00 USD |
| 含价格转换 | 50.00 USD @ 1.35 CAD | 50.00 USD | 50.00 USD | 67.50 CAD | 50.00 USD |
| 按成本持有 | 50 VEA {1.35 CAD} | 50 VEA | 67.50 CAD | 67.50 CAD | 67.50 CAD |
| 按成本持有并含价格 | 50 VEA {1.35 CAD} @ 1.45 CAD | 50 VEA | 67.50 CAD | 67.50 CAD | 72.50 CAD |
运算符
提供了常见的比较和逻辑运算符,用于操作可用的数据列:
-
=(相等),!=(不相等)
-
<(小于),<=(小于或等于)
-
>(大于),>=(大于或等于)
-
AND(逻辑与)
-
OR(逻辑或)
-
NOT(逻辑非)
-
IN(集合成员关系)
我们还提供了一个用于字符串对象的正则表达式搜索操作符:
- ~(正则表达式搜索)
目前,匹配组将被忽略。
您可以将字符串、数字和整数常量与这些操作符一起使用,并使用括号明确指定优先级。
以下是一个使用了部分上述操作符的查询示例:
SELECT date, payee
WHERE account ~ 'Expenses:Food:Restaurant'
AND 'trip-new-york' IN tags
AND NOT payee = 'Uncle Boons'
与 SQL 不同,bean-query 不为 NULL 实现三值逻辑。这意味着例如表达式 NULL = NULL 将返回 TRUE 而非 NULL,这简化了逻辑,但可能让经验丰富的 SQL 用户感到意外。
简单函数
该 shell 提供了一系列作用于单个数据列并返回新值的简单函数。这些函数针对特定类型操作。shell 实现了基本的类型验证,能够对不兼容的类型发出警告。
以下是一些示例函数:
- COST(Inventory), COST(Position):返回一个金额,表示头寸或库存的成本。
-
UNITS(Inventory), UNITS(Position):返回头寸或库存的单位。
-
DAY(日期), MONTH(日期), YEAR(日期):返回整数,表示记账或条目日期的天、月或年。
-
LENGTH(列表):计算列表或集合的长度,例如标签。
-
PARENT(账户字符串):返回父账户的名称。
以上仅为示例;完整列表请参阅“help targets”、“help where”、“help from”。
请注意,向此列表中添加新函数极其简单。截至 2014 年 12 月,我们才刚开始广泛使用该 shell,预计会根据需要不断添加新函数。如果您需要某个函数,请在此处留言或提交工单,我们会考虑将其加入列表(我们理解当前列表仍有限)。我倾向于宽松地添加新函数;只要它们具有通用性,我认为不应存在问题。否则,我可能提供一种机制,允许用户通过 Python 插件注册自定义函数,这些插件可独立于 Beancount 代码库存在。
聚合函数
某些函数作用于多行数据。这些函数对操作的数据列进行聚合和汇总。此类函数的典型用法是汇总库存中的头寸:
SELECT account, sum(position) WHERE account ~ 'Income' GROUP BY account;
如果查询目标包含至少一个聚合函数,则该查询将变为聚合查询(详见相关章节)。请注意,您不能在 FROM 或 WHERE 子句中使用聚合函数。
聚合函数的示例包括:
-
COUNT(...):计算所选记账条目的数量(整数)。
-
FIRST(...), LAST(...):返回首次或最后一次出现的值。
-
MIN(...), MAX(...):计算所见的最小值或最大值。
-
SUM(...):对每个集合的值求和。此函数适用于金额、头寸、库存、数字等。
对于简单函数,这只是一个初步列表。我们将根据需要添加更多函数。使用“help targets”可查看所有可用聚合函数的完整列表。
注意:您无法使用 WHERE 子句对聚合函数的结果进行过滤;这需要实现 HAVING 子句,但目前尚未支持 HAVING 过滤。
简单查询与聚合查询
查询分为两种类型:
-
简单查询,为每个符合 WHERE 子句限制条件的记账条目生成一行结果。
-
聚合查询,为每个符合 WHERE 子句限制条件的记账条目组生成一行结果。
如果查询的目标列表中至少包含一个聚合函数,则该查询即为“聚合查询”。为了确定聚合键,所有非聚合列都必须通过 GROUP BY 子句进行标记,如下所示:
SELECT payee, account, COST(SUM(position)), LAST(date)
GROUP BY payee, account;
您也可以使用目标的顺序位置来声明分组键,如下所示:
SELECT payee, account, COST(SUM(position)), LAST(date)
GROUP BY 1, 2;
此外,如果您为目标命名,可以直接使用目标的显式名称:
SELECT payee, account as acc, COST(SUM(position)), LAST(date)
GROUP BY 1, acc;
如果您具备初步的 SQL 知识,这些内容应该会感到熟悉。
最后,由于我们实现的是 SQL 的简化版本,且必须始终明确指定简单列,因此省略 GROUP BY 子句也应最终能正常工作,系统将隐式地按这些列进行分组,以提供便利。
去重
存在一个后过滤阶段,用于对结果行进行去重。您可以在 SELECT 后添加 DISTINCT 标志来触发此去重功能,这与 SQL 中的用法一致,例如:
SELECT DISTINCT account;
控制结果
排序(ORDER BY)
与 GROUP BY 子句类似,ORDER BY 子句用于控制结果行的最终排序:
SELECT …
GROUP BY account, payee
ORDER BY payee, date;
该子句是可选的。如果不指定,系统将使用默认的记账条目迭代顺序输出结果(即按日期排序的交易及其对应的记账条目顺序)。
与 SQL 一样,您可以通过添加 DESC 后缀来反转排序顺序(默认顺序等同于指定 ASC):
SELECT …
GROUP BY account, payee
ORDER BY payee, date DESC;
限制(LIMIT)
我们的查询语言还支持 LIMIT 子句,用于中断结果行的生成:
SELECT … LIMIT 100;
这将输出前 100 行结果后停止。虽然这是 SQL 中常见的子句,但在复式记账的上下文中用处不大:我们处理的数据集通常都很小。不过,我们仍提供此功能以保持完整性。
格式(Format)
对于 SELECT、JOURNAL 和 BALANCES 查询,默认输出格式为文本表格。我们支持 CSV 输出。(我们也可以轻松添加对 XLS 或 Google Sheets 输出的支持。)
然而,对于 PRINT 查询,输出格式为 Beancount 输入文本格式。
语句操作符
壳层提供了一些专门用于生成资产负债表和损益表的运算符。这些运算符的定义方法将在随 Beancount 附带的《复式记账法简介》文档中详细说明,该文档主要位于源代码的 summarize 模块中。
这些特殊运算符存在于壳层中各种查询命令的 FROM 子句中,它们会对 FROM 表达式在交易层级(而非分录层级)所选择的条目集进行进一步转换。
请注意,这些运算符并非标准 SQL 的一部分,而是此壳层语言独有的扩展功能。
开启期间
在特定日期开启一个会计期间,会将该日期之前的所有条目替换为汇总条目,这些条目将预期余额记入一个名为“期初余额”的权益账户,并通过将收入与支出账户的余额转移至一个名为“前期收益”的权益账户,隐式地将收入与支出清零(具体实现请参见 beancount.ops.summarize.open())。
调用方式如下:
SELECT … FROM <expression> OPEN ON <date> …
例如:
SELECT * FROM has_account("Invest") OPEN ON 2014-01-01;
如果需要,您可以仅查看插入的汇总条目,方式如下:
PRINT FROM flag = "S" AND account ~ "Invest" OPEN ON 2014-01-01;
关闭期间
关闭一个会计期间主要包括截断指定日期之后的所有条目,并确保货币兑换得到正确修正(具体实现请参见 beancount.ops.summarize.close())。
调用方式如下:
SELECT … FROM <expression> CLOSE [ON <date>] …
例如:
SELECT * FROM has_account("Invest") CLOSE ON 2015-04-01;
请注意,关闭日期应为希望包含的最后一条交易日期的后一天(这符合 Beancount 中普遍采用的约定:起始日期包含在内,结束日期不包含在内)。
关闭日期是可选的。如果未指定日期,则默认使用最后一条条目日期的后一天。
关闭期间不会清零收入与支出账户的余额,即不会将它们的余额转入权益账户。这是因为关闭操作也用于生成损益表的最终余额。而“清零”操作(如下一节所述)仅在生成资产负债表时才需要。
清零收入与支出
为了生成资产负债表,我们需要将收入与支出账户的最终余额转移至一个名为“本期收益”的权益账户(有时也称为“留存收益”或“净利润”;您可以通过输入文件中的选项指定具体使用的账户名称)。执行后,损益表账户的余额应为零(具体实现请参见 beancount.ops.summarize.clear())。
您可以这样执行清零操作:
SELECT … FROM <expression> CLEAR …
例如:
SELECT * FROM has_account("Invest") CLOSE ON 2015-04-01 CLEAR;
这是一个适用于生成资产负债表账户列表的语句。默认情况下,“Equity:Earnings:Current”账户将包含上一期间累计的净利润,输出中不应出现任何收入或支出账户的余额。
示例语句
当然,这些语句运算符可以组合使用。例如,若要输出 2013 年度的损益表数据,可以执行以下语句:
SELECT account, sum(position)
FROM OPEN ON 2013-01-01 CLOSE ON 2014-01-01
WHERE account ~ "Income|Expenses"
GROUP BY 1
ORDER BY 1;
这将生成收入与支出账户的余额列表。
要生成资产负债表,您需添加 CLEAR 选项并选择其他账户:
SELECT account, sum(position)
FROM OPEN ON 2013-01-01 CLOSE ON 2014-01-01 CLEAR
WHERE not account ~ "Income|Expenses"
GROUP BY 1
ORDER BY 1;
请注意,如果您在损益表账户中添加了 CLEAR 操作符,由于在期末将这些余额转移至权益净收益账户的交易,所有余额都将显示为零。
需要注意的是,上述示例并未对交易进行进一步筛选。如果您仅选择了一部分交易,可能希望保持账户为未开立、未结清和未清除状态,因为仅在资产和负债账户的期初余额基础上应用部分交易,无法正确计算这些账户的余额。更合适的做法是保持所有账户均为开立状态,并将资产负债表账户的余额解释为所选交易子集中这些账户的变动。例如,如果您选择了某次出行的所有交易(使用标签),您将获得一份标记为该次出行所包含的费用(以及可能的收入)变动列表,而资产和负债账户则会显示这些费用的资金来源。
有关此内容的图示,请参阅《复式记账法简介》文档。(诚然,这或许值得单独撰写一篇文档,我将来可能会为此编写一份。)
示例:获取成本基础
“……目前是否有简便的方法可以确定某账户在特定日期的成本基础(除了手动累加每笔出资的‘单位数 * 成本’,这相当繁琐)?我正试图估算潜在股票出售的税务影响。”[来自 Matthew Harris 的提问]
如需详细的股份变动报告:
SELECT account, currency, position, COST(position)
WHERE year <= 2015
AND account ~ "Assets:US:Schwab"
AND currency != "USD"
或获取成本基础的总和:
SELECT sum(cost(position))
WHERE year <= 2015
AND account ~ "Assets:US:Schwab"
AND currency != "USD"
高级快捷方式
会计应用中最常见的两类查询是日记账和余额报表。虽然我们已通过 bean-report 工具提供了这些报表的显式实现,但也可以使用 SELECT 语句合成近似的报表。本节将介绍一些可直接转换为 SELECT 语句的附加选择命令,这些命令将使用相同的查询代码执行,旨在作为便捷快捷方式。
选择日记账
一种常见的查询类型是生成交易条目的线性日记账(Ledger 称之为“登记簿”)。这大致相当于账户对账单,但在我们的语言中,此类对账单可针对任何交易子集生成。
您可以使用以下语法生成日记账:
JOURNAL <account-regexp> [AT <function>] [FROM …]
正则表达式 account-regexp 用于选择要生成日记账的账户子集。可选的 “AT <function>” 子句用于指定所显示金额的聚合函数(通常为 UNITS 或 COST)。FROM 子句遵循与 SELECT 语句相同的规则,且为可选项。
以下是生成日记账的示例查询:
JOURNAL "Invest" AT COST FROM HAS_ACCOUNT("Assets:US");
选择余额
另一种最常见的报表类型是特定日期下各账户余额的表格。这可视为按账户分组聚合头寸的 SELECT 查询。
您可以使用以下语法生成余额报表:
BALANCES [AT <function>] [FROM …]
可选的“AT <function>”子句用于指定所呈现余额的聚合函数(通常为UNITS或COST)。FROM子句遵循与SELECT语句相同的规则,且为可选。
要生成特定日期的余额,请使用上述描述的“FROM… CLOSE ON”形式关闭您的交易集。
请注意,会计环境中常见的资产负债表和利润表,实际上是此类查询所报告的余额表的子集。利润表仅报告某一时间段内发生的交易,而资产负债表则汇总报告期前的所有交易,并将期间内累计的收入与费用结转至权益账户,随后进行少量格式调整。有关更多详情,请参阅复式记账法的入门文档,以及上文讨论“open”、“close”和“clear”操作的部分。
我们还将提供一个独立的文本处理工具,可接收余额报告并将其重新格式化为类似资产负债表和利润表的两列格式。
打印
以 Beancount 格式生成输出可能很有用,例如将交易的子集保存到文件中。Shell 通过PRINT命令提供此功能:
PRINT [FROM …]
FROM 子句遵循本文档其他部分所述的常规语义。过滤后的 Beancount 交易流将按 Beancount 语法输出。
特别是,仅运行“PRINT”命令将输出已解析并加载的 Beancount 文件内容。如有需要,您可以使用此功能进行故障排查,或展开由您正在开发的插件生成的交易。
调试/解释
如果您在使某个语句编译和运行时遇到困难,可以在任何查询语句前添加EXPLAIN修饰符,例如:
EXPLAIN SELECT …
这不会执行语句,而是打印出中间的 AST 和编译后的表示形式,以及计算语句的列表。这在向邮件列表报告错误时可能很有用。
此外,这还会显示JOURNAL和BALANCES语句的翻译形式。
未来功能
以下功能原计划在首个版本中提供,但我决定先发布一个不含这些功能的初步版本,后续将在修订中添加。
展开库存
如果在查询后提供FLATTEN选项,查询引擎会将包含多个批次的库存展开为每个批次一行。例如,若您有一个包含以下内容的库存余额:
3 AAPL {102.34 USD}
4 AAPL {104.53 USD}
5 AAPL {106.23 USD}
使用以下查询:
SELECT account, sum(position) GROUP BY account;
它应返回一行结果,跨三行显示。但若添加选项:
SELECT account, sum(position) GROUP BY account FLATTEN;
它将返回三行独立的结果,包含所有选定属性,仿佛存在三笔分录。
子查询
目前不支持从另一个SELECT的结果中进行选择,但查询引擎的内部结构已为该功能做好准备。
更多信息
本文档旨在对查询语言支持的功能提供一个良好的高级概览。然而,如果您需要更多详细信息,可以查阅原始提案,或参考beanquery代码库中的源代码。特别是,解析器测试将帮助您了解语法的细节,而查询环境测试则能揭示支持的数据列和函数。欢迎您查阅源代码,并在邮件列表中提出问题。
附录
未来功能
本节记录了未来版本中计划实现的功能构想。
按列透视
将来将支持一种特殊的PIVOT BY子句,用于将查询结果从一维列表转换为二维表格。例如,以下查询:
SELECT
account,
YEAR(date) AS year,
SUM(COST(position)) AS balance
WHERE
account ~ 'Expenses:Food' AND
currency = 'USD' AND
year >= 2012
GROUP BY 1,2
ORDER BY 1,2;
可能会生成如下结果表格:
account year balance
------------------------ ---- -----------
Expenses:Food:Alcohol 2012 57.91 USD
Expenses:Food:Alcohol 2013 33.45 USD
Expenses:Food:Coffee 2012 42.07 USD
Expenses:Food:Coffee 2013 124.69 USD
Expenses:Food:Coffee 2014 38.74 USD
Expenses:Food:Groceries 2012 2172.97 USD
Expenses:Food:Groceries 2013 2161.90 USD
Expenses:Food:Groceries 2014 2072.36 USD
Expenses:Food:Restaurant 2012 4310.60 USD
Expenses:Food:Restaurant 2013 5053.61 USD
Expenses:Food:Restaurant 2014 4209.06 USD
如果您在查询中添加一个 PIVOT 子句,如下所示:
…
PIVOT BY account, year;
您将获得如下表格:
account/year 2012 2013 2014
------------------------ ----------- ----------- -----------
Expenses:Food:Alcohol 57.91 USD 33.45 USD
Expenses:Food:Coffee 42.07 USD 124.69 USD 38.74 USD
Expenses:Food:Groceries 2172.97 USD 2161.90 USD 2072.36 USD
Expenses:Food:Restaurant 4310.60 USD 5053.61 USD 4209.06 USD
如果您的表格包含超过三列,非透视列将水平扩展,如下所示:
SELECT
account,
YEAR(date),
SUM(COST(position)) AS balance,
LAST(date) AS updated
WHERE
account ~ 'Expenses:Food' AND
currency = 'USD' AND
year >= 2012
GROUP BY 1,2
ORDER BY 1, 2;
您将获得如下表格:
account year balance updated
------------------------ ---- ----------- ----------
Expenses:Food:Alcohol 2012 57.91 USD 2012-07-17
Expenses:Food:Alcohol 2013 33.45 USD 2013-12-13
Expenses:Food:Coffee 2012 42.07 USD 2012-07-19
Expenses:Food:Coffee 2013 124.69 USD 2013-12-16
Expenses:Food:Coffee 2014 38.74 USD 2014-09-21
Expenses:Food:Groceries 2012 2172.97 USD 2012-12-30
Expenses:Food:Groceries 2013 2161.90 USD 2013-12-31
Expenses:Food:Groceries 2014 2072.36 USD 2014-11-20
Expenses:Food:Restaurant 2012 4310.60 USD 2012-12-30
Expenses:Food:Restaurant 2013 5053.61 USD 2013-12-29
Expenses:Food:Restaurant 2014 4209.06 USD 2014-11-28
进行透视后,将生成如下表格:
account/balance,updated 2012/balanc 2012/updat 2013/balanc 2013/updat 2014/balanc 2014/updat
------------------------ ----------- ---------- ----------- ---------- ----------- ----------
Expenses:Food:Alcohol 57.91 USD 2012-07-17 33.45 USD 2013-12-13
Expenses:Food:Coffee 42.07 USD 2012-07-19 124.69 USD 2013-12-16 38.74 USD 2014-09-21
Expenses:Food:Groceries 2172.97 USD 2012-12-30 2161.90 USD 2013-12-31 2072.36 USD 2014-11-20
Expenses:Food:Restaurant 4310.60 USD 2012-12-30 5053.61 USD 2013-12-29 4209.06 USD 2014-11-28