组件和过滤器¶
数据框¶
为了以一致的方式将 DataFrames 写入 Excel,xlwings 报告会忽略 DataFrame 索引。如果你需要将索引传递到 Excel,可以在传递 DataFrame 之前重置索引。render_template: df.reset_index().
在处理 pandas DataFrames 时,报告设计者通常需要调整数据。借助过滤器,他们可以直接在模板中执行最常见的操作,而无需编写 Python 代码。通过使用竖线字符在 Excel 中为占位符添加过滤器:{{ myplaceholder | myfilter }}. 可以通过使用多个竖线字符组合多个过滤器:它们从左到右应用,即第一个过滤器的结果将成为下一个过滤器的输入。让我们先看一个例子,然后再列出每个过滤器及其详细信息:
import xlwings as xw
import pandas as pd
book = xw.Book('Book1.xlsx')
sheet = book.sheets['template'].copy(name='report')
df = pd.DataFrame({'one': [1, 2, 3], 'two': [4, 5, 6], 'three': [7, 8, 9]})
sheet.render_template(df=df)

数据帧过滤器¶
无头¶
隐藏列标题
示例:
{{ df | noheader }}
头部¶
仅返回标题
示例:
{{ df | header }}
升序排列¶
按升序排序(索引从零开始)
示例:按第二列然后按第一列排序:
{{ df | sortasc(1, 0) }}
降序排列¶
按降序排序(索引从零开始)
示例:按第一列然后按第二列降序排序:
{{ df | sortdesc(0, 1) }}
列¶
选择/重新排序列并插入空列(索引从零开始)
另见:colslice
示例:插入一个空列(None)作为第二列,并交换第二列和第三列的顺序:
{{ df | columns(0, None, 2, 1) }}
注意
合并单元格:如果在 Excel 模板中使用合并单元格,你也需要引入空列。
乘法、除法、加法、减法¶
对列应用算术运算(乘法、除法、求和、减法)(索引从零开始)
语法:
{{ df | operation(value, col_ix[, fill_value]) }}
fill_value是可选的,用于确定是否在操作中包含空单元格。要包含空值并使其行为类似于 Excel,请将其设置为0.
示例:将第一列乘以 100:
{{ df | mul(100, 0) }}
示例:将第一列乘以 100 并将第二列乘以 2:
{{ df | mul(100, 0) | mul(2, 1) }}
示例:向第一列包括空单元格加上 100:
{{ df | add(100, 0, 0) }}
最大行数¶
最大行数(目前仅支持sum作为聚合函数)
如果你的 DataFrame 有 12 行并且你使用maxrows(10, "Other")作为过滤器,你会得到一个显示前 9 行的表格,然后将剩余的 3 行在标签下求和Other。如果数据未排序,请确保调用sortasc/sortdesc首先确保正确地聚合行。
另见:aggsmall, head, tail, rowslice
语法:
{{ df | maxrows(number_rows, label[, label_col_ix]) }}
label_col_ix是可选的:如果不写入,它将标记 DataFrame 的第一列(索引从零开始)
示例:
{{ df | maxrows(10, "Other") }}
{{ df | sortasc(1)| maxrows(5, "Other") }}
{{ df | maxrows(10, "Other", 1) }}
聚合小值¶
聚合值低于某个阈值的行(目前仅支持sum作为聚合函数)
如果指定行中的值低于阈值,则它们将被汇总为一行。
另见:maxrows, head, tail, rowslice
语法:
{{ df | aggsmall(threshold, threshold_col_ix, label[, label_col_ix][, min_rows]) }}
label_col_ix和min_rows是可选的:如果不写入,它将标记 DataFrame 的第一列(索引从零开始)。label_col_ix的效果是如果否则行数低于min_rows has the effect that it skips rows from aggregating if it otherwise the number of rows falls below min_rows,则跳过行的聚合。这可以防止如果你只有几行都低于阈值,最后只剩下一行名为“Other”的情况。请注意,此参数仅在数据已排序的情况下才有意义!
示例:
{{ df | aggsmall(0.1, 2, "Other") }}
{{ df | sortasc(1) | aggsmall(0.1, 2, "Other") }}
{{ df | aggsmall(0.5, 1, "Other", 1) }}
{{ df | aggsmall(0.5, 1, "Other", 1, 10) }}
首部¶
仅显示前 n 行
另见:maxrows, aggsmall, tail, rowslice
示例:
{{ df | head(3) }}
尾部¶
仅显示最后 n 行
另见:maxrows, aggsmall, head, rowslice
示例:
{{ df | tail(5) }}
行切片¶
切片行
另见:maxrows, aggsmall, head, tail
语法:
{{ df | rowslice(start_index[, stop_index]) }}
stop_index是可选的:如果不写入,将在 DataFrame 的末尾停止
示例:显示第 2 到第 4 行(索引从零开始,区间半开,即起始包括且结束排除):
{{ df | rowslice(2, 5) }}
示例:显示第 2 行到 DataFrame 的末尾:
{{ df | rowslice(2) }}
列切片¶
切片列
另见:columns
语法:
{{ df | colslice(start_index[, stop_index]) }}
stop_index是可选的:如果不写入,将在 DataFrame 的末尾停止
示例:显示第 2 到第 4 列(索引从零开始,区间半开,即起始包括且结束排除):
{{ df | colslice(2, 5) }}
示例:显示第 2 列到 DataFrame 的末尾:
{{ df | colslice(2) }}
垂直合并¶
垂直合并具有相同值的相邻单元格 — 可用于表示层次结构
注意
The vmerge过滤器在 Excel 表格中不起作用,因为 Excel 表格不支持合并单元格!
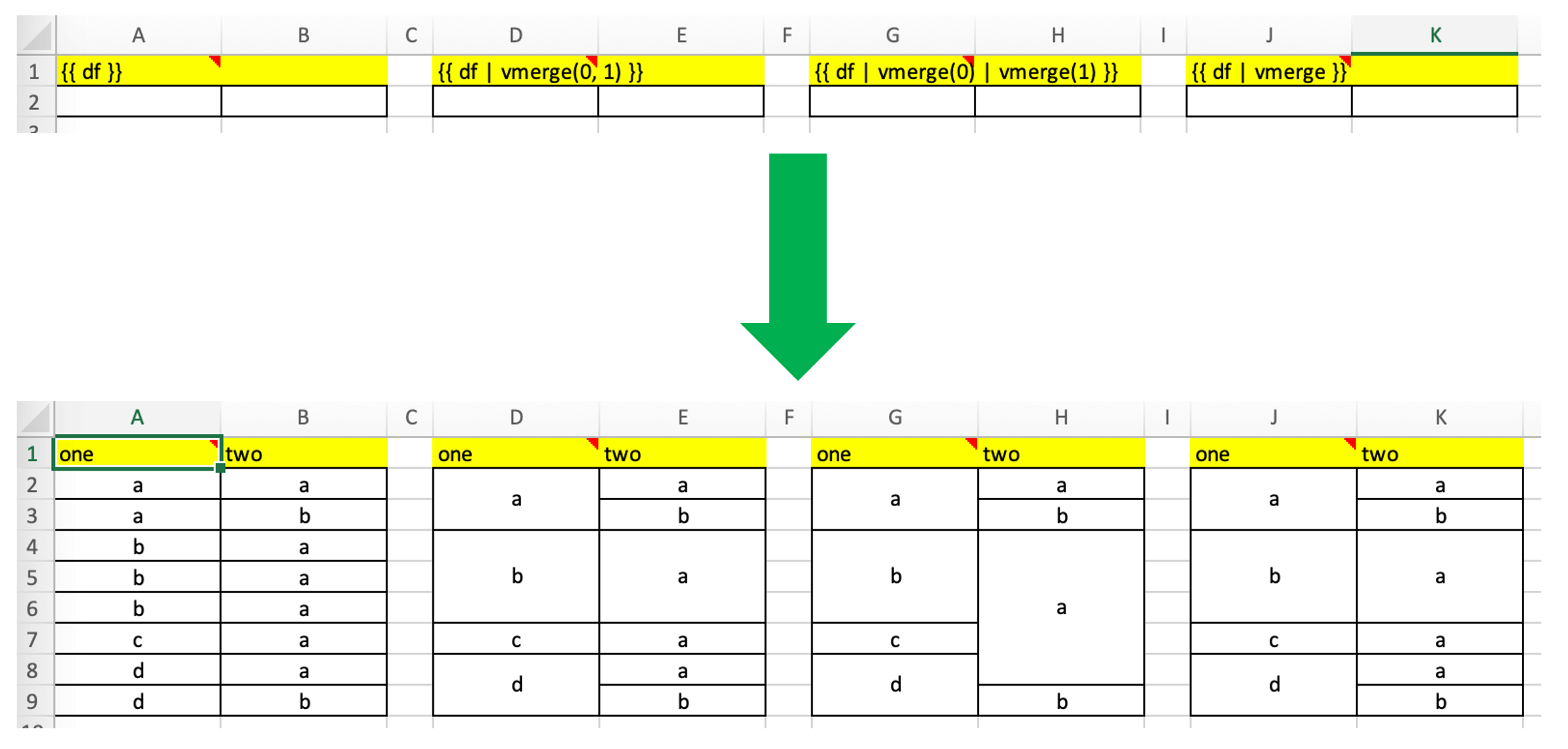
注意截图使用了 4框架并且文本在模板中居中/垂直对齐。
语法(参数是可选的):
{{ df | vmerge(col_index1, col_index2, ...) }}
示例(默认):跨所有列的分层模式 — 如果列数是动态的,这非常有用。在分层模式下,第一列(索引从零开始)中的单元格垂直合并,并且下一列中的单元格仅在上一列中合并的单元格内合并:
{{ df | vmerge }}
示例:仅跨指定列的分层模式:
{{ df | vmerge(0, 1) }}
示例:独立模式:如果你想在列中独立合并单元格,请多次使用过滤器。此示例在前两列(索引从零开始)中垂直合并单元格:
{{ df | vmerge(0) | vmerge(1) }}
格式化程序¶
注意
你不能在 Excel 表格中使用格式化器。
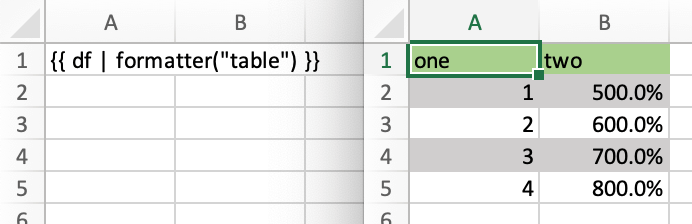
The formatter过滤器接受函数名称。该函数将在将值写入 Excel 后调用,并允许你灵活地对范围进行样式设置:
{{ df | formatter("myformatter") }}
格式化器的签名是:def myformatter(rng, df)其中rng对应于原始 DataFramedf写入的范围。添加类型提示(如下例所示)将帮助你的编辑器实现自动完成。
注意
在报告框架中,格式化程序需要装饰xlwings.reports.formatter(见下例)!不过,当你将它们作为标准 xlwings API 的一部分使用时,这不是必要的。
让我们再次运行快速入门示例,并附加一个格式化程序。
示例:
from pathlib import Path
import pandas as pd
import xlwings as xw
from xlwings.reports import formatter
# We'll place this file in the same directory as the Excel template
this_dir = Path(__file__).resolve().parent
@formatter
def table(rng: xw.Range, df: pd.DataFrame):
"""This is the formatter function"""
# Header
rng[0, :].color = "#A9D08E"
# Rows
for ix, row in enumerate(rng.rows[1:]):
if ix % 2 == 0:
row.color = "#D0CECE" # Even rows
# Columns
for ix, col in enumerate(df.columns):
if 'two' in col:
rng[1:, ix].number_format = '0.0%'
data = dict(
title='MyTitle',
df=pd.DataFrame(data={'one': [1, 2, 3, 4], 'two': [5, 6, 7, 8]})
)
# Change visible=False to run this in a hidden Excel instance
with xw.App(visible=True) as app:
book = app.render_template(this_dir / 'mytemplate.xlsx',
this_dir / 'myreport.xlsx',
**data)
Excel 表格¶
使用 Excel 表格是格式化表格的推荐方法,因为样式可以动态地应用于列和行。你还可以使用主题并对行/列应用交替颜色。转到Insert > Table并确保你已激活My table has headers在点击之前OK. 按照平常的方式在Excel表格的左上角添加占位符(注意此示例使用了框架):
运行以下脚本:
import pandas as pd
nrows, ncols = 3, 3
df = pd.DataFrame(data=nrows * [ncols * ['test']],
columns=[f'col {i}' for i in range(ncols)])
with xw.App(visible=True) as app:
book = app.render_template('template.xlsx', 'output.xlsx', df=df)
将生成以下报告:
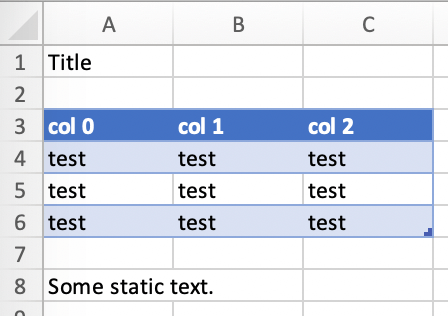
Excel表格的表头相对严格,例如,你不能有跨行的表头或合并单元格。要绕过这些限制,请取消选中Header Row位于Table Design下方的复选框,并使用noheader过滤器(参见DataFrame过滤器)。这将允许你在Excel表格外部设计自己的表头。
注意
目前,你只能将pandas DataFrame分配给表格
Excel 图表¶
若要在报告中使用Excel图表,请遵循以下过程:
在Excel模板中添加一些样本/虚拟数据:
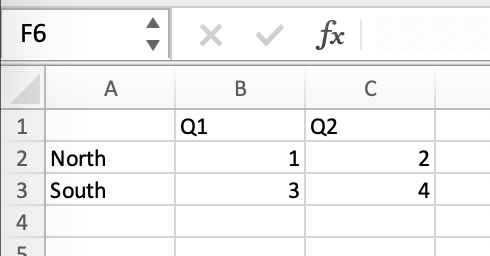
如果你的数据源是动态的,请将其转换为Excel表格 (
Insert>Table)。请务必在之前添加下一步中的图表。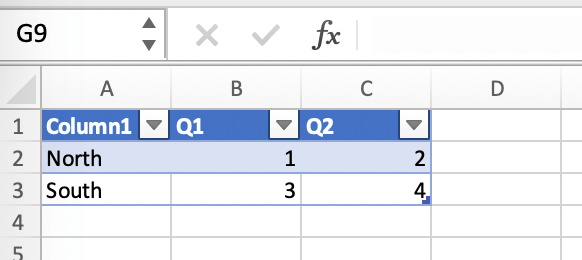
添加你的图表并进行样式设计:
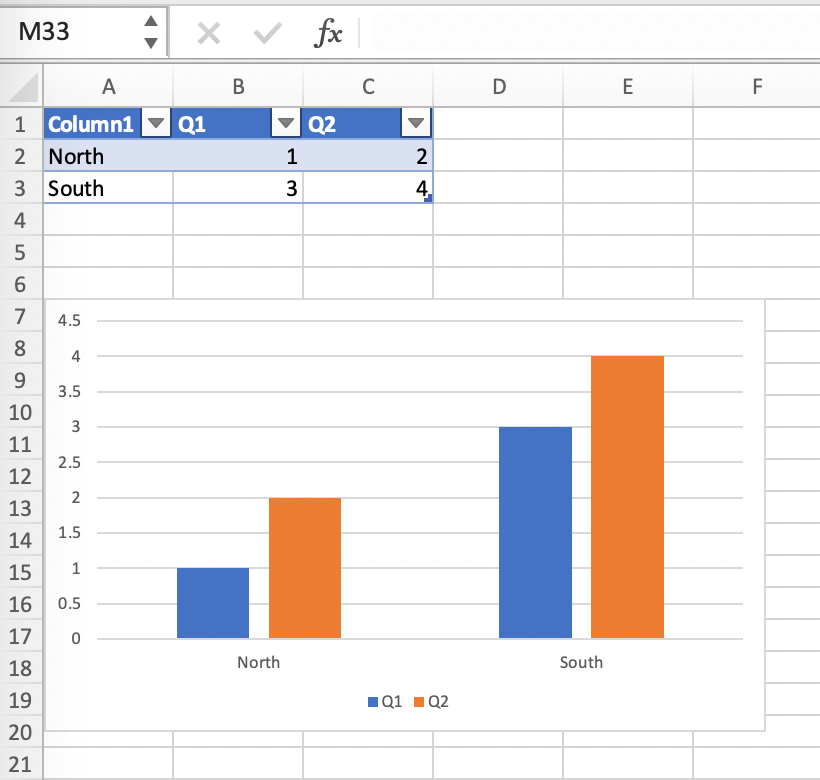
将Excel表格缩小到2x2范围,并在左上角添加占位符(在我们的示例中
{{ chart_data }})。你可以保留一些虚拟数据或清除Excel表格的值: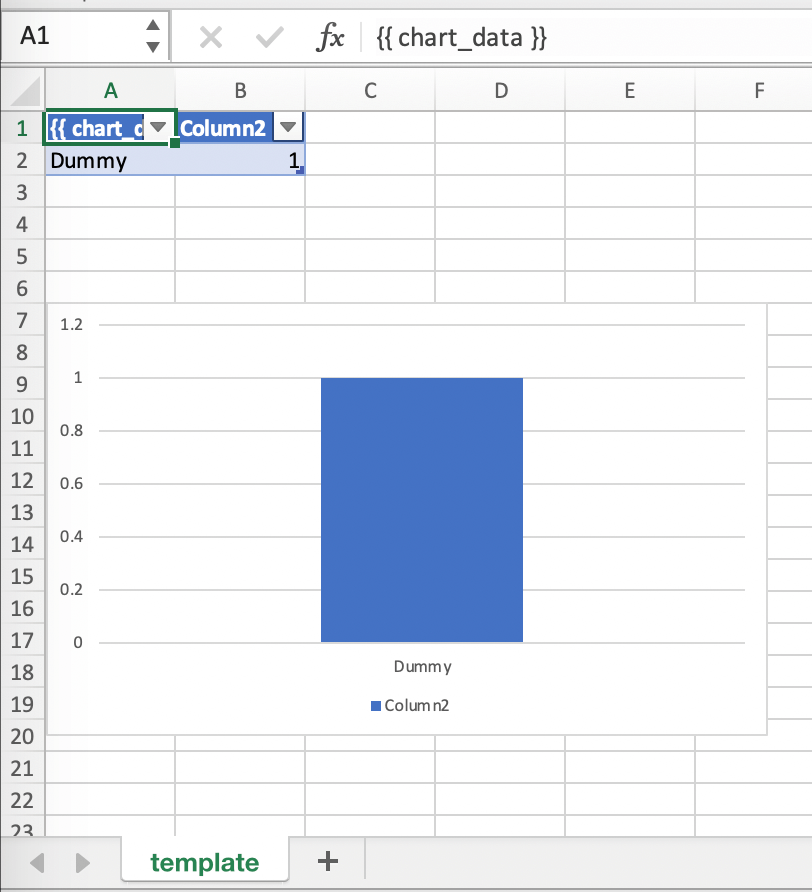
假设你的文件名为
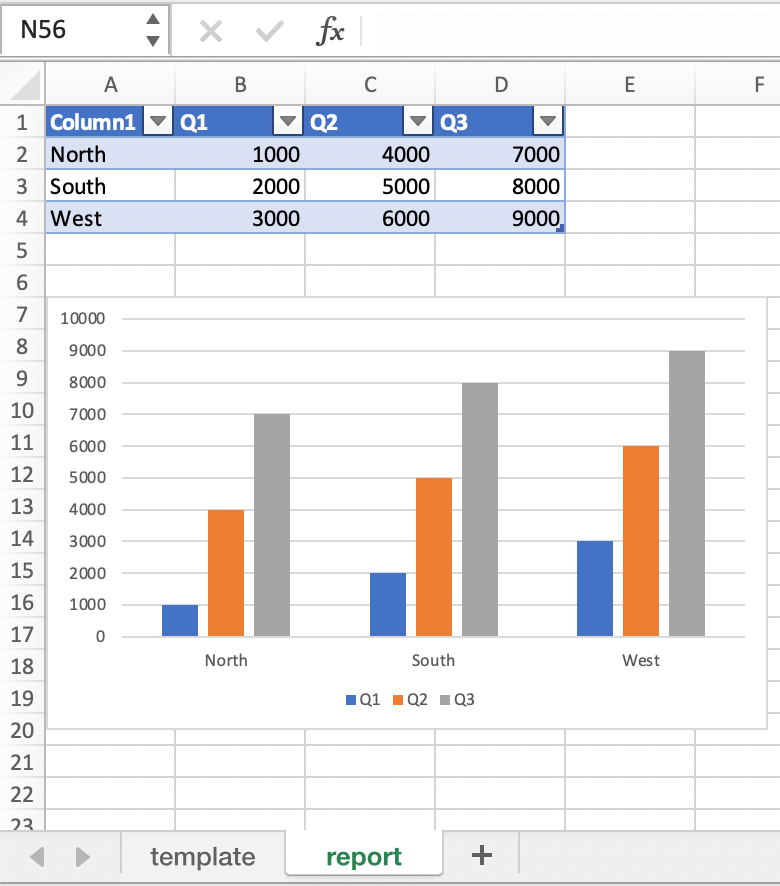
mytemplate.xlsx且工作表名为template如之前的截图所示,你可以运行以下代码:import xlwings as xw import pandas as pd df = pd.DataFrame(data={'Q1': [1000, 2000, 3000], 'Q2': [4000, 5000, 6000], 'Q3': [7000, 8000, 9000]}, index=['North', 'South', 'West']) book = xw.Book("mytemplate.xlsx") sheet = book.sheets['template'].copy(name='report') sheet.render_template(chart_data=df.reset_index())
这将生成以下报告,其中图表源已正确调整:
注意
如果你不想在报告中显示源数据,可以将其放置在单独的工作表上。最简单的方法是在单独的工作表上添加和设计图表,然后剪切图表并粘贴到你的报告模板上。为了防止调用时打印数据工作表to_pdf,你可以给它一个以#开头的名字,并且它将被忽略。请注意,如果你的工作表名以##开头,它将不会被打印也不会被渲染!
图像¶
图像插入后,带有占位符的单元格将成为图像的左上角。例如,在所需的单元格中写入以下占位符:{{ logo }},然后运行以下代码:
import xlwings as xw
from xlwings.reports import Image
book = xw.Book('Book1.xlsx')
sheet = book.sheets['template'].copy(name='report')
sheet.render_template(logo=Image(r'C:\path\to\logo.png'))
注意
Image也接受一个pathlib.Path对象而不是字符串。
如果你想使用基于矢量的图形,可以在macOS上使用svg在Windows上和pdf。你可以通过在占位符上应用过滤器来控制图像的外观。
可用于图像的过滤器:
宽度: 设置像素宽度(高度将按比例缩放)。
示例:
{{ logo | width(200) }}
高度: 设置像素高度(宽度将按比例缩放)。
示例:
{{ logo | height(200) }}
宽度和高度: 同时设置宽度和高度将扭曲图像的比例!
示例:
{{ logo | height(200) | width(200) }}
缩放: 使用因子缩放图像(高度和宽度将按比例缩放)。
示例:
{{ logo | scale(1.2) }}
顶部: 顶边距。相对于单元格的上边界,会将图像向下移动(正像素数)或向上移动(负像素数),以便微调图形对象的位置。
另见:
left示例:
{{ logo | top(5) }}
左侧: 左边距。相对于单元格的左边界,会使图像向右移动(正像素数)或向左移动(负像素数),以便微调图形对象的位置。
另见:
top示例:
{{ logo | left(5) }}
Matplotlib 和 Plotly 图表¶
关于如何处理Matplotlib和Plotly的通用介绍,请参阅:Matplotlib 和 Plotly 图表。在那里,你还会找到导出Plotly图表作为图片的前提条件。
Matplotlib¶
在想要粘贴Matplotlib图表的单元格中写入以下占位符:{{ lineplot }}。然后运行以下代码以获取你的Matplotlib Figure对象:
import matplotlib.pyplot as plt
import xlwings as xw
fig = plt.figure()
plt.plot([1, 2, 3])
book = xw.Book('Book1.xlsx')
sheet = book.sheets['template'].copy(name='report')
sheet.render_template(lineplot=fig)
Plotly¶
Plotly实际上工作方式相同:
import plotly.express as px
import xlwings as xw
fig = px.line(x=["a","b","c"], y=[1,3,2], title="A line plot")
book = xw.Book('Book1.xlsx')
sheet = book.sheets['template'].copy(name='report')
sheet.render_template(lineplot=fig)
若要更改Matplotlib或Plotly图表的外观,可以使用与图像相同的过滤器。此外,还可以使用以下过滤器:
格式: 允许将默认图像格式从
png更改为例如,vector,这将导出图表为矢量图形 (svg在Windows上和pdf在macOS上)。例如,为了让图表变小并使用矢量格式,你会写以下占位符:{{ lineplot | scale(0.8) | format("vector") }}
文本¶
你可以在单元格或文本框等形状中的文本中使用占位符。如果你不只是有几个字,通常文本框更具意义,因为它们不会影响行高,无论你怎么设置它们。在各个工作表中使用相同的网格格式化是获得一致多页报告的关键。
简单无格式文本¶
新增于版本0.21.4。
你可以使用任何形状,如矩形或圆形,而不仅仅是文本框:
with xw.App(visible=True) as app:
app.render_template('template.xlsx', 'output.xlsx', temperature=12.3)
此代码将此模板:

转换为该报告:

虽然这对于简单文本可行,但如果你有任何格式化信息将会丢失。为了避免这种情况,请使用一个Markdown对象,如下一部分所述。
如果你将在PDF 布局上打印,且具有深色背景,则可能需要将字体颜色更改为白色。这样做的负面影响是你将不再屏幕上看到内容。为了解决这个问题,请使用fontcolor过滤器:
字体颜色: 改变整个(!)单元格或形状的颜色。此过滤器的主要目的是使白色字体在Excel中可见。对于大多数其他颜色,你只需在Excel本身中更改颜色即可。请注意,此过滤器更改整个单元格或形状的字体,仅当存在单个占位符时才生效——如果你需要操作单个单词,请改用Markdown,见下文。黑色和白色可以用单词表示,否则请使用所需颜色的十六进制表示法。
示例:
{{ mytitle | fontcolor("white") }} {{ mytitle | fontcolor("#efefef") }}
Markdown 格式化¶
新增于版本0.23.0。
你可以通过Markdown语法对单元格或形状中的文本进行格式化。请注意,你也可以在Markdown文本中使用占位符,这些占位符将取你通过提供变量的值。render_template方法:
import xlwings as xw
from xlwings.reports import Markdown
mytext = """\
# Title
Text **bold** and *italic*
* A first bullet
* A second bullet
# {{ second_title }}
This paragraph has a line break.
Another line.
"""
# The first sheet requires a shape as shown on the screenshot
sheet = xw.sheets.active
sheet.render_template(myplaceholder=Markdown(mytext),
second_title='Another Title')
这将使用占位符在单元格和形状中渲染此模板:
像这样(这使用默认格式):

关于 Markdown 的更多详情,尤其是如何更改样式,请参见Markdown 格式化.
日期和时间¶
如果一个占位符对应于 Pythondatetime对象,默认情况下,Excel 将把该单元格格式化为日期格式的单元格。这不是总是理想的,因为格式取决于用户的区域设置。为了防止这种情况,在Text格式化或使用文本框并使用datetime过滤器以所需格式格式化日期。该datetime过滤器接受 strftime 语法——作为一个很好的参考,例如可以参见strftime.org.
要控制月份和星期名称的语言,你需要在 Python 代码中设置locale。例如,对于德语,你会使用以下内容:
import locale
locale.setlocale(locale.LC_ALL, 'de_DE')
示例:默认格式化是December 1, 2020:
{{ mydate | datetime }}
示例:为了应用特定格式,请提供所需的格式作为过滤器参数。例如,要以12/31/20格式获得它:
{{ mydate | datetime("%m/%d/%y") }}
数字格式¶
The format过滤器允许你通过使用与 Python 的 f-字符串提供的相同机制来格式化数字。例如,要格式化占位符performance=0.13读取为13.0%,你会这样做:
{{ performance | format(".1%") }}
这对应于 Python 中的以下 f-string:f"{performance:0.1%}". 若要了解格式字符串语法的介绍,请查看Python 字符串格式化手册.
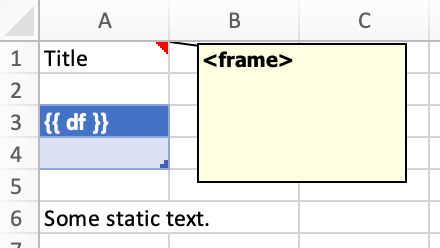
框架:多列布局¶
框架是垂直容器,其中的内容根据其高度对齐。也就是说,在框架内:
变量不会覆盖现有单元格值,而没有框架时它们会。
动态应用格式,具体取决于对象在 Excel 中使用的行数
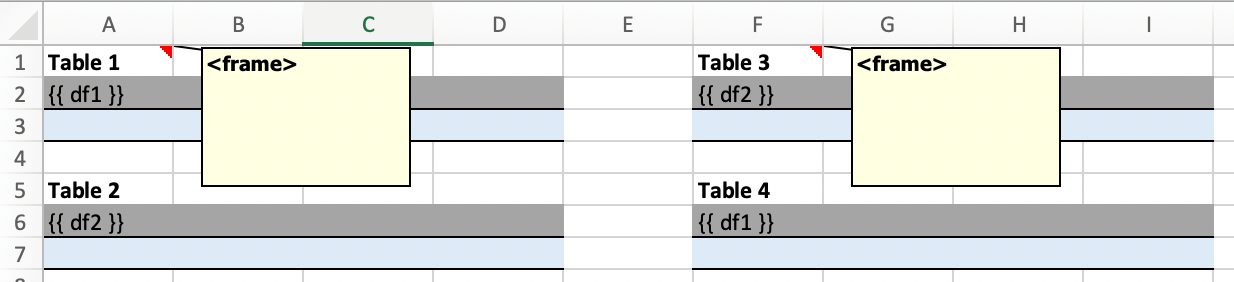
若要使用框架,请插入一个带有文本<frame>到第 1 行在你的 Excel 模板中的任何位置开始新的动态列。框架从一个<frame>到下一个<frame>或者已使用范围的右边界。
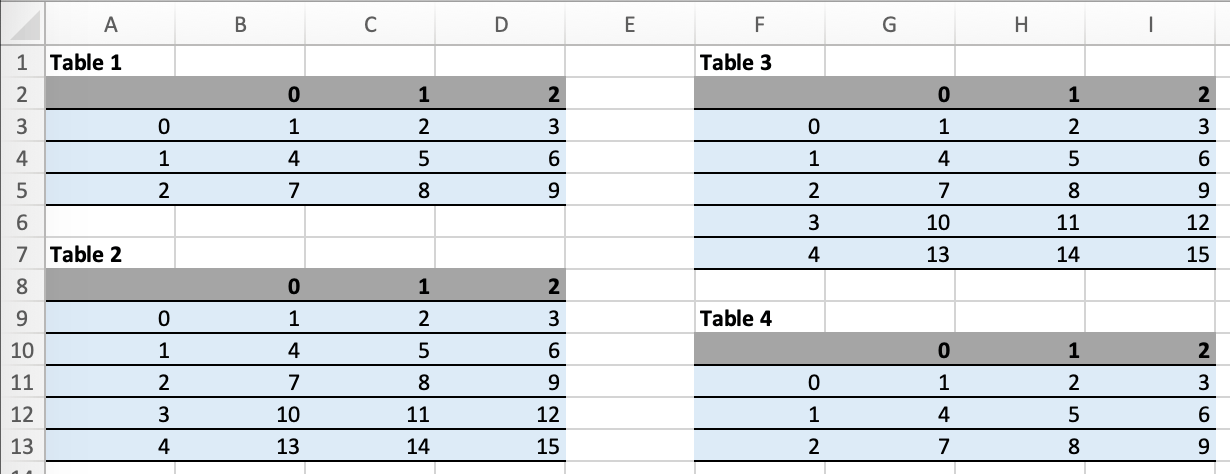
框架的行为最好通过示例演示:以下截图定义了两个框架。第一个从 A 列到 E 列,第二个从 F 列到 I 列,因为这是最后一个使用的列。
你可以通过格式化
一个标题和
一行数据来定义和格式化 DataFrames
如果你使用noheaderDataFrames 的过滤器,你可以省略标题并格式化单个数据行。或者,你也可以使用 Excel 表格,因为它们可以使格式化更简单。
运行以下代码:
import pandas as pd
df1 = pd.DataFrame([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
df2 = pd.DataFrame([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12], [13, 14, 15]])
data = dict(df1=df1.reset_index(), df2=df2.reset_index())
with xw.App(visible=True) as app:
book = app.render_template('my_template.xlsx',
'my_report.xlsx',
**data)
将生成此报告:
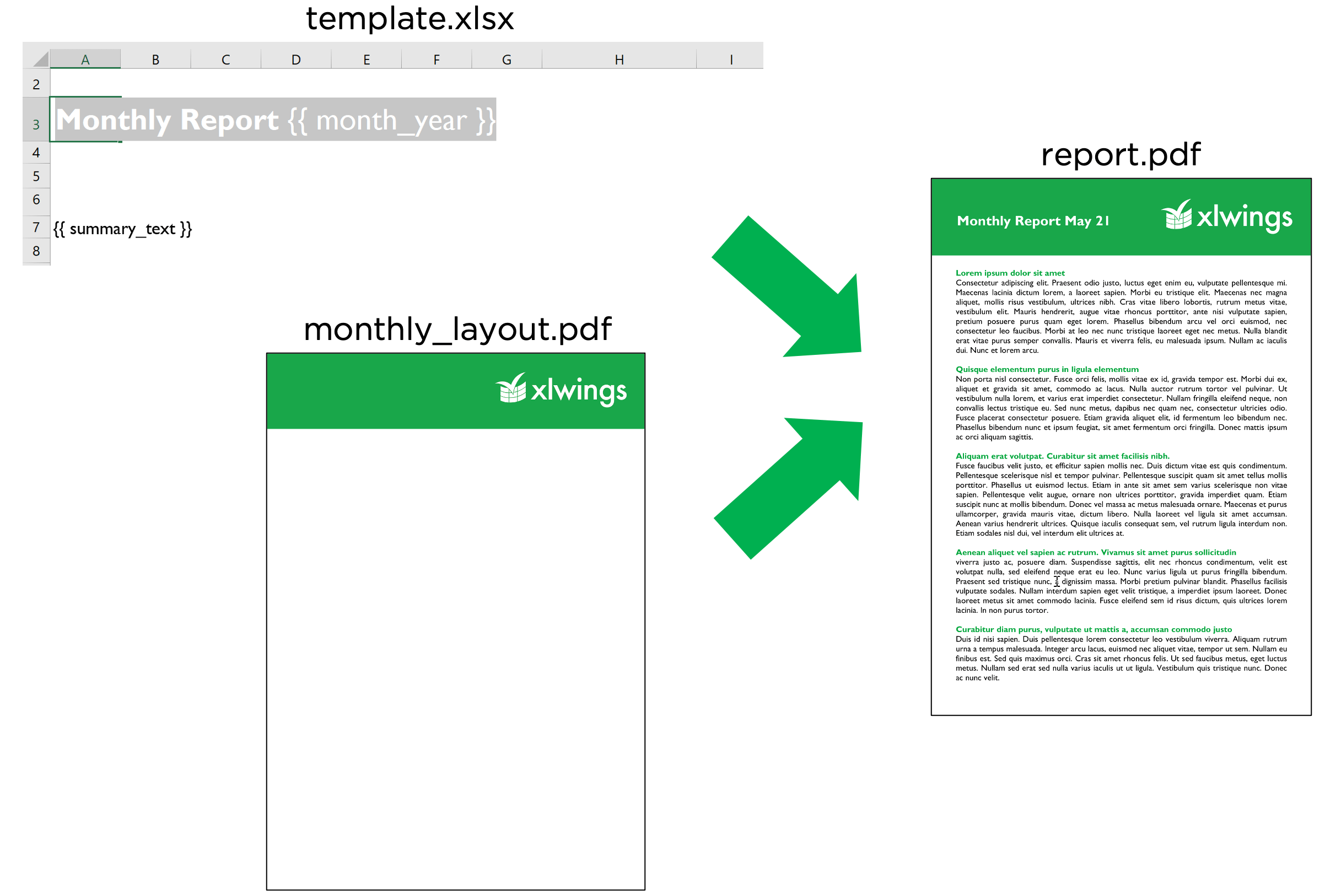
PDF 布局¶
使用layout参数在to_pdf()命令中,你可以“打印”你的 Excel 工作簿到专业设计的 PDF 上,生成完美的公司布局报告,包括页眉、页脚、背景和无边框图形:
import pandas as pd
df = pd.DataFrame([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
with xw.App(visible=True) as app:
book = app.render_template('template.xlsx',
'report.xlsx',
month_year = 'May 21',
summary_text = '...')
book.to_pdf('report.pdf', layout='monthly_layout.pdf')
注意,布局 PDF 要么需要由单页组成(将用于每一页的报告),要么需要和报告有相同的页数(每页报告将打印在相应的布局页面上)。
创建布局 PDF 时,你可以使用任何能够导出 PDF 文件的程序,如 PowerPoint 或 Word,但为了获得最佳效果,请考虑使用专业的桌面出版软件,如 Adobe InDesign。