
文档版本 v3.7-DRAFT 处于 草稿 状态。如需获取最新的稳定版文档,请参阅 v3.6。
监控 etcd
每个 etcd 服务器通过其客户端端口提供本地监控信息。这些监控数据对于系统健康检查和集群调试非常有用。
调试端点
如果设置了 --log-level=debug,etcd 服务器将在其客户端端口的 /debug 路径下导出调试信息。设置 --log-level=debug 时要小心,因为这会导致性能下降和日志记录变得冗长。
/debug/pprof 端点是标准的 Go 运行时分析端点。可以使用它来分析 CPU、堆、互斥锁和 goroutine 的使用情况。例如,这里 go tool pprof 获取了 etcd 花费时间最多的前 10 个函数:
$ go tool pprof http://localhost:2379/debug/pprof/profile
Fetching profile from http://localhost:2379/debug/pprof/profile
Please wait... (30s)
Saved profile in /home/etcd/pprof/pprof.etcd.localhost:2379.samples.cpu.001.pb.gz
Entering interactive mode (type "help" for commands)
(pprof) top10
310ms of 480ms total (64.58%)
Showing top 10 nodes out of 157 (cum >= 10ms)
flat flat% sum% cum cum%
130ms 27.08% 27.08% 130ms 27.08% runtime.futex
70ms 14.58% 41.67% 70ms 14.58% syscall.Syscall
20ms 4.17% 45.83% 20ms 4.17% github.com/coreos/etcd/vendor/golang.org/x/net/http2/hpack.huffmanDecode
20ms 4.17% 50.00% 30ms 6.25% runtime.pcvalue
20ms 4.17% 54.17% 50ms 10.42% runtime.schedule
10ms 2.08% 56.25% 10ms 2.08% github.com/coreos/etcd/vendor/github.com/coreos/etcd/etcdserver.(*EtcdServer).AuthInfoFromCtx
10ms 2.08% 58.33% 10ms 2.08% github.com/coreos/etcd/vendor/github.com/coreos/etcd/etcdserver.(*EtcdServer).Lead
10ms 2.08% 60.42% 10ms 2.08% github.com/coreos/etcd/vendor/github.com/coreos/etcd/pkg/wait.(*timeList).Trigger
10ms 2.08% 62.50% 10ms 2.08% github.com/coreos/etcd/vendor/github.com/prometheus/client_golang/prometheus.(*MetricVec).hashLabelValues
10ms 2.08% 64.58% 10ms 2.08% github.com/coreos/etcd/vendor/golang.org/x/net/http2.(*Framer).WriteHeaders
/debug/requests 端点通过 Web 浏览器提供 gRPC 跟踪和性能统计信息。例如,这里是一个针对键 abc 的 Range 请求:
When Elapsed (s)
2017/08/18 17:34:51.999317 0.000244 /etcdserverpb.KV/Range
17:34:51.999382 . 65 ... RPC: from 127.0.0.1:47204 deadline:4.999377747s
17:34:51.999395 . 13 ... recv: key:"abc"
17:34:51.999499 . 104 ... OK
17:34:51.999535 . 36 ... sent: header:<cluster_id:14841639068965178418 member_id:10276657743932975437 revision:15 raft_term:17 > kvs:<key:"abc" create_revision:6 mod_revision:14 version:9 value:"asda" > count:1
指标端点
每个 etcd 服务器在其客户端端口的 /metrics 路径下导出指标,并且可以选择在 --listen-metrics-urls 指定的位置导出。
可以使用 curl 获取这些指标:
$ curl -L http://localhost:2379/metrics | grep -v debugging # ignore unstable debugging metrics
# HELP etcd_disk_backend_commit_duration_seconds The latency distributions of commit called by backend.
# TYPE etcd_disk_backend_commit_duration_seconds histogram
etcd_disk_backend_commit_duration_seconds_bucket{le="0.002"} 72756
etcd_disk_backend_commit_duration_seconds_bucket{le="0.004"} 401587
etcd_disk_backend_commit_duration_seconds_bucket{le="0.008"} 405979
etcd_disk_backend_commit_duration_seconds_bucket{le="0.016"} 406464
...
健康检查
从 v3.3.0 开始,除了响应 /metrics 端点外,--listen-metrics-urls 指定的任何位置也将响应 /health 端点。如果标准端点配置了双向(客户端)TLS 认证,但负载均衡器或监控服务仍需要访问健康检查,这将非常有用。
从 v3.4 开始,新增了两个端点 /livez 和 /readyz。
/livez端点反映了进程是否存活或是否需要重启。/readyz端点反映了进程是否准备好处理流量。
端点的设计细节在 KEP 中有文档说明。
每个端点包括几个单独的健康检查,您可以使用 verbose 参数打印出检查及其状态的详细信息,例如
curl -k http://localhost:2379/readyz?verbose
您会看到类似以下的响应:
[+]data_corruption ok
[+]serializable_read ok
[+]linearizable_read ok
ok
HTTP API 还支持排除特定的检查,例如
curl -k http://localhost:2379/readyz?exclude=data_corruption
Prometheus
运行一个 Prometheus 监控服务是摄取和记录 etcd 指标的最简单方法。
首先,安装 Prometheus:
PROMETHEUS_VERSION="2.0.0"
wget https://github.com/prometheus/prometheus/releases/download/v$PROMETHEUS_VERSION/prometheus-$PROMETHEUS_VERSION.linux-amd64.tar.gz -O /tmp/prometheus-$PROMETHEUS_VERSION.linux-amd64.tar.gz
tar -xvzf /tmp/prometheus-$PROMETHEUS_VERSION.linux-amd64.tar.gz --directory /tmp/ --strip-components=1
/tmp/prometheus -version
将 Prometheus 的抓取器设置为目标 etcd 集群端点:
cat > /tmp/test-etcd.yaml <<EOF
global:
scrape_interval: 10s
scrape_configs:
- job_name: test-etcd
static_configs:
- targets: ['10.240.0.32:2379','10.240.0.33:2379','10.240.0.34:2379']
EOF
cat /tmp/test-etcd.yaml
设置 Prometheus 处理程序:
nohup /tmp/prometheus \
-config.file /tmp/test-etcd.yaml \
-web.listen-address ":9090" \
-storage.local.path "test-etcd.data" >> /tmp/test-etcd.log 2>&1 &
现在 Prometheus 将每 10 秒抓取一次 etcd 指标。
告警
有一组适用于 etcd v3 集群的 默认告警 用于 Prometheus。
注意
请注意,job 标签可能需要根据具体需求进行调整。这些规则是为单个集群编写的,因此建议选择对集群唯一的标签。Grafana
Grafana 内置了 Prometheus 支持;只需添加一个 Prometheus 数据源:
Name: test-etcd
Type: Prometheus
Url: http://localhost:9090
Access: proxy
然后导入默认的 etcd 仪表板模板 并进行自定义。例如,如果 Prometheus 数据源名称是 my-etcd,则 JSON 中的 datasource 字段值也需要是 my-etcd。
示例仪表板:
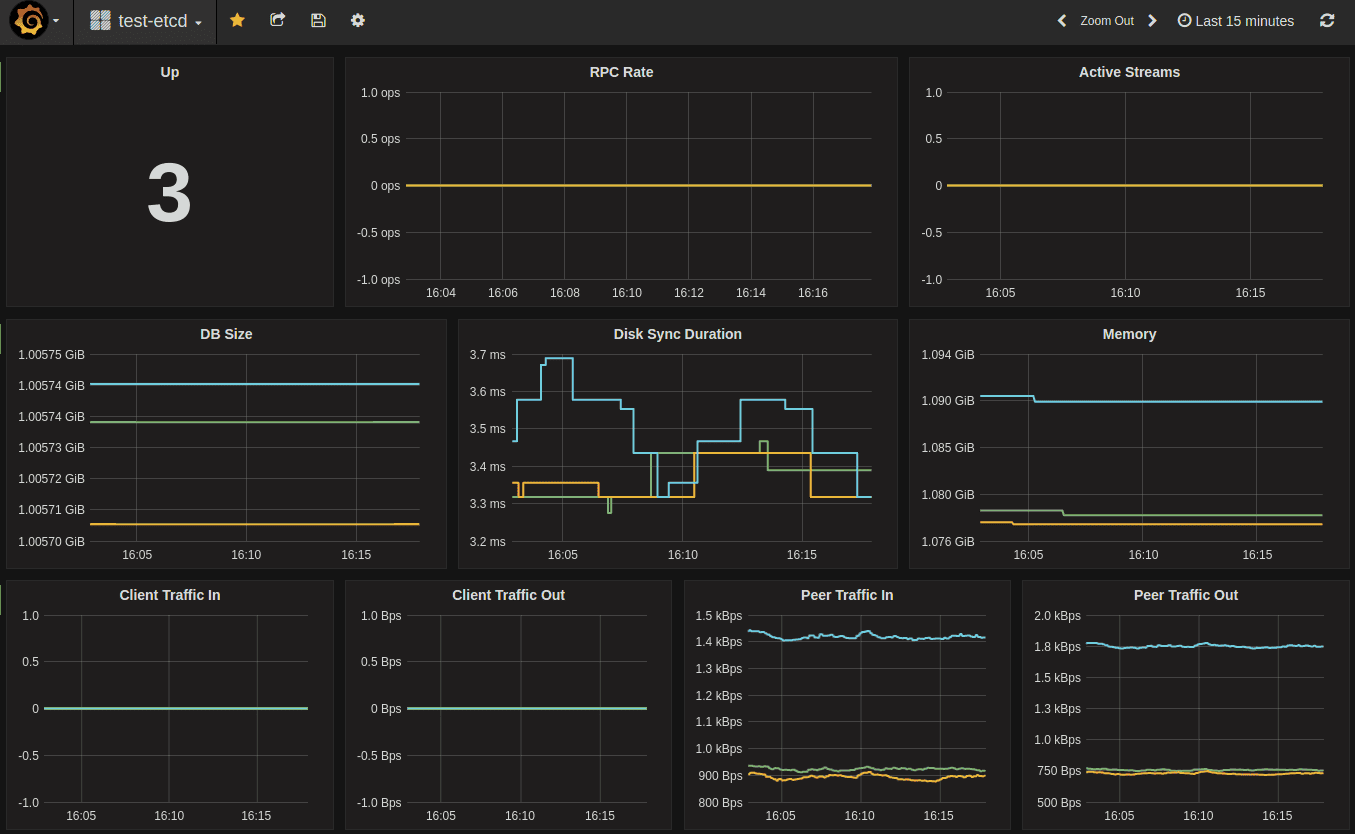
分布式追踪
在 v3.5 中,etcd 已添加了使用 OpenTelemetry 进行分布式跟踪的支持。
注意
此功能仍处于实验阶段,随时可能发生变化。要启用此实验性功能,请将 --experimental-enable-distributed-tracing=true 传递给 etcd 服务器,并使用 --experimental-distributed-tracing-sampling-rate=<number> 标志来选择每百万跨度收集的样本数,默认采样率为 0。
通过以下可选标志启动 etcd 服务器来配置分布式跟踪:
--experimental-distributed-tracing-address- (可选)- “localhost:4317” - 跟踪收集器的地址。--experimental-distributed-tracing-service-name- (可选)- “etcd” - 分布式跟踪服务名称,在所有 etcd 实例中必须相同。--experimental-distributed-tracing-instance-id- (可选)- 实例 ID,虽然可选但强烈建议设置,在每个 etcd 实例中必须唯一。
在启用分布式跟踪之前,请确保拥有 OpenTelemetry 端点。如果该地址与默认地址不同,请使用 --experimental-distributed-tracing-address 标志进行覆盖。由于 OpenTelemetry 有不同的运行方式,请参阅 收集器文档 以了解更多信息。