
1 扩展 Thymeleaf 的一些原因
Thymeleaf 是一个高度可扩展的库。其关键在于,它的大多数面向用户的功能并不是直接内置在核心中,而是被打包并组件化到被称为方言.
的功能集中。标准和SpringStandarddialects(方言)
场景 1:向标准方言添加功能
,并且它需要根据用户角色(管理员或非管理员),从周一到周六显示蓝色或红色背景的提示文本框,但在周日始终显示绿色背景。你可以在模板中使用条件表达式来实现这一点,但过多的条件会使代码略显难以阅读……SpringStandard标准方言
解决方案:创建一个名为alertclass的新属性MyOwnDialectdialect(方言)th前缀(与SpringStandard相同的th:alertclass="${user.role}"!
场景 2:视图层组件
假设你的公司在广泛使用 Thymeleaf,并且你想创建一个通用功能(标签和/或属性)的仓库,以便在多个应用之间复用而无需进行复制粘贴操作。换句话说,你想以类似于 JSP 的方式创建视图层组件taglibs(标签库).
解决方案:为每组相关功能创建一个 Thymeleaf 方言,并根据需要将这些方言添加到你的应用程序中。请注意,如果你的方言中的标签或属性使用了外部化(国际化)消息,则你可以将这些消息随方言一起打包(以处理器消息的形式).properties文件,不像 JSP 中那样要求所有应用都包含这些文件。
场景 3:创建你自己的模板系统
现在假设你正在创建一个允许用户为其内容创建自己设计模板的公共网站。当然,你不希望用户能在他们的模板中做任何事,甚至不应允许标准方言所支持的所有功能(例如执行 OGNL 表达式)。因此你需要让你的用户只能使用一组你控制下的特定功能(例如显示头像、博客文章正文等)。
解决方案:创建一个包含你希望用户能使用的标签或属性的 Thymeleaf 方言,比如<mysite:profilePhoto />或<mysite:blogentries fromDate="23/4/2011" />。然后允许你的用户使用这些功能创建他们自己的模板,并让 Thymeleaf 来执行它们,确保没有人能做超出允许范围的事情。
2 方言和处理器
2.1 方言
如果你在到达这里之前已经阅读过使用 Thymeleaf教程——你应该这么做——你应该知道Thymeleaf你一直以来学习的内容并不完全是标准方言,而是它的或者说是SpringStandard 方言(如果也阅读过Thymeleaf + Spring教程)。
这意味着什么?这意味着你学到的那些th:x属性仅仅是一个标准的、默认提供的功能集,但你可以定义你自己的一组属性(或标签),使用你喜欢的名称并在 Thymeleaf 中使用它们处理你的模板。你可以定义你自己的方言。
方言是实现了org.thymeleaf.dialect.IDialect接口的对象
public interface IDialect {
public String getName();
}方言的核心要求只有一个,就是有一个可用于标识它的名称。但这本身用途不大,因此通常方言会根据其所提供的内容实现IDialect的一个或多个子接口:
IProcessorDialect提供处理器(processors).IPreProcessorDialect提供预处理器(pre-processors).IPostProcessorDialect提供和后处理器(post-processors).IExpressionObjectDialect提供表达式对象.IExecutionAttributeDialect提供执行属性.
处理器方言:IProcessorDialect
这个IProcessorDialect接口如下所示:
public interface IProcessorDialect extends IDialect {
public String getPrefix();
public int getDialectProcessorPrecedence();
public Set<IProcessor> getProcessors(final String dialectPrefix);
}处理器是负责执行 Thymeleaf 模板中大多数逻辑的对象,可能是最重要的 Thymeleaf 扩展构件。我们将在下一节更详细地介绍处理器。
该方言仅定义了三个项:
这个前缀,这是应默认应用的前缀或命名空间默认到与方言处理器匹配的元素和属性上。因此,一个带有前缀的方言,
th例如标准方言将能够定义匹配类似th:text,th:if或th:whatever的属性(或者如果我们更喜欢使用data-th-text,data-th-if和data-th-whatever纯HTML5语法)。但请注意,这里由方言返回的前缀只是该方言的默认前缀,这个前缀可以在模板引擎配置期间被修改。另外请注意,如果希望我们的处理器能够在没有前缀的标签/属性上执行,可以将前缀设置为空。只是默认的前缀。如果希望我们的处理器能够在无前缀的标签/属性上执行,则可以将前缀设为空字符串。nullif we want our processors to execute on unprefixed tags/attributes.这个方言优先级允许跨方言对处理器进行排序。每个处理器定义自己的优先级值,但这些处理器优先级是相对于方言优先级来考虑的,因此只需正确设置此方言优先级.
这个处理器(processors)如其名称所示,是一个处理器(processors)提供的集合。请注意,
getProcessors(...)方法在调用时会传入dialectPrefix参数,以防该方言在模板引擎中配置了不同于默认前缀的前缀。大多数情况下,IProcessor实例在其初始化过程中需要这个信息。
预处理器方言:IPreProcessorDialect
预处理器和和后处理器(post-processors)与普通处理器不同,处理器(processors)它们不是针对单个事件或事件模型(模板的一部分)执行,而是作为引擎处理链中的额外步骤应用于整个模板执行过程。因此,它们遵循一种与处理器完全不同的、更加面向事件的API,这种接口由底层更低层级的ITemplateHandler接口定义。
在预处理器的具体情况下,它们在Thymeleaf 引擎开始为特定模板执行处理器之前应用。
这个IPreProcessorDialect接口的样子:
public interface IPreProcessorDialect extends IDialect {
public int getDialectPreProcessorPrecedence();
public Set<IPreProcessor> getPreProcessors();
}这与上面提到的处理器类似的接口——包括它自己在方言级别为预处理器定义的优先级——但缺少一个IProcessorDialect above –including its own dialect-level precedence for pre-processors– but lacks a 前缀,因为预处理器根本不需要前缀(它们不匹配特定的事件——相反,它们处理所有事件)。
后处理器方言:IPostProcessorDialect
如前所述,和后处理器(post-processors)它们是模板执行链中的另一个步骤,但这次它们是在Thymeleaf 引擎应用完所有需要的处理器之后执行。这意味着后处理器在模板输出发生之前应用(因此可以修改即将输出的内容)。 the Thymeleaf engine has applied all the needed processors. This means post-processors apply just before template output happens (and can therefore modify what is being output).
这个IPostProcessorDialect接口的样子:
public interface IPostProcessorDialect extends IDialect {
public int getDialectPostProcessorPrecedence();
public Set<IPostProcessor> getPostProcessors();
}……这与IPreProcessorDialect接口非常类似,当然这次是为后处理器设计的。
表达式对象方言:IExpressionObjectDialect
实现此接口的方言提供新的表达式对象或表达式工具对象表达式对象#strings, #numbers, #dates,比如标准方言中提供的
这个IExpressionObjectDialect接口如下所示:
public interface IExpressionObjectDialect extends IDialect {
public IExpressionObjectFactory getExpressionObjectFactory();
}正如我们所见,这个接口并不直接返回表达式对象本身,而是仅返回一个工厂。这样做的原因是某些表达式对象表达式对象可能需要处理上下文中的数据才能构建出来,因此在真正处理模板之前无法构建它们……此外,大多数表达式根本不需要表达式对象表达式对象按需创建,只在确实需要用于具体表达式时才创建所需的那部分。
这是IExpressionObjectFactory接口:
public interface IExpressionObjectFactory {
public Map<String,ExpressionObjectDefinition> getObjectDefinitions();
public Object buildObject(final IProcessingContext processingContext, final String expressionObjectName);
}执行属性方言:IExecutionAttributeDialect
实现此接口的方言允许提供执行属性,即,在模板处理期间每个正在执行的处理器都可以访问的对象。
例如,标准方言实现了该接口以便向每一个处理器提供:
- 这个Thymeleaf 标准表达式解析器使得任何属性中的标准表达式都可以被解析和执行。
- 这个变量表达式求值器因此,
${...}表达式可以在 OGNL 或 SpringEL 中执行(取决于是否使用了 Spring 集成模块)。 - 这个转换服务用于执行
${{...}}表达式。
转换操作。
这个IExecutionAttributeDialect注意这些对象不在上下文中可用,因此不能从模板表达式中使用它们。它们的可用性仅限于处理器、预处理器等扩展点的实现。
public interface IExecutionAttributeDialect extends IDialect {
public Map<String,Object> getExecutionAttributes();
}2.2 处理器
处理器是实现org.thymeleaf.processor.IProcessor接口的对象,它们包含要应用于模板不同部分的实际逻辑(我们将把这部分表示为事件,鉴于 Thymeleaf 是基于事件的引擎)。这个接口如下所示:
public interface IProcessor {
public TemplateMode getTemplateMode();
public int getPrecedence();
}和方言一样,这是一个非常简单的接口,它只指定了处理器适用的模板模式及其优先级。
但有几种类型的处理器处理器,每种对应一种可能的事件类型:
- 模板开始/结束
- 元素标签
- 文本
- 注释
- CDATA 节
- DOCTYPE 子句
- XML 声明
- 处理指令
还包括模型:代表一个完整元素的事件序列,即包含其完整内容的元素,包括其中可能出现的任何嵌套元素或其他类型的内容。如果建模的元素是一个独立元素,则模型中仅包含对应的单个事件;但如果建模的元素包含内容,模型中将包含从其open tag开始标签关闭标签结束标签之间的全部事件,两个标签都包含在内。
所有这些类型的处理器都是通过实现特定接口或继承现有的一些基类来创建的。抽象实现所有这些符合 Thymeleaf 处理器 API 的构件都位于org.thymeleaf.processor包中。
元素处理器
元素处理器是指那些在打开元素 (IOpenElementTag)或独立元素 (IStandaloneElementTag)事件上执行的处理器,通常通过将元素名称(和/或其属性之一)与处理器指定的匹配配置进行匹配来实现。这就是IElementProcessor接口的样子:
public interface IElementProcessor extends IProcessor {
public MatchingElementName getMatchingElementName();
public MatchingAttributeName getMatchingAttributeName();
}但需要注意的是,元素处理器的实现并不是直接实现这个接口。相反,元素处理器应该属于以下两类之一:
- 元素标签处理器,实现
IElementTagProcessor接口。这些处理器以打开/独立标签事件上执行(关闭标签上不能应用任何处理器),并且无法直接访问元素内容。 - 元素模型处理器,实现
IElementModelProcessor接口。这些处理器以complete elements, including their bodies, in the form ofIModel对象的形式,在完整的元素及其内容上执行。
我们应该分别查看这些接口中的每一个:
元素标签处理器:IElementTagProcessor
如前所述,元素标签处理器在单个打开元素或独立元素标签上执行,该标签与其匹配配置相匹配(参见IElementProcessor)。需要实现的接口是IElementTagProcessor包裹,看起来像这样:
public interface IElementTagProcessor extends IElementProcessor {
public void process(
final ITemplateContext context,
final IProcessableElementTag tag,
final IElementTagStructureHandler structureHandler);
}可以看到,除了继承IElementProcessor之外,它只定义了一个process(...)方法,当匹配配置匹配时(并且按照其优先级顺序执行,该顺序在IProcessor超类接口中设定)。它的process(...)签名非常简洁,并遵循了每个 Thymeleaf 处理器接口中常见的模式:
- 这个
process(...)方法返回void。所有操作都将通过structureHandler. - 这个
context参数执行。该参数包含模板执行的上下文:变量、模板数据等。 - 这个
tag参数是触发此处理器的事件。它同时包含元素名称及其属性。 - 这个
structureHandler是一个特殊对象,允许处理器向引擎发送指令,告知它应因处理器的执行而执行哪些操作。
使用。structureHandler
这个tag参数中的process(...)是一个不可变对象。因此,无法直接修改tag对象本身的标签属性。此时,应使用structureHandler。
例如,让我们看看如何读取特定tag属性的值,解码转义字符,将其保存在一个变量中,然后从标签中移除该属性:
// Obtain the attribute value
String attributeValue = tag.getAttributeValue(attributeName);
// Unescape the attribute value
attributeValue =
EscapedAttributeUtils.unescapeAttribute(context.getTemplateMode(), attributeValue);
// Instruct the structureHandler to remove the attribute from the tag
structureHandler.removeAttribute(attributeName);
... // do something with that attributeValue注意上面的代码只是为了展示一些属性管理的概念——在大多数处理器中,我们不需要手动执行此类“获取值+解码转义+删除”操作,这些操作通常由如AbstractAttributeTagProcessor.
这样的扩展超类来自动处理。操作提供的structureHandler。Thymeleaf 中每种类型的处理器都有一个结构处理器。,其中针对元素标签处理器的实现了IElementTagStructureHandler接口,如下所示:
public interface IElementTagStructureHandler {
public void reset();
public void setLocalVariable(final String name, final Object value);
public void removeLocalVariable(final String name);
public void setAttribute(final String attributeName, final String attributeValue);
public void setAttribute(final String attributeName, final String attributeValue,
final AttributeValueQuotes attributeValueQuotes);
public void replaceAttribute(final AttributeName oldAttributeName,
final String attributeName, final String attributeValue);
public void replaceAttribute(final AttributeName oldAttributeName,
final String attributeName, final String attributeValue,
final AttributeValueQuotes attributeValueQuotes);
public void removeAttribute(final String attributeName);
public void removeAttribute(final String prefix, final String name);
public void removeAttribute(final AttributeName attributeName);
public void setSelectionTarget(final Object selectionTarget);
public void setInliner(final IInliner inliner);
public void setTemplateData(final TemplateData templateData);
public void setBody(final String text, final boolean processable);
public void setBody(final IModel model, final boolean processable);
public void insertBefore(final IModel model); // cannot be processable
public void insertImmediatelyAfter(final IModel model, final boolean processable);
public void replaceWith(final String text, final boolean processable);
public void replaceWith(final IModel model, final boolean processable);
public void removeElement();
public void removeTags();
public void removeBody();
public void removeAllButFirstChild();
public void iterateElement(final String iterVariableName,
final String iterStatusVariableName,
final Object iteratedObject);
}在这里我们可以看到处理器可以要求模板引擎在其执行后执行的所有操作。方法名已经具备良好的自解释性(也有对应的 Javadoc),但简要说明如下:
setLocalVariable(...)/removeLocalVariable(...)将为模板执行添加一个局部变量。这个局部变量将在当前事件执行的剩余时间内可用,并且对其所有内容(即直到相应的关闭标签)setAttribute(...)会向标签中添加一个具有指定值的新属性(可能还包括引号类型)。如果该属性已存在,则其值将被替换。replaceAttribute(...)用一个新的属性替换现有属性,包括空格环绕等原有位置信息。removeAttribute(...)从标签中移除一个属性。setSelectionTarget(...)修改被认为是选择目标。的对象,也就是选择表达式 (*{...}将在其上执行的对象。在标准方言中,这个选择目标。通常通过th:object属性进行修改,但自定义处理器也可以做到这一点。注意选择目标。和局部变量的作用域相同,因此只能在被处理元素的内容中访问。setInliner(...)修改用于处理元素内容中出现的所有文本节点(内联处理器。这是IText事件)的th:inline属性用来启用内联的机制,可在任意指定的模式下(如text,javascript等)生效。setTemplateData(...)修改当前正在处理的模板的元数据。插入片段时,这使引擎能够知道正在处理的特定片段的数据以及嵌套的所有片段完整堆栈。setBody(...)用提供的文本或模型(事件序列=标记片段)替换正在处理的元素的整个内容。例如,th:text/th:utext就是这样工作的。请注意,指定的替换文本或模型可以设置为可处理的或不可处理的,具体取决于我们是否希望执行可能与它们相关联的任何处理器。例如,在th:utext="${var}"的情况下,替换被设置为不可处理的,以避免执行任何可能由${var}返回的作为模板一部分的标记。insertBefore(...)/insertImmediatelyAfter(...)允许指定一个模型(标记片段),该模型应该出现在被处理标签之前或紧接在被处理标签之后。请注意,insertImmediatelyAfter表示在被处理的标签之后(因此是元素内容的第一部分),而不是整个在此处开始并在某处闭标签结束的元素之后。.replaceWith(...)允许当前。元素(element)(整个元素)被作为参数指定的文本或模型替换。removeElement()/removeTags()/removeBody()/removeAllButFirstChild()允许处理器分别移除整个元素(包括其主体)、仅执行标签(开始+结束标签)但不包括主体、仅主体但不包括包裹的标签,以及最后是该标签的所有子元素,除了第一个子元素。请注意,所有这些选项基本上反映的是可以在。th:remove属性iterateElement(...)允许当前元素(包括其主体)根据中存在的元素数量进行相应次数的迭代。iteratedObject(这通常是一个。Collection,Map,Iterator或者一个数组)。另外两个参数将用于指定用于迭代元素和状态变量的变量名称。
抽象实现。IElementTagProcessor
Thymeleaf 提供了两种基本的实现方式。IElementTagProcessor处理器可能为了方便而实现它们:
org.thymeleaf.processor.element.AbstractElementTagProcessor,用于通过元素名称匹配元素事件的处理器(即不查看属性)。org.thymeleaf.processor.element.AbstractAttributeTagProcessor,用于通过其中一个属性(以及可选的元素名称)匹配元素事件的处理器。
元素模型处理器:IElementModelProcessor
元素模型处理器以包含整个匹配元素及其内容序列的。IModel对象的形式对它们匹配的整个元素(包括主体)执行操作。该。IElementModelProcessor接口与上述。标签处理器。:
public interface IElementModelProcessor extends IElementProcessor {
public void process(
final ITemplateContext context,
final IModel model,
final IElementModelStructureHandler structureHandler);
}注意此接口同样扩展了。IElementProcessor,以及其中的。process(...)方法结构与标签处理器中的方法相同,当然替换了。tag元素model参数:
process(...)返回。void。动作将在。model或structureHandler上执行,而不是通过返回值。context包含执行上下文:变量等。model是建模处理器所作用的整个元素的事件序列。这个模型可以从处理器直接修改。structureHandler允许指示引擎执行除模型修改之外的操作(例如设置局部变量)。
读取和修改模型。
这个IModel传递给。process()方法的。对象是一个。可变模型,因此允许对其进行任何修改(。模型是可变的,事件如。标签。则是不可变的)。例如,我们可能希望对其进行修改,使主体中的每个文本节点都替换为具有相同内容的注释:
final IModelFactory modelFactory = context.getModelFactory();
int n = model.size();
while (n-- != 0) {
final ITemplateEvent event = model.get(n);
if (event instanceof IText) {
final IComment comment =
modelFactory.createComment(((IText)event).getText());
model.insert(n, comment);
model.remove(n + 1);
}
}同样需要注意的是。IModel接口中包含了一个。accept(IModelVisitor visitor)方法,使用。访问者。模式遍历整个模型以查找特定节点或相关数据非常有用。
使用。structureHandler
类似于。标签处理器。,模型处理器也接收一个。结构处理器。对象,它允许它们指示引擎执行无法通过对对象本身操作完成的其他动作。该结构处理器接口比标签处理器的小得多,它是。IModel model object itself. The interface these structure handlers implement, much smaller than the one for tag processors, is IElementModelStructureHandler:
public interface IElementModelStructureHandler {
public void reset();
public void setLocalVariable(final String name, final Object value);
public void removeLocalVariable(final String name);
public void setSelectionTarget(final Object selectionTarget);
public void setInliner(final IInliner inliner);
public void setTemplateData(final TemplateData templateData);
}很容易看出这是标签处理器接口的一个子集。其中的少数方法工作方式相同:
setLocalVariable(...)/removeLocalVariable(...)用于添加/删除在模型执行期间(当前处理器执行后)可用的局部变量。setSelectionTarget(...)用于修改模型执行期间应用的。选择目标。。setInliner(...)用于设置内联器。setTemplateData(...)用于设置关于正在处理的模板的元数据。
抽象实现。IElementModelProcessor
Thymeleaf 提供了两种基本的实现方式。IElementModelProcessor处理器可能为了方便而实现它们:
org.thymeleaf.processor.element.AbstractElementModelProcessor,用于通过元素名称匹配元素事件的处理器(即不查看属性)。org.thymeleaf.processor.element.AbstractAttributeModelProcessor,用于通过其中一个属性(以及可选的元素名称)匹配元素事件的处理器。
模板开始/结束处理器:ITemplateBoundariesProcessor
模板边界处理器是一种处理器,在模板处理过程中触发的。模板开始。和模板结束。事件上执行。它们允许在模板处理操作的开始或结束时执行任何类型的初始化或资源释放。请注意,这些事件仅针对一级模板触发。only fired for the first-level template,而不会针对模板中解析和/或包含的各个片段触发。
这个ITemplateBoundariesProcessor接口如下所示:
public interface ITemplateBoundariesProcessor extends IProcessor {
public void processTemplateStart(
final ITemplateContext context,
final ITemplateStart templateStart,
final ITemplateBoundariesStructureHandler structureHandler);
public void processTemplateEnd(
final ITemplateContext context,
final ITemplateEnd templateEnd,
final ITemplateBoundariesStructureHandler structureHandler);
}此次的接口提供了两个。process*(...)方法,一个对应。模板开始。,另一个对应。模板结束。事件。它们的签名遵循与其他。process(...)方法相同的模式,接收上下文、事件对象和结构处理器。在这种情况下,结构处理器实现了一个相当简单的。ITemplateBoundariesStructureHandler接口:
public interface ITemplateBoundariesStructureHandler {
public void reset();
public void setLocalVariable(final String name, final Object value);
public void removeLocalVariable(final String name);
public void setSelectionTarget(final Object selectionTarget);
public void setInliner(final IInliner inliner);
public void insert(final String text, final boolean processable);
public void insert(final IModel model, final boolean processable);
}我们可以看到,除了通常用于管理局部变量、选择目标和内联器的方法之外,还可以使用结构处理器插入文本或模型,这将在结果的最开始或最末尾出现(取决于所处理的事件)。
其他处理器。
Thymeleaf 3.0 还允许声明用于处理其他事件的处理器,每个事件都实现其对应的接口:
- 文本。事件:接口。
ITextProcessor - 注释。事件:接口。
ICommentProcessor - CDATA 段。事件:接口。
ICDATASectionProcessor - DOCTYPE 子句。事件:接口。
IDocTypeProcessor - XML 声明。事件:接口。
IXMLDeclarationProcessor - 处理指令。事件:接口。
IProcessingInstructionProcessor
它们都看起来非常类似(以下是文本事件的接口):
public interface ITextProcessor extends IProcessor {
public void process(
final ITemplateContext context,
final IText text,
final ITextStructureHandler structureHandler);
}与其它。process(...)方法一样遵循相同的模式:上下文、事件、结构处理器。并且这些结构处理器也非常简单,就像这样(再次以文本事件为例):
public interface ITextStructureHandler {
public void reset();
public void setText(final CharSequence text);
public void replaceWith(final IModel model, final boolean processable);
public void removeText();
}3 创建我们自己的方言(Dialect)
本指南本章及后续章节中所示示例的源代码可以在以下位置找到extraThyme示例应用程序:
3.1. extraThyme:一个为提米兰德足球联赛服务的网站
足球在提米兰德是一项受欢迎的运动1每个赛季都会进行包含10支球队的比赛,其组织者刚刚要求我们为该赛事创建一个名为“extraThyme”的网站。
这个网站将非常简单:仅有一个表格,其中包括:
- 球队名称。
- 各队获胜、平局或失利的比赛场次,以及获得的总积分。
- 注释说明球队在积分榜中的位置是否使其有资格参加明年更高级别的比赛,或者意味着它降级到地区联赛。
在积分榜上方,横幅将会显示最近比赛结果的头条新闻,并且每个周日都会有一个显眼的横幅提醒用户,周日是比赛日,因此他们应该去体育场而不是浏览互联网。
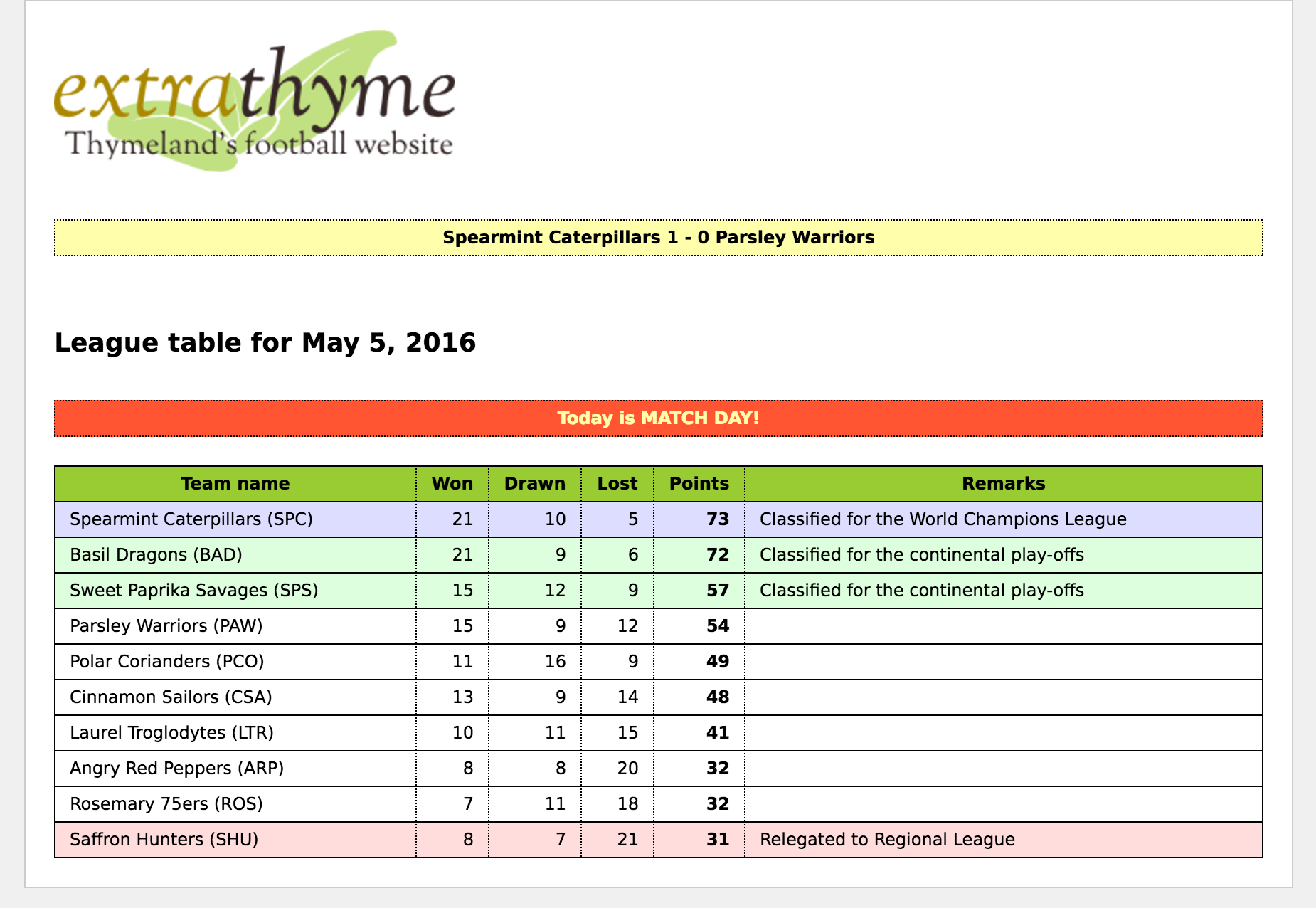
我们将使用 HTML5、Spring MVC 和 SpringStandard 方言来构建我们的应用程序,并且我们将通过创建一个扩展 Thymeleaf 的方言来扩展它:score包含以下内容的方言:
- A
score:remarkforposition属性,用于输出表格备注列中的国际化文本。该文本应说明球队在积分榜的位置是否使其有资格参加世界杯赛、洲际附加赛,或者降级到地区联赛。 - A
score:classforposition属性,根据球队备注信息为表格行建立 CSS 类:蓝色背景表示世界杯赛,绿色表示洲际附加赛,红色表示降级。 - A
score:headlines标签,用于绘制顶部黄色框并显示最近比赛的结果。此标签应支持 order 属性,值可以是 random(显示随机选择的一场比赛)和latest(默认值,仅显示最近一场比赛)。 - A
score:match-day-today属性,可以添加到积分榜表头,以便(在周日时有条件地)添加一个警告用户的横幅,提示今天是比赛日。
因此,我们的标记将如下所示,同时使用了th和score属性:
<!DOCTYPE html>
<!--/* Note the xmlns:* here are completely optional and only meant to */-->
<!--/* avoid IDEs from complaining about tags/attributes they may not know */-->
<html xmlns:th="http://www.thymeleaf.org" xmlns:score="http://thymeleafexamples">
<head>
<title>extraThyme: Thymeland's football website</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<link rel="stylesheet" type="text/css" media="all"
href="../../css/extrathyme.css" th:href="@{/css/extrathyme.css}"/>
</head>
<body>
<div>
<img src="../../images/extrathymelogo.png"
alt="extraThyme logo" title="extraThyme logo"
th:src="@{/images/extrathymelogo.png}" th:alt-title="#{title.application}"/>
</div>
<score:headlines order="random" />
<div class="leaguetable">
<h2 score:match-day-today th:text="#{title.leaguetable(${execInfo.now.time})}">
League table for 07 July 2011
</h2>
<table>
<thead>
<tr>
<th th:text="#{team.name}">Team</th>
<th th:text="#{team.won}" class="matches">Won</th>
<th th:text="#{team.drawn}" class="matches">Drawn</th>
<th th:text="#{team.lost}" class="matches">Lost</th>
<th th:text="#{team.points}" class="points">Points</th>
<th th:text="#{team.remarks}">Remarks</th>
</tr>
</thead>
<tbody>
<tr th:each="t : ${teams}" score:classforposition="${tStat.count}">
<td th:text="|${t.name} (${t.code})|">The Winners (TWN)</td>
<td th:text="${t.won}" class="matches">1</td>
<td th:text="${t.drawn}" class="matches">0</td>
<td th:text="${t.lost}" class="matches">0</td>
<td th:text="${t.points}" class="points">3</td>
<td score:remarkforposition="${tStat.count}">Great winner!</td>
</tr>
<!--/*-->
<tr>
<td>The First Losers (TFL)</td>
<td class="matches">0</td>
<td class="matches">1</td>
<td class="matches">0</td>
<td class="points">1</td>
<td>Little loser!</td>
</tr>
<tr>
<td>The Last Losers (TLL)</td>
<td class="matches">0</td>
<td class="matches">0</td>
<td class="matches">1</td>
<td class="points">0</td>
<td>Big loooooser</td>
</tr>
<!--*/-->
</tbody>
</table>
</div>
</body>
</html>(请注意,我们在表格中添加了第二行和第三行,并用解析器级别的注释包围它们,<!--/* ... */-->以便在浏览器中直接打开模板时也能良好显示原型。)
3.2. 根据球队排名更改CSS类
我们将开发的第一个属性处理器是ClassForPositionAttributeTagProcessor,我们将其实现为 Thymeleaf 提供的一个便捷抽象类的子类:AbstractAttributeTagProcessor.
此抽象类是所有标签处理器的基础(即作用于标签事件而非模型),这些处理器基于标签中是否存在特定属性而被匹配(即被选中执行)。在此案例中,score:classforposition.
其思路是我们将使用这个处理器来设置该标签所处标签的class属性的新值。score:classforposition所在标签的
让我们看一下我们的代码:
public class ClassForPositionAttributeTagProcessor extends AbstractAttributeTagProcessor {
private static final String ATTR_NAME = "classforposition";
private static final int PRECEDENCE = 10000;
public ClassForPositionAttributeTagProcessor(final String dialectPrefix) {
super(
TemplateMode.HTML, // This processor will apply only to HTML mode
dialectPrefix, // Prefix to be applied to name for matching
null, // No tag name: match any tag name
false, // No prefix to be applied to tag name
ATTR_NAME, // Name of the attribute that will be matched
true, // Apply dialect prefix to attribute name
PRECEDENCE, // Precedence (inside dialect's own precedence)
true); // Remove the matched attribute afterwards
}
@Override
protected void doProcess(
final ITemplateContext context, final IProcessableElementTag tag,
final AttributeName attributeName, final String attributeValue,
final IElementTagStructureHandler structureHandler) {
final IEngineConfiguration configuration = context.getConfiguration();
/*
* Obtain the Thymeleaf Standard Expression parser
*/
final IStandardExpressionParser parser =
StandardExpressions.getExpressionParser(configuration);
/*
* Parse the attribute value as a Thymeleaf Standard Expression
*/
final IStandardExpression expression = parser.parseExpression(context, attributeValue);
/*
* Execute the expression just parsed
*/
final Integer position = (Integer) expression.execute(context);
/*
* Obtain the remark corresponding to this position in the league table.
*/
final Remark remark = RemarkUtil.getRemarkForPosition(position);
/*
* Select the adequate CSS class for the element.
*/
final String newValue;
if (remark == Remark.WORLD_CHAMPIONS_LEAGUE) {
newValue = "wcl";
} else if (remark == Remark.CONTINENTAL_PLAYOFFS) {
newValue = "cpo";
} else if (remark == Remark.RELEGATION) {
newValue = "rel";
} else {
newValue = null;
}
/*
* Set the new value into the 'class' attribute (maybe appending to an existing value)
*/
if (newValue != null) {
String currentClass = tag.getAttribute("class").getValue();
if (currentClass != null) {
structureHandler.setAttribute("class", currentClass + " " + newValue);
} else {
structureHandler.setAttribute("class", newValue);
}
}
}
}基本的逻辑流程很容易理解:获取属性的值,使用它进行所需计算,最后使用structureHandler来指示引擎需要进行哪些修改。
需要注意的是,我们正在创建该属性以执行标准语法编写的表达式(由标准和SpringStandard方言使用)。也就是说,能够设置类似${var}, #{messageKey}的值、条件语句等。请看我们在模板中如何使用它:
<tr th:each="t : ${teams}" score:classforposition="${tStat.count}">为了评估这些表达式(也称为Thymeleaf 标准表达式),我们需要首先获取标准表达式解析器,然后解析属性值,最后执行解析后的表达式:
final IStandardExpressionParser parser =
StandardExpressions.getExpressionParser(configuration);
final IStandardExpression expression = parser.parseExpression(context, attributeValue);
final Integer position = (Integer) expression.execute(context);使用structureHandler向主标签添加新属性的方式也很有趣(记住tag对象是不可变的):
if (newValue != null) {
String currentClass = tag.getAttribute("class").getValue();
if (currentClass != null) {
structureHandler.setAttribute("class", currentClass + " " + newValue);
} else {
structureHandler.setAttribute("class", newValue);
}
}最后请注意,对文本和属性进行HTML转义是我们的责任,,但在这种情况下,我们知道变量的所有可能值且不需要转义,所以为了简化操作我们跳过了转义步骤。newValue variable and they require no escaping, so for the sake of simplicity we are skipping that operation.
3.3. 显示国际化备注
接下来要做的是创建一个能够显示备注文本的属性处理器。这将与ClassForPositionAttrProcessor非常相似,但有以下几个重要区别:
- 我们不会为主标签中的属性设置值,而是设置标签的文本主体(内容),就像使用
th:text属性那样。 - 我们需要从代码中访问消息外部化(国际化)系统,以便可以显示对应所选地区的文本。
我们将使用相同的AbstractAttributeTagProcessor基类。这是我们的代码:
public class RemarkForPositionAttributeTagProcessor extends AbstractAttributeTagProcessor {
private static final String ATTR_NAME = "remarkforposition";
private static final int PRECEDENCE = 12000;
public RemarkForPositionAttributeTagProcessor(final String dialectPrefix) {
super(
TemplateMode.HTML, // This processor will apply only to HTML mode
dialectPrefix, // Prefix to be applied to name for matching
null, // No tag name: match any tag name
false, // No prefix to be applied to tag name
ATTR_NAME, // Name of the attribute that will be matched
true, // Apply dialect prefix to attribute name
PRECEDENCE, // Precedence (inside dialect's precedence)
true); // Remove the matched attribute afterwards
}
@Override
protected void doProcess(
final ITemplateContext context, final IProcessableElementTag tag,
final AttributeName attributeName, final String attributeValue,
final IElementTagStructureHandler structureHandler) {
final IEngineConfiguration configuration = context.getConfiguration();
/*
* Obtain the Thymeleaf Standard Expression parser
*/
final IStandardExpressionParser parser =
StandardExpressions.getExpressionParser(configuration);
/*
* Parse the attribute value as a Thymeleaf Standard Expression
*/
final IStandardExpression expression =
parser.parseExpression(context, attributeValue);
/*
* Execute the expression just parsed
*/
final Integer position = (Integer) expression.execute(context);
/*
* Obtain the remark corresponding to this position in the league table
*/
final Remark remark = RemarkUtil.getRemarkForPosition(position);
/*
* If no remark is to be applied, just set an empty body to this tag
*/
if (remark == null) {
structureHandler.setBody("", false); // false == 'non-processable'
return;
}
/*
* Message should be internationalized, so we ask the engine to resolve
* the message 'remarks.{REMARK}' (e.g. 'remarks.RELEGATION'). No
* parameters are needed for this message.
*
* Also, we will specify to "use absent representation" so that, if this
* message entry didn't exist in our resource bundles, an absent-message
* label will be shown.
*/
final String i18nMessage =
context.getMessage(
RemarkForPositionAttributeTagProcessor.class,
"remarks." + remark.toString(),
new Object[0],
true);
/*
* Set the computed message as the body of the tag, HTML-escaped and
* non-processable (hence the 'false' argument)
*/
structureHandler.setBody(HtmlEscape.escapeHtml5(i18nMessage), false);
}
}访问国际化消息
请注意,我们是通过以下方式访问消息外部化系统的:
final String i18nMessage =
context.getMessage(
RemarkForPositionAttributeTagProcessor.class,
"remarks." + remark.toString(),
new Object[0],
true);这将调用引擎中配置的消息解析机制,不仅会传递我们感兴趣的特定键及其参数(在这种情况下无参数),还会传递两个其他信息:
- 这个起源分配给消息的信息:
RemarkForPositionAttributeTagProcessor.class - 是否应使用缺失消息表示应使用的策略(
true)
消息解析是一个可扩展点在 Thymeleaf 中 (IMessageResolver接口),因此这些参数的处理方式取决于正在使用的具体实现。非Spring应用中的默认实现在启用Spring的应用程序中有所不同。StandardMessageResolver) 将执行以下操作:
- 首先查找与模板文件同名且加上区域设置的文件。因此,如果模板是
.properties,区域设置是/views/main.html,则会查找gl_ES文件,然后查找/views/main_gl_ES.properties,接着查找/views/main_gl.properties,最后查找/views/main.properties. - 如果没有找到,则使用起源),并在类路径中查找那里指定的类名对应的文件(即处理器本身的类):
null) and look for.properties等等。这允许将classpath:org/thymeleaf/examples/spring6/extrathyme/dialects/score/RemarkForPositionAttributeTagProcessor_gl_ES.properties或带有其完整i18n资源包的处理器和方言放在普通的组件化文件中。.jarfiles. - 如果这些都没有找到,请查看缺失消息表示。如果
false类(这个类可能已经被指定null则直接返回true,则创建某种文本,使开发者或用户能够快速识别缺少i18n资源的情况:??remarks.rel_gl_ES??.
(请注意,在启用了Spring的应用程序中,默认情况下此消息解析机制将被Spring自己的机制替代,基于Spring应用上下文中声明的MessageSourcebean。)
HTML转义内容
此外,在此处理器中,我们通过使用来自HtmlEscape类来进行所需的内容HTML转义,该类属于Unbescape库,并在Thymeleaf中广泛用于此目的:
structureHandler.setBody(HtmlEscape.escapeHtml5(i18nMessage), false);3.4. 我们的头条元素处理器
,以区别于前两个处理器,它们是元素标签处理器。原因是,在这种情况下,我们希望我们的处理器根据标签的名称进行匹配(即选择执行),而不是根据其某个属性的名称。属性标签处理器. The reason is, in this case we want our processor to match (i.e. to be selected for execution) based on the 这种类型的标签处理器相较于属性标签处理器具有一个优势和一个劣势:, not on the name of one of its attributes.
This kind of tag processor has one advantage and also one disadvantage with respect to attribute tag processors:
- 优势:元素可以包含多个属性,因此你的元素处理器可以接收到更丰富、更复杂的配置参数。
- 劣势:自定义元素/标签对浏览器来说是未知的,因此如果你正在开发一个使用自定义标签的Web应用程序,你可能不得不牺牲Thymeleaf最有趣的特性之一:静态显示模板作为原型的能力(自然模板化)。
此处理器将扩展AbstractElementTagProcessor,这是用于不基于特定属性匹配的标签处理器的基类:
public class HeadlinesElementTagProcessor extends AbstractElementTagProcessor {
private static final String TAG_NAME = "headlines";
private static final int PRECEDENCE = 1000;
private final Random rand = new Random(System.currentTimeMillis());
public HeadlinesElementTagProcessor(final String dialectPrefix) {
super(
TemplateMode.HTML, // This processor will apply only to HTML mode
dialectPrefix, // Prefix to be applied to name for matching
TAG_NAME, // Tag name: match specifically this tag
true, // Apply dialect prefix to tag name
null, // No attribute name: will match by tag name
false, // No prefix to be applied to attribute name
PRECEDENCE); // Precedence (inside dialect's own precedence)
}
@Override
protected void doProcess(
final ITemplateContext context, final IProcessableElementTag tag,
final IElementTagStructureHandler structureHandler) {
/*
* Obtain the Spring application context.
*/
final ApplicationContext appCtx = SpringContextUtils.getApplicationContext(context);
/*
* Obtain the HeadlineRepository bean from the application context, and ask
* it for the current list of headlines.
*/
final HeadlineRepository headlineRepository = appCtx.getBean(HeadlineRepository.class);
final List<Headline> headlines = headlineRepository.findAllHeadlines();
/*
* Read the 'order' attribute from the tag. This optional attribute in our tag
* will allow us to determine whether we want to show a random headline or
* only the latest one ('latest' is default).
*/
final String order = tag.getAttributeValue("order");
String headlineText = null;
if (order != null && order.trim().toLowerCase().equals("random")) {
// Order is random
final int r = this.rand.nextInt(headlines.size());
headlineText = headlines.get(r).getText();
} else {
// Order is "latest", only the latest headline will be shown
Collections.sort(headlines);
headlineText = headlines.get(headlines.size() - 1).getText();
}
/*
* Create the DOM structure that will be substituting our custom tag.
* The headline will be shown inside a '<div>' tag, and so this must
* be created first and then a Text node must be added to it.
*/
final IModelFactory modelFactory = context.getModelFactory();
final IModel model = modelFactory.createModel();
model.add(modelFactory.createOpenElementTag("div", "class", "headlines"));
model.add(modelFactory.createText(HtmlEscape.escapeHtml5(headlineText)));
model.add(modelFactory.createCloseElementTag("div"));
/*
* Instruct the engine to replace this entire element with the specified model.
*/
structureHandler.replaceWith(model, false);
}
}上述代码中第一个有趣的部分展示了如何访问Spring的ApplicationContext以从中获取其中一个bean(即HeadlineRepository):
final ApplicationContext appCtx = SpringContextUtils.getApplicationContext(context);此外,此处理器与之前的处理器不同之处在于,我们需要创建标记作为其执行的结果:我们将用<score:headlines .../>片段替换原始<div>...</div>标签,因此需要使用到模型工厂.
模型工厂
模型工厂是一个特殊的对象,可供处理器(以及诸如预处理器、后处理器等其他结构)使用,它可以创建新的事件实例作为模型(模板的片段),还可以创建新的模型实例本身。
因此,这是创建新标记的工具,就像我们在上面代码中看到的那样:
final IModelFactory modelFactory = context.getModelFactory();
final IModel model = modelFactory.createModel();
model.add(modelFactory.createOpenElementTag("div", "class", "headlines"));
model.add(modelFactory.createText(HtmlEscape.escapeHtml5(headlineText)));
model.add(modelFactory.createCloseElementTag("div"));注意标记事件必须一次创建一个事件,并且同一个div元素的开始和结束标签必须分别按正确顺序创建。这是因为模型是事件序列而不是文档对象模型(DOM)中的节点。
模型工厂提供了相当完整的方法集来创建所有类型的事件:标签、文本、DOCTYPE等,还提供了一些有用的用于修改标签属性的方法(通过创建一个新的tag实例,因为它们是不可变的),例如:
final IOpenElemenTag newTag = modelFactory.setAttribute(tag, "class", "newvalue");此外,模型工厂还能从头开始创建IModel实例(如上述的modelFactory.createModel()),可以从单个现有事件创建,也可以通过解析一段我们想要转换为其对应事件序列的标记来创建:
final IModel model =
modelFactory.parse(
context.getTemplateData(),
"<div class='headlines'>Some headlines</div>");3.5. 我们的“今日比赛日”横幅模型处理器
我们将在方言中包含的最后一个处理器与迄今为止所见到的处理器截然不同:它是一个模型处理器,而不是一个标签处理器.
如前所述,模型处理器不在特定的标签事件上执行,而是在包含其匹配元素的整个事件序列(即模型)上执行。
所以如果我们有一个匹配<p>带有属性score:matcher的模型处理器,并且有一个模板片段如下:
<p score:matcher="whatever">
This is some body
</p>那么这个模型处理器会将其doProcess()方法的参数接收为一个IModel包含3个事件:<p score:matcher="whatever">(开始标签)、\n This is some body\n(文本)和</p>(结束标签)。
回到我们的需求:我们想要一个匹配scrore:match-day-today的模型处理器,我们可以将其应用于联赛表标题,并让它在该标题下方显示一个警告用户星期天是比赛日的横幅:
<h2 score:match-day-today th:text="#{title.leaguetable(${execInfo.now.time})}">
League table for 07 July 2011
</h2>注意我们不需要此score:match-day-today属性的值,因此我们可以直接忽略它。我们的代码看起来像这样:
public class MatchDayTodayModelProcessor extends AbstractAttributeModelProcessor {
private static final String ATTR_NAME = "match-day-today";
private static final int PRECEDENCE = 100;
public MatchDayTodayModelProcessor(final String dialectPrefix) {
super(
TemplateMode.HTML, // This processor will apply only to HTML mode
dialectPrefix, // Prefix to be applied to name for matching
null, // No tag name: match any tag name
false, // No prefix to be applied to tag name
ATTR_NAME, // Name of the attribute that will be matched
true, // Apply dialect prefix to attribute name
PRECEDENCE, // Precedence (inside dialect's own precedence)
true); // Remove the matched attribute afterwards
}
protected void doProcess(
final ITemplateContext context, final IModel model,
final AttributeName attributeName, final String attributeValue,
final IElementModelStructureHandler structureHandler) {
if (!checkPositionInMarkup(context)) {
throw new TemplateProcessingException(
"The " + ATTR_NAME + " attribute can only be used inside a " +
"markup element with class \"leaguetable\"");
}
final Calendar now = Calendar.getInstance(context.getLocale());
final int dayOfWeek = now.get(Calendar.DAY_OF_WEEK);
// Sundays are Match Days!!
if (dayOfWeek == Calendar.SUNDAY) {
// The Model Factory will allow us to create new events
final IModelFactory modelFactory = context.getModelFactory();
// We will be adding the "Today is Match Day" banner just after
// the element we are processing for:
//
// <h4 class="matchday">Today is MATCH DAY!</h4>
//
model.add(modelFactory.createOpenElementTag("h4", "class", "matchday")); //
model.add(modelFactory.createText("Today is MATCH DAY!"));
model.add(modelFactory.createCloseElementTag("h4"));
}
}
private static boolean checkPositionInMarkup(final ITemplateContext context) {
/*
* We want to make sure this processor is being applied inside a container tag which has
* class="leaguetable". So we need to check the second-to-last entry in the element stack
* (the last entry is the tag being processed itself).
*/
final List<IProcessableElementTag> elementStack = context.getElementStack();
if (elementStack.size() < 2) {
return false;
}
final IProcessableElementTag container = elementStack.get(elementStack.size() - 2);
if (!(container instanceof IOpenElementTag)) {
return false;
}
final String classValue = container.getAttributeValue("class");
return classValue != null && classValue.equals("leaguetable");
}
}首先要注意的是,我们在检查该属性使用的上下文位置:我们只允许它出现在具有class="leaguetable"的容器内。因此我们的checkPositionInMarkup(...)方法使用了元素栈来了解处理当前元素所需的标签列表。
另外,关于如何创建新的横幅元素(一个<h4>),请注意我们所做的正是修改传递给model的属性doProcess(...)。没有创建新的模型对象:
final IModelFactory modelFactory = context.getModelFactory();
model.add(modelFactory.createOpenElementTag("h4", "class", "matchday")); //
model.add(modelFactory.createText("Today is MATCH DAY!"));
model.add(modelFactory.createCloseElementTag("h4"));3.6. 声明全部:方言
当然,完成我们的方言所需的最后一步就是方言类本身。
正如在前面的章节中所看到的,方言可能会根据其提供给模板引擎的内容实现不同的接口。在这种情况下,我们的方言仅提供处理器,因此它将实现IProcessorDialect.
事实上,我们将扩展一个抽象的便捷实现类,该类将简化接口的实现:AbstractProcessorDialect:
public class ScoreDialect extends AbstractProcessorDialect {
private static final String DIALECT_NAME = "Score Dialect";
public ScoreDialect() {
// We will set this dialect the same "dialect processor" precedence as
// the Standard Dialect, so that processor executions can interleave.
super(DIALECT_NAME, "score", StandardDialect.PROCESSOR_PRECEDENCE);
}
/*
* Two attribute processors are declared: 'classforposition' and
* 'remarkforposition'. Also one element processor: the 'headlines'
* tag.
*/
public Set<IProcessor> getProcessors(final String dialectPrefix) {
final Set<IProcessor> processors = new HashSet<IProcessor>();
processors.add(new ClassForPositionAttributeTagProcessor(dialectPrefix));
processors.add(new RemarkForPositionAttributeTagProcessor(dialectPrefix));
processors.add(new HeadlinesElementTagProcessor(dialectPrefix));
processors.add(new MatchDayTodayModelProcessor(dialectPrefix));
// This will remove the xmlns:score attributes we might add for IDE validation
processors.add(new StandardXmlNsTagProcessor(TemplateMode.HTML, dialectPrefix));
return processors;
}
}一旦我们的方言创建完成,我们需要将其添加到模板引擎对象中才能使用它。由于这是一个启用 Spring 的应用程序,我们将修改已声明的模板引擎 Bean:
@Bean
public SpringTemplateEngine templateEngine(){
SpringTemplateEngine templateEngine = new SpringTemplateEngine();
templateEngine.setTemplateResolver(templateResolver());
templateEngine.addDialect(new ScoreDialect());
return templateEngine;
}请注意,addDialect(...)调用将在默认配置的基础上添加 Score DialectSpringTemplateEngine:由 SpringStandard 方言提供。
就这样!我们的方言现在已经准备就绪,我们的联赛积分榜将以我们想要的方式显示。
当然是欧洲足球 ;-)↩