转换器和选项¶
在 v0.7.0 中引入,转换器定义了 Excel 范围及其值在读取期间如何转换读取和写入 operations. They also provide a consistent experience across xlwings.Range对象和用户定义函数(UDF)。
转换器在明确设置时options方法中操纵Range对象或在@xw.arg和@xw.ret使用 UDF 的装饰器中。如果没有指定转换器,则在读取时应用默认转换器。在写入时,xlwings 会根据正在写入 Excel 的对象类型自动应用正确的转换器(如果可用)。如果未找到该类型的转换器,则会回退到默认转换器。
下面的所有代码示例都依赖于以下导入:
>>> import xlwings as xw
语法:
操作 |
范围对象 |
用户定义函数(UDFs) |
|---|---|---|
读取 |
|
|
写入 |
|
|
注意
关键字参数 (kwargs) 可以引用特定的转换器或默认转换器。例如,要在默认转换器中设置numbers选项和在 DataFrame 转换器中的index选项,你会这样写:
myrange.options(pd.DataFrame, index=False, numbers=int).value
默认转换器¶
如果没有设置选项,则执行以下转换:
单元格被读取为
floats如果 Excel 单元格包含数字,则读取为unicode如果它包含文本,则读取为datetime如果它包含日期则读取为None如果它是空的,则读取为列/行被读取为列表,例如
[None, 1.0, 'a string']二维单元格范围被读取为列表的列表,例如
[[None, 1.0, 'a string'], [None, 2.0, 'another string']]
可以设置以下选项:
ndim¶
强制值具有 1 或 2 维度,无论范围的形状如何:
>>> import xlwings as xw
>>> sheet = xw.Book().sheets[0]
>>> sheet['A1'].value = [[1, 2], [3, 4]]
>>> sheet['A1'].value
1.0
>>> sheet['A1'].options(ndim=1).value
[1.0]
>>> sheet['A1'].options(ndim=2).value
[[1.0]]
>>> sheet['A1:A2'].value
[1.0 3.0]
>>> sheet['A1:A2'].options(ndim=2).value
[[1.0], [3.0]]
数字¶
默认情况下带有数字的单元格被读取为float,但你可以将其更改为int:
>>> sheet['A1'].value = 1
>>> sheet['A1'].value
1.0
>>> sheet['A1'].options(numbers=int).value
1
或者,你可以指定任何接受单个浮点参数的其他函数或类型。
在 UDF 上使用此功能看起来像这样:
@xw.func
@xw.arg('x', numbers=int)
def myfunction(x):
# all numbers in x arrive as int
return x
注意
Excel 在交互模式下将所有数字作为浮点数传递,这就是为什么int转换器在将数字转换为整数之前先对它们进行四舍五入的原因。否则,例如,5 可能会被返回为 4,因为在表示上它可能是一个略小于 5 的浮点数。如果你需要 Python 原始的int在你的转换器中,请改用原始 int`。
日期¶
默认情况下带日期的单元格被读取为datetime.datetime,但你可以将其更改为datetime.date:
范围:
>>> import datetime as dt >>> sheet['A1'].options(dates=dt.date).value
UDFs(装饰器):
@xw.arg('x', dates=dt.date)
或者,你可以指定任何接受与datetime.datetime相同关键字参数的其他函数或类型,例如:
>>> my_date_handler = lambda year, month, day, **kwargs: "%04i-%02i-%02i" % (year, month, day)
>>> sheet['A1'].options(dates=my_date_handler).value
'2017-02-20'
空值¶
默认情况下空单元格被转换为None,你可以按照以下方式更改它:
范围:
>>> sheet['A1'].options(empty='NA').value
UDFs(装饰器):
@xw.arg('x', empty='NA')
转置¶
这适用于读取和写入,并允许我们例如以列方向将列表写入 Excel:
范围:
sheet['A1'].options(transpose=True).value = [1, 2, 3]UDFs:
@xw.arg('x', transpose=True) @xw.ret(transpose=True) def myfunction(x): # x will be returned unchanged as transposed both when reading and writing return x
扩展¶
此功能的工作方式与 Range 属性相同table, vertical和horizontal但在获取 Range 值时仅评估:
>>> import xlwings as xw
>>> sheet = xw.Book().sheets[0]
>>> sheet['A1'].value = [[1,2], [3,4]]
>>> range1 = sheet['A1'].expand()
>>> range2 = sheet['A1'].options(expand='table')
>>> range1.value
[[1.0, 2.0], [3.0, 4.0]]
>>> range2.value
[[1.0, 2.0], [3.0, 4.0]]
>>> sheet['A3'].value = [5, 6]
>>> range1.value
[[1.0, 2.0], [3.0, 4.0]]
>>> range2.value
[[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]]
注意
The expand方法仅在Range对象上可用,因为 UDF 仅允许操作调用单元格。
分块大小¶
当你从大范围读取数据或写入数据时,你可能需要分块处理,否则会遇到超时或内存错误。理想的chunksize将取决于你的系统和数组的大小,因此你需要尝试几种不同的分块大小以找到一个适合的:
import pandas as pd
import numpy as np
sheet = xw.Book().sheets[0]
data = np.arange(75_000 * 20).reshape(75_000, 20)
df = pd.DataFrame(data=data)
sheet['A1'].options(chunksize=10_000).value = df
并且读取也是一样的:
# As DataFrame
df = sheet['A1'].expand().options(pd.DataFrame, chunksize=10_000).value
# As list of list
df = sheet['A1'].expand().options(chunksize=10_000).value
错误转字符串¶
在版本 0.28.0 中添加。
如果True,将包括单元格错误如#N/A作为字符串。默认情况下,它们将被转换为None.
格式化程序¶
在版本 0.28.1 中添加。
注意
你不能在 Excel 表格中使用格式化器。
The formatter选项接受函数名称。该函数将在写入值到 Excel 后调用,并允许你以非常灵活的方式轻松地给范围设置样式。它的运作方式最好通过一个小例子来展示:
import pandas as pd
import xlwings as xw
sheet = xw.Book().sheets[0]
def table(rng: xw.Range, df: pd.DataFrame):
"""This is the formatter function"""
# Header
rng[0, :].color = "#A9D08E"
# Rows
for ix, row in enumerate(rng.rows[1:]):
if ix % 2 == 0:
row.color = "#D0CECE" # Even rows
# Columns
for ix, col in enumerate(df.columns):
if "two" in col:
rng[1:, ix].number_format = "0.0%"
df = pd.DataFrame(data={"one": [1, 2, 3, 4], "two": [5, 6, 7, 8]})
sheet["A1"].options(formatter=table, index=False).value = df
运行这段代码将会以这种方式格式化 DataFrame:
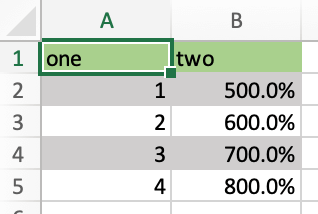
格式化器的签名是:def myformatter(myrange, myvalues)其中myrange对应于myvalues写入的范围。myvalues就是你在示例最后一行分配给value属性的内容。因为我们这里使用的是 DataFrame,所以按道理命名参数并使用类型提示将帮助你的编辑器实现自动完成。如果你使用嵌套列表而不是 DataFrame,你可以这样写:
def table(rng: xw.Range, values: list[list]):
内置转换器¶
xlwings 提供了几种内置转换器来进行类型转换为字典, NumPy 数组,
Pandas Series和数据框。这些是基于默认转换器构建的,因此在大多数情况下上述选项也可以在此上下文中使用(除非它们毫无意义,例如在字典的情况下ndim)。
还可以为其他类型编写和注册自定义转换器,详见下方。
下面的示例可以用于xlwings.Range对象和 UDF,即使只显示了一个版本。
字典转换器¶
字典转换器将两个 Excel 列转换为字典。如果数据是行方向的,使用transpose:
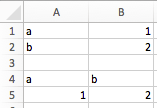
>>> sheet = xw.sheets.active
>>> sheet['A1:B2'].options(dict).value
{'a': 1.0, 'b': 2.0}
>>> sheet['A4:B5'].options(dict, transpose=True).value
{'a': 1.0, 'b': 2.0}
注意:而不是dict,你也可以使用OrderedDict来自collections.
Numpy数组转换器¶
选项: dtype=None, copy=True, order=None, ndim=None
前三个选项的行为与使用np.array()直接一致。此外,ndim的工作方式与上面针对列表(在默认转换器下)所示相同,因此返回的是 numpy 标量、一维数组或二维数组。
示例
>>> import numpy as np
>>> sheet = xw.Book().sheets[0]
>>> sheet['A1'].options(transpose=True).value = np.array([1, 2, 3])
>>> sheet['A1:A3'].options(np.array, ndim=2).value
array([[ 1.],
[ 2.],
[ 3.]])
Pandas Series转换器¶
选项: dtype=None, copy=False, index=1, header=True
前两个选项的行为与使用时相同pd.Series()直接。ndim对 Pandas 系列没有影响,因为它们总是以列方向期待和返回。
index: 整数或布尔值- 在读取时,它期望Excel中显示的索引列数。在写入时,通过将其设置为包含或排除索引
True或False. header: 布尔值- 在读取时,将其设置为
False如果Excel不显示索引或序列名称。在写入时,通过将其设置为包含或排除索引和序列名称True或False.
对于index和header, 1和True可以互换使用。
示例:
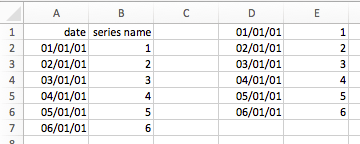
>>> sheet = xw.Book().sheets[0]
>>> s = sheet['A1'].options(pd.Series, expand='table').value
>>> s
date
2001-01-01 1
2001-01-02 2
2001-01-03 3
2001-01-04 4
2001-01-05 5
2001-01-06 6
Name: series name, dtype: float64
Pandas DataFrame转换器¶
选项: dtype=None, copy=False, index=1, header=1
前两个选项的行为与使用时相同pd.DataFrame()直接。ndim对Pandas DataFrames没有影响,因为它们会自动用以下方式读取ndim=2.
index: 整数或布尔值- 在读取时,它期望Excel中显示的索引列数。在写入时,通过将其设置为包含或排除索引
True或False. header: 整数或布尔值- 在读取时,它期望Excel中显示的列标题数。在写入时,通过将其设置为包含或排除索引和序列名称
True或False.
对于index和header, 1和True可以互换使用。
示例:
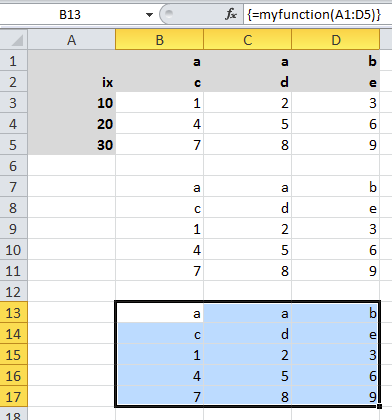
>>> sheet = xw.Book().sheets[0]
>>> df = sheet['A1:D5'].options(pd.DataFrame, header=2).value
>>> df
a b
c d e
ix
10 1 2 3
20 4 5 6
30 7 8 9
# Writing back using the defaults:
>>> sheet['A1'].value = df
# Writing back and changing some of the options, e.g. getting rid of the index:
>>> sheet['B7'].options(index=False).value = df
同样的样本用于UDF(从单元格开始A13截图上)看起来像这样:
@xw.func
@xw.arg('x', pd.DataFrame, header=2)
@xw.ret(index=False)
def myfunction(x):
# x is a DataFrame, do something with it
return x
Polars DataFrame和Series转换器¶
Polars DataFrames几乎与pandas DataFrames相同。但由于polars DataFrames没有索引且不支持MultiIndex标题,index选项不可用,并且header选项仅接受True(默认值)或False.
示例:
# This is a script example
import datetime as dt
import polars as pl
import xlwings as xw
df = pl.DataFrame(
{
"name": ["Alice Archer", "Ben Brown", "Chloe Cooper", "Daniel Donovan"],
"birthdate": [
dt.date(1997, 1, 10),
dt.date(1985, 2, 15),
dt.date(1983, 3, 22),
dt.date(1981, 4, 30),
],
"weight": [57.9, 72.5, 53.6, 83.1],
"height": [1.56, 1.77, 1.65, 1.75],
}
)
book = xw.Book()
sheet = book.sheets[0]
sheet["A1"].value = df # writing
df_read = sheet["A1"].expand().options(pl.DataFrame).value # reading
# This is a UDF example
import polars as pl
@xw.func
def myfunction(df: pl.DataFrame):
# df is a polars DataFrame, do something with it
return df
xw.Range和‘raw’转换器¶
严格来说,这些是“无转换器”。
如果你需要访问
xlwings.Range对象直接,你可以这样做:@xw.func @xw.arg('x', 'range') def myfunction(x): return x.formula
这返回x作为
xlwings.Range对象,即不应用任何转换器或选项。The
raw转换器从底层库(pywin32在Windows上和appscript在Mac上)传递值不变,即不对值进行清理/跨平台协调。这在少数情况下出于效率原因可能有用。例如:>>> sheet['A1:B2'].value [[1.0, 'text'], [datetime.datetime(2016, 2, 1, 0, 0), None]] >>> sheet['A1:B2'].options('raw').value # or sheet['A1:B2'].raw_value ((1.0, 'text'), (pywintypes.datetime(2016, 2, 1, 0, 0, tzinfo=TimeZoneInfo('GMT Standard Time', True)), None))
自定义转换器¶
实现自己的转换器的步骤如下:
继承自
xlwings.conversion.Converter实现两个
read_value和write_value方法作为静态方法或类方法:在
read_value,value是基础转换器返回的内容:因此,如果没有指定base它将以默认转换器的格式到达。在
write_value,value是写入Excel的原始对象。必须以基础转换器期望的格式返回。再次说明,如果没有指定base这是默认转换器。
The
options字典将包含在options方法中指定的所有关键字参数,例如调用时myrange.options(myoption='some value')或如在@arg和@ret装饰器中使用UDF时指定的那样。以下是基本结构:from xlwings.conversion import Converter class MyConverter(Converter): @staticmethod def read_value(value, options): myoption = options.get('myoption', default_value) return_value = value # Implement your conversion here return return_value @staticmethod def write_value(value, options): myoption = options.get('myoption', default_value) return_value = value # Implement your conversion here return return_value
可选:设置一个
base转换器(base期望一个类名)以基于现有转换器构建,例如对于内置的转换器:DictConverter,NumpyArrayConverter,PandasDataFrameConverter,PandasSeriesConverter可选:注册转换器:你可以(a)注册一个类型,使你的转换器在写操作期间成为该类型的默认转换器和/或(b)你可以注册一个别名,允许你按名称而不是仅按类名显式调用转换器。
以下示例应该使其更容易理解——它定义了一个DataFrame转换器,扩展了内置的DataFrame转换器以添加对删除nan的支持:
from xlwings.conversion import Converter, PandasDataFrameConverter
class DataFrameDropna(Converter):
base = PandasDataFrameConverter
@staticmethod
def read_value(builtin_df, options):
dropna = options.get('dropna', False) # set default to False
if dropna:
converted_df = builtin_df.dropna()
else:
converted_df = builtin_df
# This will arrive in Python when using the DataFrameDropna converter for reading
return converted_df
@staticmethod
def write_value(df, options):
dropna = options.get('dropna', False)
if dropna:
converted_df = df.dropna()
else:
converted_df = df
# This will be passed to the built-in PandasDataFrameConverter when writing
return converted_df
现在让我们看看不同的转换器如何应用:
# Fire up a Workbook and create a sample DataFrame
sheet = xw.Book().sheets[0]
df = pd.DataFrame([[1.,10.],[2.,np.nan], [3., 30.]])
DataFrames的默认转换器:
# Write sheet['A1'].value = df # Read sheet['A1:C4'].options(pd.DataFrame).value
DataFrameDropna转换器:
# Write sheet['A7'].options(DataFrameDropna, dropna=True).value = df # Read sheet['A1:C4'].options(DataFrameDropna, dropna=True).value
注册一个别名(可选):
DataFrameDropna.register('df_dropna') # Write sheet['A12'].options('df_dropna', dropna=True).value = df # Read sheet['A1:C4'].options('df_dropna', dropna=True).value
将DataFrameDropna注册为DataFrames的默认转换器(可选):
DataFrameDropna.register(pd.DataFrame) # Write sheet['A13'].options(dropna=True).value = df # Read sheet['A1:C4'].options(pd.DataFrame, dropna=True).value
这些样本在UDFs中都以相同的方式工作,例如:
@xw.func
@arg('x', DataFrameDropna, dropna=True)
@ret(DataFrameDropna, dropna=True)
def myfunction(x):
# ...
return x
注意
Python对象在写入Excel时会经过多阶段的转换管道。同样,在Excel/COM对象被读入Python时也是如此。
管道由内部定义Accessor类。转换器只是一个特殊的Accessor,通过在默认Accessor的管道中添加额外的阶段来转换为/从特定类型。例如,PandasDataFrameConverter定义了如何将列表的列表(由默认Accessor提供)转换为Pandas DataFrame。
The Converter类提供了基本的框架,使编写新的转换器任务变得更容易。如果你需要更多控制,可以直接子类化Accessor,但这部分需要更多工作且目前未记录。